
With the growing relevancy of AI in platforms such as ChatGPT, the topic of data privacy is always a priority. However, ChatGPT can provide new answers and insights using suitable large language models (LLM).
Artificial intelligence (AI), similar to many cutting-edge technologies, will always raise some questions. And companies that are deploying it in their tech stacks will face challenges.
One primary concern is using private company data in tandem with publicly facing and internal AI platforms. This can range from a healthcare organization retaining patient data, a large corporation's employee payroll information or research of private pharmaceutical data.
Creating effective AI requires a large sample size of high-quality public and/or private data. Companies with access to confidential data, such as healthcare companies with medical records, have a competitive advantage when building AI-based solutions.
However, there is an enormous responsibility when using sensitive data or leveraging your proprietary data, such as business operations data. The same enterprises and organizations must consider ethical and regulatory requirements surrounding data privacy, fairness, explainability, transparency, robustness and access.
IT and security professionals must prioritize protecting sensitive data while leveraging it to improve outcomes for their organization and its customers. And this has never been more crucial when trying to utilize generative AI tools responsibly.
What Are Large Language Models and Why Are They Important for AI?
Large language models (LLM) are powerful AI models trained on text data to perform various natural language processing tasks, including language translation, question answering, summarization and sentiment analysis. These models are designed to analyze language in a way that mimics human intelligence, allowing them to process, understand and generate human speech.
The models are trained on vast amounts of data, which allows them to detect patterns and make predictions that would be difficult or impossible for a human to do manually. This has many potential applications in healthcare, finance and customer service.
However, the complexity of these models comes with ethical challenges for your business as well as technical challenges. These can include data bias, copyright infringement and potential libel cases.
What Are Some Examples of AI Platforms Used in Business?
ChatGPT
Introduced to the world in November 2022 by OpenAI, ChatGPT is an AI chatbot designed to mimic human conversations, provide business information, create pitches/marketing copy and write stories. Training for ChatGPT involved taking data from the Internet, private data repositories and programming languages.
Google Bard
Google Bard received its initial release in March 2023, and works as a conversational AI chat service. Bard is powered by Google’s proprietary LLM, PaLM 2 and Google’s Language Model for Dialogue Applications (LaMDA). Much like other chatbots, Bard is capable of coding and solving complex math problems.
Anthropic Claude
Anthropic Claude is a chatbot with capabilities similar to Bard and ChatGPT. But its one major feature is its support of 100,000 tokens of context tokens, which is significantly more than other chatbots. Anthropic has also spent a lot of time focused on the dangers of AI and is training their AIs to be “helpful, harmless and honest” thereby improving the trustworthiness of the AI. Another trait of Claude is its ability for users to delete conversations and support VPN browsing. Also, trivia, Claude is named after the “father of information theory”, Claude Shannon.
What Are the Risks and Challenges Involved with Private Data and AI?
While there are many use cases for chatbot AIs and their effectiveness, it does face its fair share of difficulties.
Hallucinations
A hallucination, as the literal dictionary definition, is "an experience involving the apparent perception of something not present." When it comes to AI, a hallucination is when it reports error-filled answers to the user. Because of the way the LLMs predict the next word, these answers really do sound plausible, but the information may be incomplete or false. For example, if a user asks a chatbot what the average revenue was of a competitor, chances are those numbers may be way off. These kinds of errors are a regular occurrence. In fact, they will happen between 15% to 20% of the time and need to be kept in mind when querying your AI.
Fairness/Biases
LLMs, like any other AI system, have limitations and potential issues, including exhibiting biases, meaning that they may produce results that reflect the biases in the training data rather than objective reality. For example, a language model trained on a predominantly male dataset might produce biased output regarding gendered topics. In fact, Progress conducted a research study and found the following three statistics based on data bias:
- 65% of businesses and IT executives currently believe there is data bias in their respective organizations
- 13% of businesses are currently addressing data bias
- 78% believe data will become a bigger concern as AI/ML use increases
LLMs have the potential to produce biased outcomes, and they require a lot of computation power and data to train, leading to concerns around data privacy and energy consumption. While the potential benefits of these models are immense, users should carefully examine the ethical and practical considerations.
Reasoning/Understanding
LLMs may need help with tasks that require deeper reasoning or understanding of complex concepts. A LLM can be trained to answer questions that require a nuanced understanding of culture or history. Sometimes, these models perpetuate stereotypes or provide misinformation if not carefully monitored and trained. As with any AI system, it is crucial to be aware of these limitations and potential issues, and to use these models responsibly with a keen eye toward ethical considerations.
Data Cutoffs
Given that it takes a lot of resources to train the models, their model memory tends to be out of date.
Explainability
Often, it is quite difficult to understand how the LLM generated its response. LLMs should be trained or prompted to show their reasoning and reference the data they used to construct their response.
Robustness
As with all technologies, guarding against unexpected inputs or situations is even more important with LLMs.
If we can successfully address these issues, the trustworthiness of our solutions will increase along with user satisfaction ultimately leading to the solution’s success.
How Can MarkLogic and Semaphore Assist with Using Private Data for ChatGPT?
Now, with all the above information, how can someone receive more accurate answers when using ChatGPT? Can a user influence a language model with private data to obtain correct answers?
One of the standout capabilities of Progress MarkLogic includes its ability to store and query structured and unstructured data. Additionally, Progress Semaphore can capture subject matter expert (SME) content via its intuitive GUI. The resulting knowledge graphs can extract facts found within the data and can also tag the private data with semantic knowledge. In turn, Semaphore can also use this semantic knowledge to start tagging user questions/inputs and specific ChatGPT answers with this said knowledge. Users can then use MarkLogic and Semaphore to fetch semantically relevant private data for ChatGPT.
A strong, secure, transparent, governed AI knowledge management solution can be created from combining these modules.
The best way to compare how MarkLogic and Semaphore works in conjunction with LLMs is to think about closed book and open book exams.
Closed Book Exam – ChatGPT Only

Describing the closed book exam model can be done in two steps:
1. The user asks ChatGPT the question or requests information.
2. ChatGPT will provide answers to these inquiries based on the knowledge embedded within the language model that is currently being utilized.
Without semantic and tagged data, users may not get entirely accurate information. In fact, they may not even be aware of a response’s inaccuracies.
Open Book Exam with the Ability to Get to the Right Page – ChatGPT with MarkLogic Only
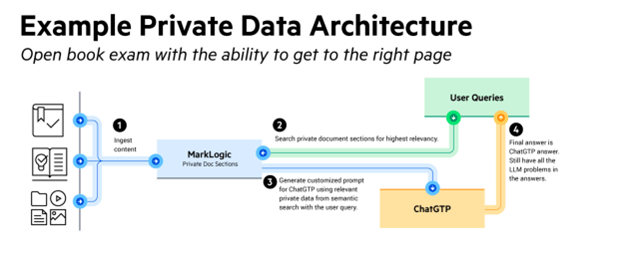
When using MarkLogic's abilities alongside ChatGPT, here is what users can experience:
1. The user asks ChatGPT the question or requests information.
2. MarkLogic searches for the most relevant private document sections based on the user’s question.
3. The middle tier or MarkLogic can then generate a customized prompt for ChatGPT using relevant private data from search with the user query.
4. ChatGPT provides the final answer.
With MarkLogic, users can increase accuracy and efficiency while introducing governance. Despite the increase in accuracy and efficiency, LLMs, not to mention their users, can still need help with answers. Especially since the data can lack context and meaning.
Open Book Exam with Expert Help – ChatGPT with MarkLogic and Semaphore
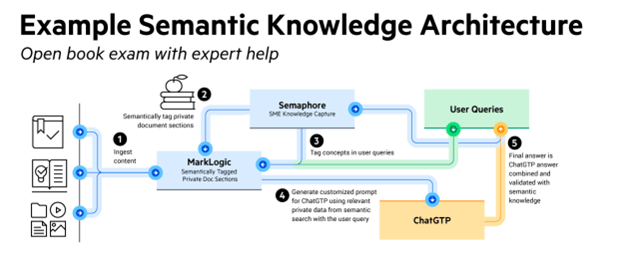
But, when using both products, users will obtain knowledge and information more easily. And through this, users can gain expert-level insights.
1. The user asks ChatGPT the question or requests information.
2. Semaphore semantically tags, categorizes and fact extracts private document sections.
3. Semaphore tags key concepts in user queries too.
4. The middle tier or MarkLogic can then generate a customized prompt for ChatGPT using only semantically relevant private data from semantic search with the user query.
5. The final answer is a combination of ChatGPT’s answer validated with semantic knowledge from Semaphore.
The combined results will allow LLMs and users to easily access and fact check the results against the source content and the captured SME knowledge.
MarkLogic and Semaphone enhance the overall user experience with ChatGPT, thereby improving AI trustworthiness.
There are conversations about the ongoing worry of AI taking over... but, what corporate users should be worried about right now is who is using the AI to gain a competitive advantage. Something that has always been prevalent in business, is using the most effective tools based on growing technology platforms. Regardless of if they are a member of the IT team or assist with creating marketing campaigns, users are always seeking the best tools to gain a competitive advantage. After all, no one wants to miss out on an opportunity to grow their business.
Generative AI tools offer this opportunity. However, businesses and organizations are responsible for implementing trustworthy AI data protection in the best way possible. Not just from the fear of missing out.
If you want to see more in-depth examples of LLMs and private data in action, register for the upcoming Convergence of Private Data and AI webinar.

