
Data Governance Guide
Overview
Traditionally, data governance was handled at the application level and its purpose was to make sure the application had high-quality data and could support regulatory compliance. Broader issues, like making the data available for use beyond what the application was originally used for, were not common drivers for data governance initiatives. This was primarily the case in highly regulated markets like finance and healthcare. Gradually, the goal of data governance has shifted from a controlling function to answer regulators to a key lever to increase the value of information and allow the enterprise to capture knowledge from its data.
Today, data governance is not only about rules—it’s about keeping your enterprise data current and fit to run the organization . It provides a framework for how data is stored, used and shared to empower users to be successful in their roles.
What Is Data Governance?
Data governance is the strategy that outlines how data and metadata are managed over their lifecycle.
Gartner defines data governance as “the specification of decision rights and an accountability framework to ensure the appropriate behavior in the valuation, creation, consumption and control of data and analytics.” A simpler definition of data governance would be the application of policy to your data, including privacy, security, compliance and quality policies.
Data governance helps align your enterprise data with data and interoperability standards, business definitions and data integrity expectations. It also helps everyone in your organization to know what data you have, understand what it means and use it effectively.
Why Is Data Governance Important?
Data governance helps organizations tackle many of the following questions:
- How do you secure the data?
- Is the underlying data biased?
- Can you ethically and legally use the data for your intended use case?
- Can you process the data in a timely and cost-appropriate manner?
- Is the data clean? (probably not in which case…) Can you clean the data?
- Does the data drift over time?
The role of data governance is to make data high-fidelity, reliable and available to users who need accurate information to drive business outcomes or provide essential public services to people.
This allows data engineers, data scientists, data analysts, compliance experts and knowledge workers to find relevant data, understand its schema and know how it was collected, how and where it was used and whether they can trust it.
Data governance is also needed to reconcile data silos and minimize their cost, as it defines a clear procedure on for how to share data across different departments. Having all the data in your enterprise use the same processes for creation and distribution and share common metadata rules is imperative for trusting your data. This makes data governance a critical component in fact-based analytics, supporting decision-making and artificial intelligence projects.
This allows data engineers, data scientists, data analysts, compliance experts and knowledge workers to find relevant data, understand its schema and know how it was collected, how and where it was used and whether they could can trust it.
When building enterprise-level GenAI projects, data governance—alongside a robust data and metadata management strategy—is critical to getting the best answers possible while protecting the company’s IP and customer privacy. If you make enterprise or sensitive data freely available to your AI system, it will provide it to anyone who asks about it. To avoid this, you need a data governance approach in which information security is built into the policy rules and automated by the technology access controls so everyone, including the GenAI application, has access only to the information they are allowed to see.
That’s why you need a data platform with the right security tools to apply your governance policies—and, to some extent, automate them.
Data Governance Framework
Data governance covers ethics, risk, trust, employee training and a lot more. Most frameworks are defined by three foundational components : people, processes and policies. Internal enterprise policies will be complemented by international data and regulatory compliance standards. We’d like to consider technology and data architecture as essential elements within a data governance framework as well since the effective implementation of your data governance framework will always have interplay with your data architecture and platform choices.
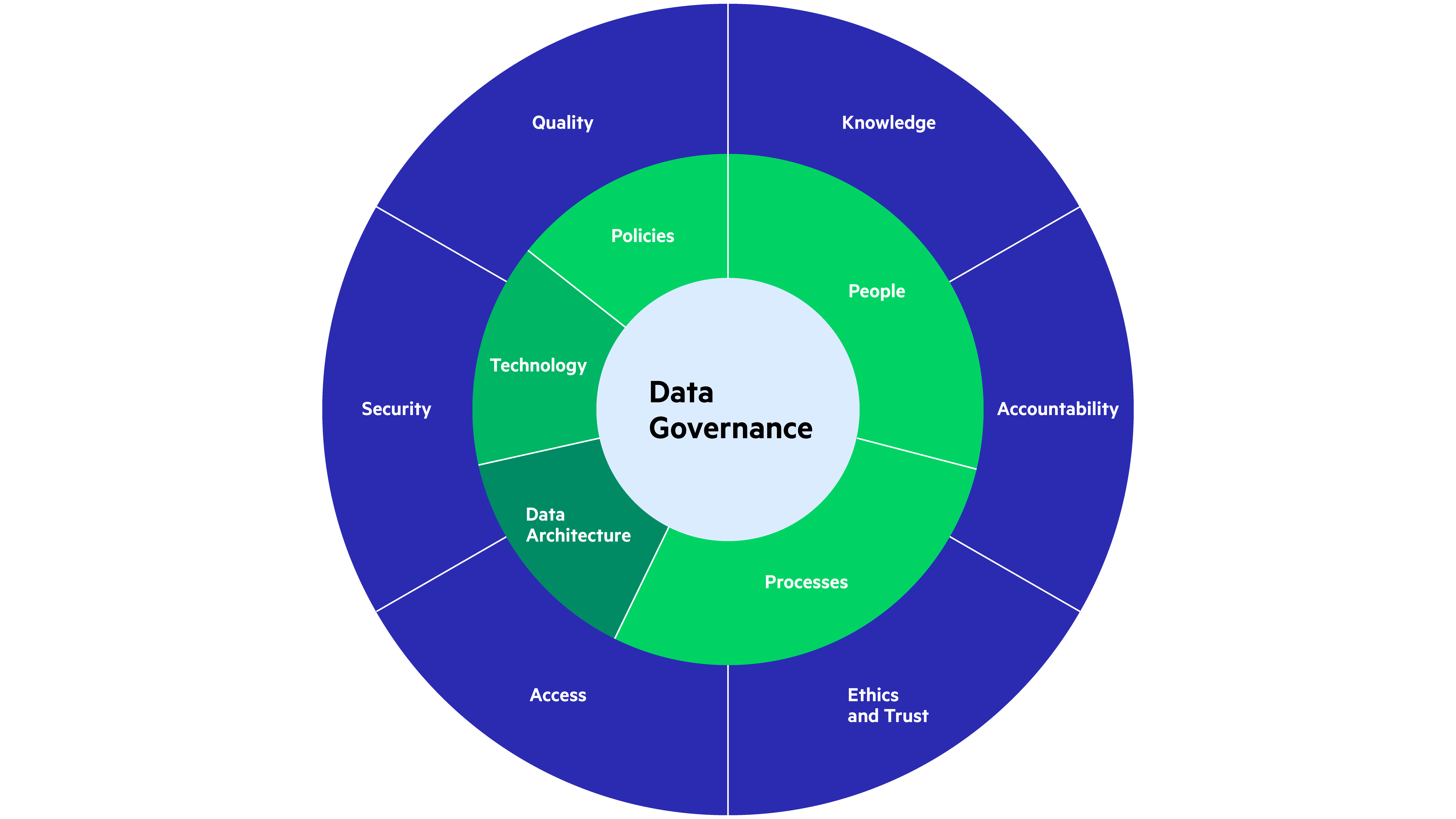
Challenges and Key Elements of Data Governance
Data may exist in disparate sources—including relational databases, file systems, operational systems, company websites and many other locations—and different incongruent formats, like documents and pdf files, relational sheets and geospatial coordinates. This makes data hard to understand, combine and query as a single whole.
Much of a company’s data was created for a specific purpose and was not formatted or linked to other data in a way that allows it to be used in other use cases. When data changes in the primary source those changes are often not propagated to copies of the data. As data is moved it is often transformed and enriched in ways that can make data inconsistent throughout the organization. Any silo can compromise the security of the entire data infrastructure.
Data governance helps answer questions like:
- When is it valid to use data from a specific source?
- How can constantly changing data be managed?
- How can data be harmonized and built into golden records?
- What’s the best way to allow access while respecting privacy concerns?
Given these challenges, data governance enables three goals—data validity, data protection and data access. Let’s take a quick look at each of these and then dive deeper into all three.
Data Validity
Data validity is far more than having technically “accurate” values. Even if a data element is accurate for the use for which it was created, it may still be invalid to use it in other situations. Things that can make data that was valid in their original use case invalid include lack of context, lack of data lineage and lack of completeness.
Data validity will primarily influence the quality of your data, integrating various data formats, data types and data currency, giving you the confidence to trust decisions based on that data.
Data Protection
Data protection consists of three elements: security, privacy and auditing.
Much of the data is sensitive and needs to be easily secured.
Many regulatory bodies require compliance reporting and auditing based on data lineage and data provenance. There are compliance use cases where it is important to understand when users change or even look at data. Keeping track of failed logins is essential to spotting attempted security breaches.
Data Access
Another major objective of data governance is to facilitate securely personalized access to information across the enterprise. The importance of bringing data close to the people who need it to perform their jobs or day-to-day tasks cannot be overstated. These include self-service analytics, delivering public services or mission-critical intelligence.
Overall, employees lose almost a full workday each week trying to track down information. This is largely due to the amount of disparate knowledge sources and applications they need to sift through. Not only is this excessive and inefficient search frustrating but making decisions based on subsets of data can lead to bad choices. Another report from Gartner found that one-third of knowledge workers admit to making an erroneous decision at work because of a lack of awareness of important information. Helping employees conveniently access all the firm’s data as an integrated whole is a critical goal of data governance.
Benefits and Goals of Data Governance
Data governance offers several key benefits that can significantly enhance an organization's data management and utilization. Here are some of the primary advantages:
- Improved Data Quality and Trustworthiness: Data governance facilitates the accuracy, consistency and reliability of data. By implementing policies and procedures for data management, organizations can maintain high-quality data that stakeholders can trust.
- Enhanced Risk Management and Compliance: With data governance, organizations can better protect sensitive information and maintain compliance with relevant regulations and standards. This includes implementing privacy, security and compliance policies to safeguard data.
- Better Decision-Making: By providing stakeholders access to accurate and relevant data, data governance empowers them to make informed decisions. This fosters collaboration across the organization and supports data-driven decision-making.
- Efficient Data Integration and Accessibility: Data governance facilitates the integration of various data sources, making it easier to access and share critical data across the organization. This can streamline operations and reduce the complexity and costs associated with data integration.
- Support for Innovation and Agility: A well-implemented data governance framework can balance secure and democratized data access with agile innovation. This allows organizations to adapt to changing business needs and leverage data for innovative solutions.
- Ethical and Responsible Data Use: Data governance promotes the responsible and ethical use of data, helping to build a culture of data excellence within the organization. This includes addressing questions related to data security, bias and ethical use.
These benefits collectively contribute to a more efficient, secure and innovative data environment, ultimately driving better business outcomes.
Data Governance Best Practices
An important part of modern data governance is balancing democratized access to data for information workers with sufficient control necessary for uniform security and data quality.
Providing traceability of data collected in the field or data from third-party sources can be extremely challenging. It is critical to model the bias and assumptions that data may contain so they are later considered and corrected in decision processes. This not only requires all the best data governance practices but also semantic and ontology modeling to capture the organization’s interpretation of the context. Deep enrichment and harmonization of the data are also necessary for tracking the entities and objects described in the data.
One question data and enterprise architects face: “centralized or decentralized architecture?” This is typically a choice tightly linked to the data architecture an organization will leverage. A choice between data fabric, data mesh or a hybrid approach that offers the best of both worlds to accommodate the specific needs of the organization.
- Centralize the Data to Apply Consistent Rules : Data needs to be presented as a single source of truth. This way you can apply your governance, security, quality and access policies as well as apply a consistent data model to all your data at both the creation and future management stages.
Traditional application-centric architectures constrain an organization’s ability to operationalize their data. Each application delivers value on its own. Then, along comes a new initiative that requires data from more applications, leading to a new integration and a new data silo.
Architects often implement either a bespoke DB and application or a packaged application. Unfortunately, packaged applications, especially at the departmental level, exacerbate the fragmentation effects across the organization by creating new data sets. New data sets are often created in isolation from other systems with their own schemas.
By linking together data from several of those application silos and joining them together with semantic and operational models, you can turn data into knowledge. This gives you the agility to quickly implement changes, such as new regulatory compliance rules or new pricing policies that will be true and consistent across the entire organization. - Distribute the Data Ownership: Most organizations tackle data projects as if they were IT projects, meaning they lack the domain expertise, skills and understanding of the overall data needs of the organization to be good stewards of the data. The key is empowering business users to own data governance.
Data can only be effectively leveraged if you understand it: its provenance and lineage, its bias, and more generally, the context of its creation, its distribution and its inclusion in a data set. People who know and use the data are typically best suited to apply rules to the data.
Data stewards play a critical role. Instead of each project team trying to interpret the app data in its own way and risking misinterpreting and only using partial information, the data stewards verify that the data held in an enterprise knowledge repository is—and remains—a true, accurate and traceable representation of the source data.
With proper federated stewardship and a reliable set of tools, we obtain reliable data and knowledge and minimize risks and costs. - Unify the Vocabulary : Enterprises use different database schemas, vocabularies, terms and nomenclatures,, so data ends up labelled differently across systems. For example, a customer identifier could look like Cust_id, cid, id or customer_identifier. When systems are different, you can’t easily automate the integration of data. Each application—home grown or packaged—has its own language to describe the data it acts on.
Combined with the first best practice we looked at, a harmonized and federated data corpus will help you control the quality and trustworthiness of intelligence through a shared vocabulary.
A unified vocabulary has two components: a data catalog and a business glossary. The data catalog defines the entities that are of interest to the organization and represents a logical model . The business glossary defines the concepts that are meaningful to the business and represents the conceptual model. While these are generally maintained by the business units themselves, they are unlikely to be socialized (even within a unit) and are rarely exploited by other applications or business processes. Conceptual Data Models set out the key entities of interest to your business, aligned with industry-specific standards such as ISO 21549 for health informatics and ISO 55001 for asset management.
But you also need a logical model and for that, you should create a common ontology to link and unify the vocabularies of individual silos.
How MarkLogic Supports Data Governance
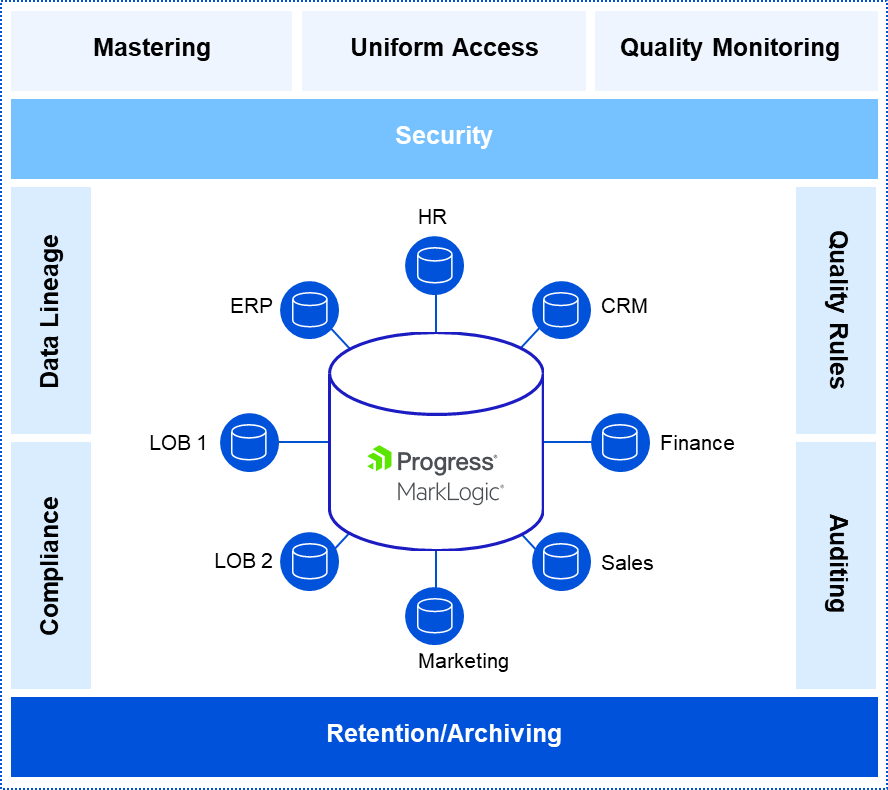
The MarkLogic multi-model database management platform, with its powerful document model and semantic graph capabilities, allows for strong data governance—combining data integration, security, lineage, auditing and easy data access in one platform. It enables you to manage the complete data lifecycle and keep track of its progression.
The implementation of data governance and regulation processes within an organization is simplified by the platform’s ability to integrate data and metadata in one database, incrementally build schemas while maintaining full access to unmodeled data and support semantic relationships.
MarkLogic also helps carry out policy execution together with operations. Policy is integrated at the database level instead of the application level, avoiding duplication, requiring less coding effort to implement and making it harder to bypass.
Data Security
Security starts with where the data is stored—in the database. MarkLogic is designed with that principle in mind and has features that help you protect private data to safely and collaboratively share it across the organization or deploy it in any cloud. This significantly simplifies the creation of a secure data infrastructure. In a blog post, we outlined how a data hub built on the MarkLogic platform supports your governance policy implementation from a data architecture, rules application and technology standpoint.
MarkLogic has granular access controls so you have full control over exactly what data is accessed, by whom and when. When you put your data in a MarkLogic Data Hub, different users have different views based on what they are allowed to see. A research scientist doing clinical analysis does not need full access to patient information. Analysts helping with regulatory compliance probably do not need to know the names and addresses of end customers.
With MarkLogic, you can write your application once and run it anywhere—in the cloud, in a hybrid environment or on-premises. It comes with advanced encryption that allows you to take advantage of a modern cloud architecture with less risk of having those who run the systems get access to your data.
Regulatory Compliance
MarkLogic also has audit trails so you can track lineage and provenance as metadata stored alongside the data, fostering data quality and availability and enabling you to apply governance rules and policies as needed.
Learn more about how Progress MarkLogic supports organizations in applying robust information security and governance practices.
Keep Reading




FAQ

Ready to Get Started?
See how MarkLogic simplifies complex data problems by delivering data agility.