
In the digital, data-rich business environment, businesses should have more than a basic understanding of their data and content. Data represents a powerful tool that can set businesses apart, but only if they successfully tap into its potential. From social media and customer reviews to emails and articles, textual data is ubiquitous and rich with insights waiting to be unearthed. With the rise of generative AI, businesses have started to pay closer attention to how they process and analyze their data.
Text analytics empower businesses to extract valuable insights from text. This blog offers a deep dive into how text analytics can power new business initiatives and applications for better decision making.
What Are Text Analytics?
Text analytics enable businesses to conquer information overload, extract valuable insights from information, add additional meaning to data and enable data-centric approaches to managing data. Text Analytics and text mining are often considered synonymous. That said, when reading about text mining you will notice mention of mathematics, pattern recognition and more—while text analytics is associated with auto-categorization, language and concepts. Text analytics enable businesses to turn the untapped potential of unstructured text into a powerful resource. This enables decision makers to fully utilize their current information for more informed decisions.
This is achieved with NLP-based semantic software and semantic knowledge models to analyze textual information. The purpose of text analytics is to transform unstructured text—the information overload every company deals with—into a powerful resource. This creates structured data from free text content and solves the problem of language ambiguity. When enterprises use a different vocabulary and data is labeled differently across systems, the automatic integration or analysis of data is impeded. Each application, homegrown or packaged, has its own language to describe the data it acts on.
The word “apple” presents a prime example of language ambiguity, encapsulating various meanings depending on the context and usage. At its core, the word “apple” refers to a type of fruit. However, beyond this fruit definition, it can evoke associations with technology, particularly the multinational electronics company. Additionally, “Apple” can refer to the daughter of Gwyneth Paltrow.
The diverse nature of language and meaning creates a barrier to leveraging the value of information and highlights the importance of context in accurate interpretation.
Text analytics play a crucial role in navigating language ambiguity and surfacing hidden insights by employing several techniques for contextual understanding, like classification, entity identification, fact extraction and relationship extraction.
Content Classification
Content classification is the backbone of organizing and understanding vast amounts of information across various platforms. Whether it’s categorizing articles, emails or blogs, the ability to classify content accurately is crucial for efficient information retrieval and analysis. Text analytics play a crucial role in employing NLP techniques to extract meaningful insights from textual data based on predefined criteria, such as topic, sentiment or language. Not only does this streamline content management practices, but it also enables businesses to gain valuable insights from their data.
Entity Identification
Entity identification enables the identification and categorization of specific entities from unstructured data, including names of people, organizations, locations, dates and more. By employing text analytics, organizations can recognize and tag these entities within a given document or dataset. This saves organizations time and resources when leveraging existing data and drives actionable intelligence.
Fact Extraction
Fact extraction is the accurate and effective retrieval of more complex bits of information from textual documents. This allows business users to extract data points in context, driving actionable intelligence and supporting informed decisions based on factual evidence. One powerful example combines extracted facts with internal and external, structured and unstructured data—building even richer analytical applications, enhancing search results and supporting more accurate and trustworthy AI.
Relationship Extraction
Relationship extraction involves the identification and understanding of connections between entities mentioned in textual documents. By uncovering connections between entities, organizations can gain a deeper understanding of data, identify trends and drive business success.
Semantic Knowledge Models
Semantic knowledge models are the cornerstone for successful classification strategies and ultimately serve as a rich metadata source. This enables companies to resolve disambiguation and guides business users to seek information based on their needs.
Progress Semaphore is a semantic platform that enables businesses to model enterprise knowledge and build rich semantic models. The classification strategy is model-driven, meaning the semantic models are applied to drive the classification strategy. This enables customers to extract valuable insights from their data. Semantic AI-powered text analytics revolutionize how businesses extract valuable information from text, adding additional context that can provide advanced analytics, herald better data analysis and provide better data for generative AI tools.
The Need for Text Analytics Today
According to IDC, by 2025 data is expected to grow to 175 zettabytes globally, and unstructured data is estimated to account for 80% of it. With this sheer amount of textual information, it is more important than ever for businesses to exploit their information and make sense of it. This has become a priority for most CIOs and CDOs, as they want to use unstructured data in their plans to enhance their analytics and AI endeavors. But unstructured data is just part of the problem. Language ambiguity, data bias and vocabulary gaps can also impact businesses’ ability to drive new initiatives and build new AI-powered applications.
Text analytics address several challenges posed by the sheer volume, complexity and unstructured nature of textual data.
Unstructured Data Challenges
Unstructured data presents a big problem for modern enterprises that want to make better business decisions. Making sense of their unstructured data seems to be the path forward. Text analytics can leverage unstructured data and make it machine-understandable and usable.
Data Overload
With the exponential growth of digital content, organizations are struggling to cope with the vast amounts of unstructured data. Text analytics makes unstructured data easy to process by machines. This is achieved by using human judgments about the “aboutness” of data, leading to improved human-like understanding.
Language Ambiguity
Human language is inherently nuanced and ambiguous, making it challenging for traditional systems to interpret correctly. Text analytics can add another layer of context to existing data, making it more human-readable and understandable.
Insights Extraction
Extracting meaningful insights from textual data requires more than simple keyword searches. Text analytics employs advanced algorithms to uncover hidden patterns, trends and sentiment within text—providing valuable decision-making and strategy formulations.
Regulatory Compliance and Risk Management
Compliance regulations and risk management require organizations to monitor and analyze large amounts of textual data, including legal documents and contracts. Text analytics help automate compliance processes and mitigate risks more efficiently.
Personalization and Customer Experience
Understanding customer preferences and feedback is essential for delivering personalized experiences. Text analytics enable organizations to analyze customer interactions across various channels, identify trends and tailor product offerings to customer needs more effectively.
Once you leverage the power of text analytics in your business, you can build on them a wide array of business applications, like improving enterprise search, knowledge sharing, enhancing business intelligence and developing smart AI applications.
Text Analytics and Generative AI
AI is no longer just a buzzword, but a priority for business leaders who seek to leverage the transformative potential of this technology with practical applications. According to a 2023 Gartner press release, 45% of the 1,400 executive leaders polled in a Gartner survey “reported that they are in piloting mode with generative AI, and another 10% have put generative AI solutions into production.” The same press release cited this as “a significant increase from a Gartner poll conducted in March and April 2023, in which only 15% of respondents were piloting generative AI and 4% were in production.”
While there are many use cases for effective and successful generative AI applications in business settings, AI does present its fair share of obstacles. From data cutoffs, hallucinations and generation of inaccurate and biased content, to ethical challenges and lack of explainability, AI presents challenges that companies must overcome to effectively leverage the technology.
“This year GPT and LLMs pushed AI to new heights but they are still struggling with hallucinations, a lack of transparency, and a mismatch of enterprise vocabulary and the public vocabulary they are trained on. Also, GPT provides good general answers, but text analytics adds precision, transparency, and works with enterprise vocabularies. The future will be the integration of text analytics and GPT/LLM and the platform for that integration is semantic software like Semaphore,” said Tom Reamy, CEO of KAPS Group.
What Do You Get by Adding Text Analytics?
Accuracy! Precision! Structure! Text analytics adds structure to the content used by generative AI. With text analytics, your business can uncover information hidden in your enterprise data and use it as a prompt for generative AI, leading to more accurate and trustworthy results. Instead of building your own model, you can curate the content through classification strategies and provide this model and related information to the generative AI for improved responses and sourcing, enabling more accuracy and trust.
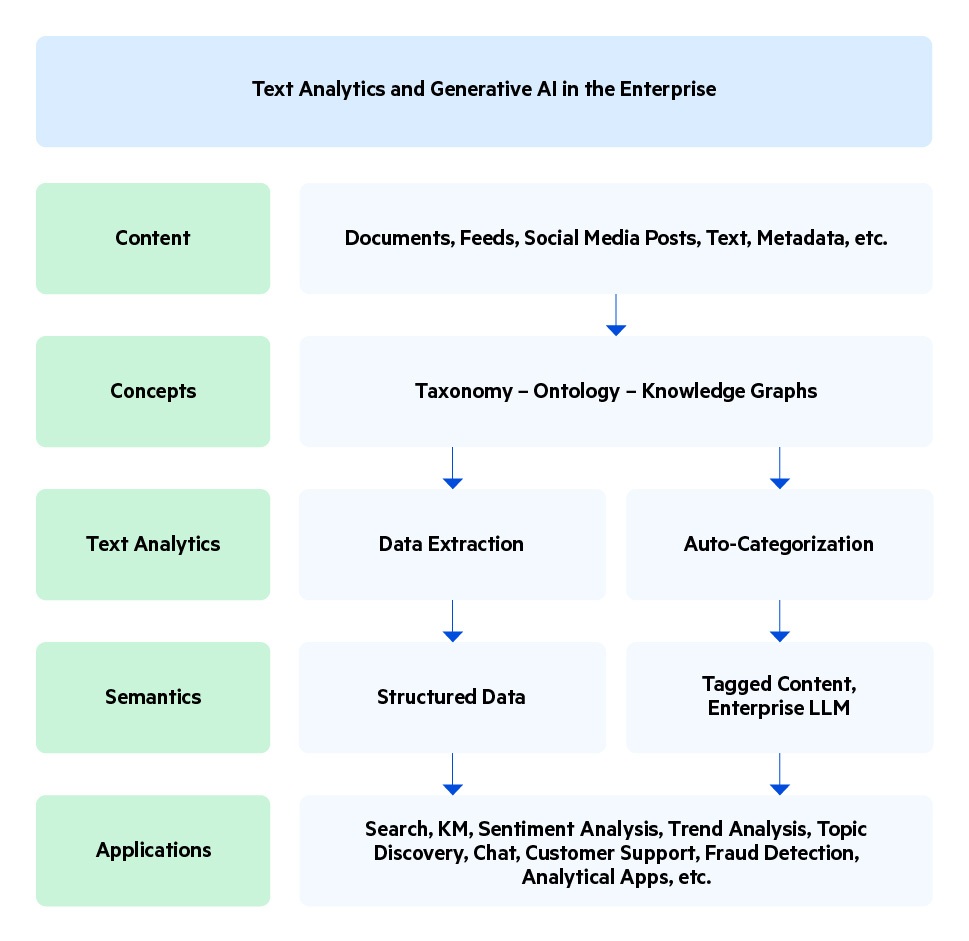
This can be achieved through Semantic RAG. Semantic RAG enables businesses to feed semantically relevant content to generative AI, businesses can get more accurate and trustworthy answers that meet their business reality and enhance business operations.
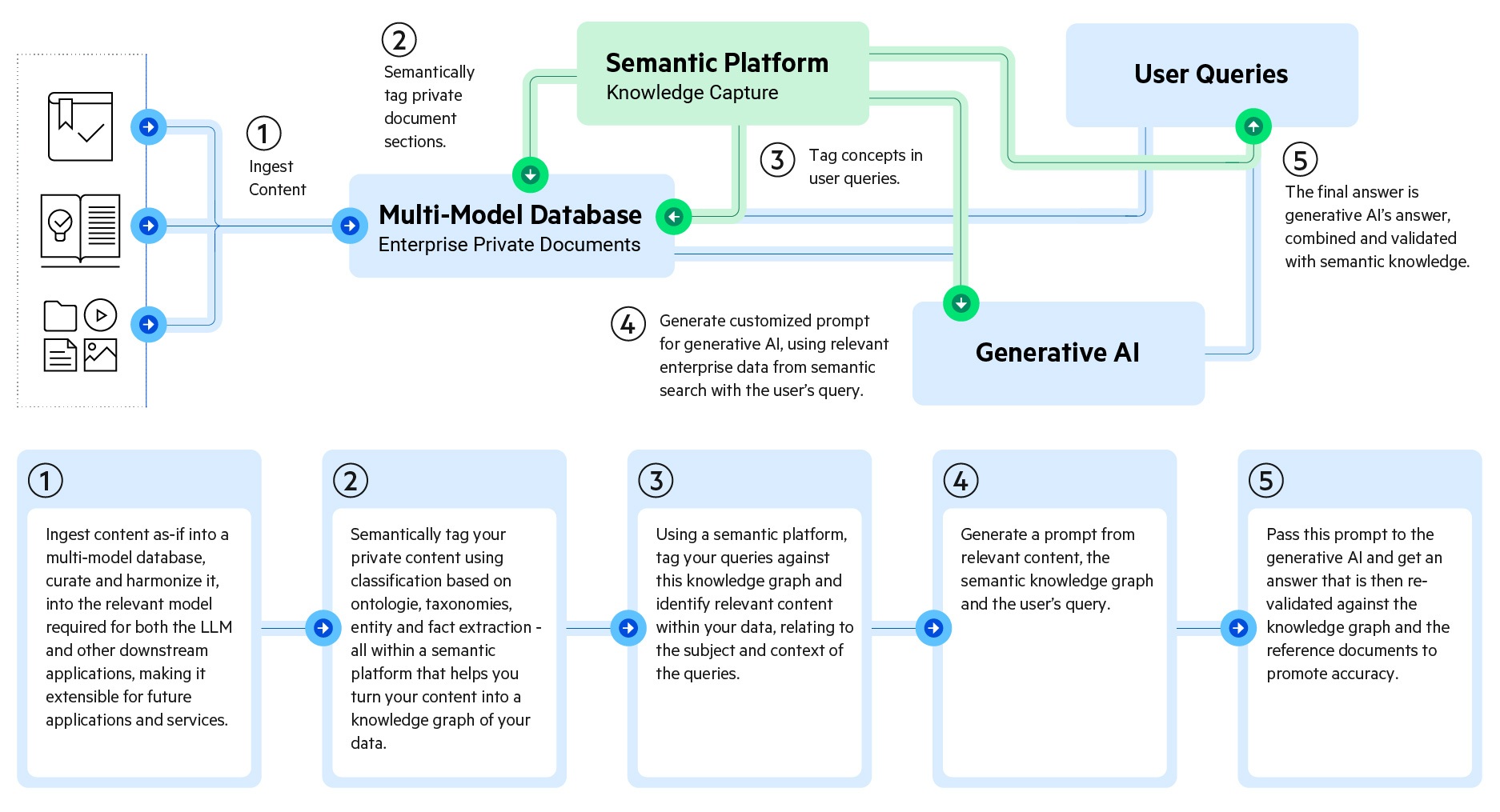
While text analytics and generative AI serve distinct purposes, their synergy offers unprecedented opportunities for innovation and insight generation. By combining the analytical capabilities of text analytics with the creative potential of generative AI, organizations can extract deep insights from textual data and generate new content that resonates with their audience.
Text Analytics Benefits Summary
In summary, text analytics help organizations unlock valuable insights, improve decision making and gain a competitive advantage in today’s data-driven world. They play a pivotal role in bolstering the utilization of genAI in businesses by enabling AI tools to work with contextual data relevant to the specific use case.
Watch our on-demand webinar, “From Text to Value: Pairing Text Analytics and Generative AI,” to learn more about this topic.

