How Retrieval Improves Accuracy and Reduces Hallucination in AI

Here’s how retrieval-based grounding works to reduce hallucinations and generate answers with better context.
Most AI systems have a credibility problem, and the evidence is everywhere.
A Columbia Journalism Review investigation found that eight generative search tools routinely failed at one of the simplest safety tasks: refusing to answer questions they couldn’t answer accurately. Instead, they produced incorrect or speculative responses with complete confidence.
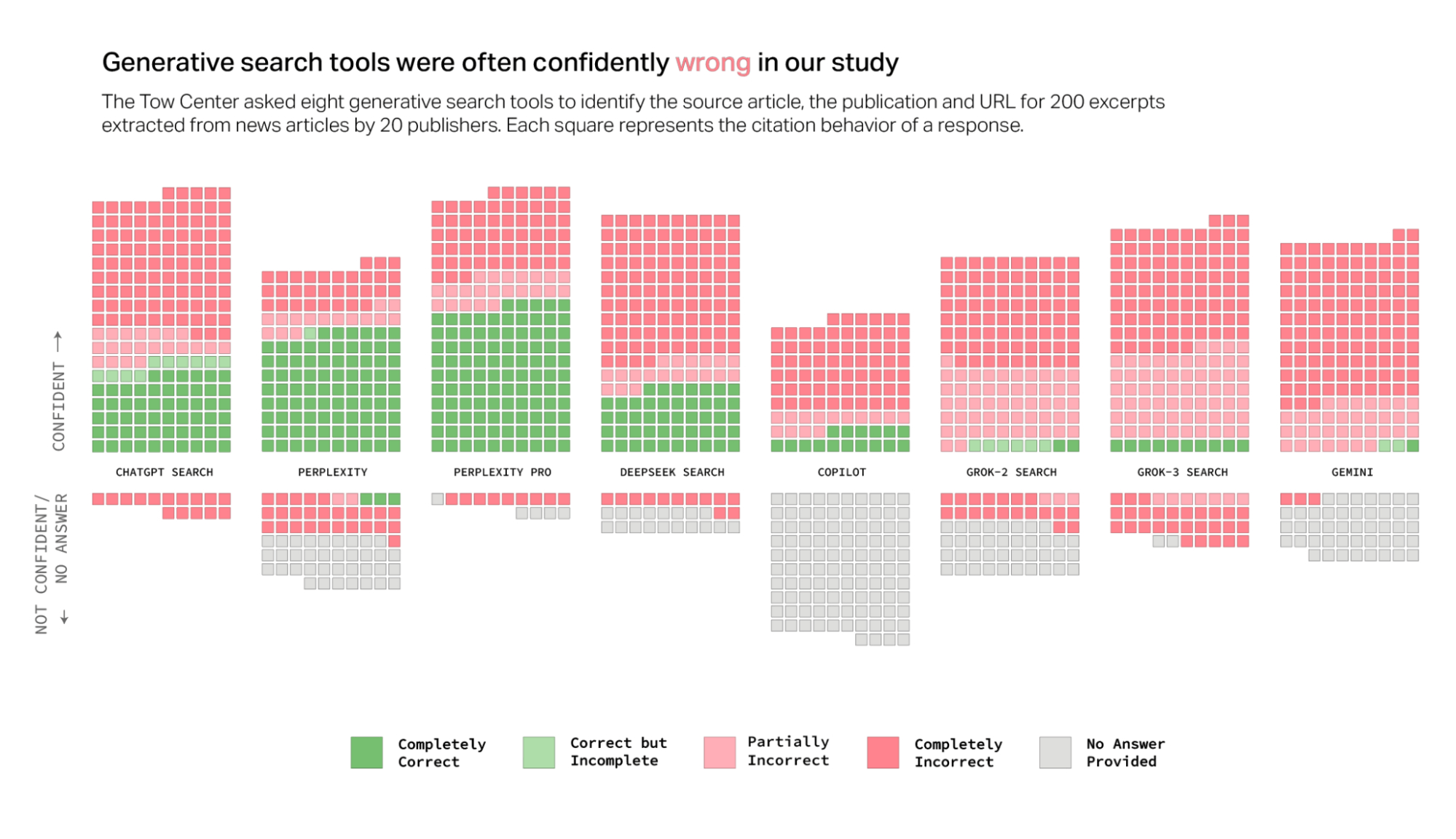
Stanford researchers observed something similar. When they asked LLMs about real court rulings, the models hallucinated at least 75% of the time.
The root cause is structural, not accidental. These systems generate responses by predicting the most likely next word, not by checking facts against any external source. The output may sound authoritative, but there is no mechanism for verification. If the model doesn’t know something, it guesses.
Retrieval-augmented generation (RAG) helps address this by changing how AI accesses information. Instead of generating answers from learned patterns, retrieval systems search your actual documents, pull relevant context and use that context to ground responses in verifiable sources.
This article breaks down how retrieval-based grounding works, why it’s more reliable than standard generation and how it restores transparency to AI outputs.
Why Language Models Hallucinate
To understand why retrieval helps, you first need to understand why hallucinations happen in the first place.
Language models are trained on massive datasets—billions of words scraped from the internet, books, articles and code repositories. During training, they learn statistical patterns: which words tend to follow which other words, how sentences are structured, what topics relate to each other.
When you ask a language model a question, it doesn’t “look up” an answer. It generates one by predicting what tokens (words or word fragments) are most likely to come next based on the patterns it learned. This process is entirely probabilistic. The model calculates a probability distribution over all possible next tokens, then samples from that distribution to produce output.
But here’s the problem: probability and truth aren’t the same thing.
A model might have seen the phrase “the capital of France is Paris” thousands of times during training, so when you ask about France’s capital, it confidently generates “Paris” because that’s the statistically likely completion.
But if you ask about something the model saw rarely or never during training, it still has to generate an answer. It can’t say “I don’t know”—at least not without specific training to do so. Instead, it produces whatever seems most plausible based on nearby patterns.
This is where hallucinations come from. The model generates text that fits the linguistic and structural patterns it learned, but that text may have no connection to reality.
The Compounding Error Problem
Hallucinations get worse as responses get longer, and the reason is mathematical.
Language models generate text autoregressively, meaning each token depends on all the tokens that came before it. If the model makes an error early in a response, that error becomes part of the context for generating the next token. One mistake compounds into another, and, before long, the entire response has drifted away from anything factual.
Think of it like a game of telephone. The first person hears a message correctly, but introduces a small error when passing it on. The second person hears that slightly wrong version and adds their own error. By the time the message reaches the 10th person, it bears little resemblance to the original.
In language models, this happens within a single response. An early hallucination about a date might lead to a hallucinated event, which leads to a hallucinated outcome, all presented with the same confident tone.
What Retrieval Actually Does
Retrieval-augmented generation breaks the pattern by giving the model access to external information during generation, not just during training.
Here’s how the process works:
Query Processing: When a user asks a question, the system first converts that query into a numerical representation called an embedding. This embedding captures the semantic meaning of the question in a high-dimensional vector space.
Document Retrieval: The system searches a pre-indexed knowledge base for documents with similar embeddings.
Context Assembly: The most relevant documents are retrieved and assembled into a context window. This context typically includes multiple passages or entire documents, depending on the system’s configuration and the query complexity.
Grounded Generation: The language model receives both the original query and the retrieved context. It generates a response based on this combined input, using the context as evidence rather than relying solely on patterns from training.
Citation and Verification: Because the system knows which documents it used, it can provide citations. Users can trace each claim back to its source, verify accuracy and understand where the information came from.
The critical difference is timing. In standard generation, the model only has access to what it learned during training. In RAG, the model has access to current, specific documents that are retrieved in real time based on what the user actually asked.
How Retrieval Reduces Hallucination
Retrieval attacks the hallucination problem from multiple angles.
The model generates responses based on actual text from retrieved documents, not just statistical patterns. If the retrieved context says X, the model is far more likely to output X than to invent Y.
The model doesn’t need to have “memorized” facts during training. It can reference documents on demand, which means it can handle queries about information that wasn’t in its training data or that has changed since training.
Users can verify claims by checking the source documents. This doesn’t eliminate errors entirely, but it makes them detectable. A user can read the cited passage and confirm whether the model’s interpretation is accurate.
When retrieval finds no relevant documents, the system can acknowledge that limitation instead of guessing. This is a fundamental shift from traditional generation, where the model has no way to know whether it’s operating on solid ground or pure speculation.
The Limits of Grounding
It’s worth being clear about what RAG doesn’t solve.
If your knowledge base contains errors, biased information or outdated content, retrieval will surface that content. RAG doesn’t fact-check your sources, it just retrieves them.
Some queries require multi-hop reasoning across multiple documents, synthesizing information that no single source contains. RAG helps by providing relevant context, but the language model still has to perform the synthesis, and errors can creep in during that process.
When a user’s question is vague or could be interpreted multiple ways, retrieval might pull documents for the wrong interpretation. The system can only ground responses in what it thinks the user is asking.
If a question requires reasoning beyond what’s explicitly stated in any document (hypothetical scenarios, counterfactuals, creative applications), retrieval provides less value. The model has to extrapolate, and that’s when hallucinations become more likely again.
RAG is powerful, but it’s not magic. It’s a method for grounding AI responses in verifiable sources, which dramatically improves reliability for a wide range of tasks. Understanding its limitations helps you deploy it effectively.
Measuring RAG Quality
Progress Agentic RAG includes REMi, a proprietary evaluation model designed specifically to assess RAG output quality. Unlike general-purpose evaluations, REMi focuses on dimensions critical to retrieval-augmented systems:
Answer relevance (does the response actually address the user’s question?)
Context relevance (were the retrieved documents actually relevant to the query?)
Groundedness (is the response supported by the retrieved documents, or did the model introduce claims not present in the source material?)
These metrics give you quantifiable insight into where a RAG system performs well and where it fails. If groundedness scores are low, the generation model might need better prompting or fine-tuning. If context relevance is poor, retrieval configuration needs adjustment.
Most teams building RAG systems rely on manual spot-checking, which scales poorly. Automated evaluation frameworks like REMi make it possible to continuously monitor quality as data and usage patterns evolve.
The Bottom Line
Hallucinations stem from a fundamental limitation: language models predict probable text, not verified facts. Retrieval solves this by giving models access to actual documents instead of forcing them to rely on learned patterns.
The result is transparency. Users can trace claims back to sources. Outputs are grounded in verifiable information. When the system doesn’t know something, it can acknowledge that gap instead of inventing an answer.
RAG has proven to be the most effective hallucination mitigation technique, reducing error rates by up to 71% .
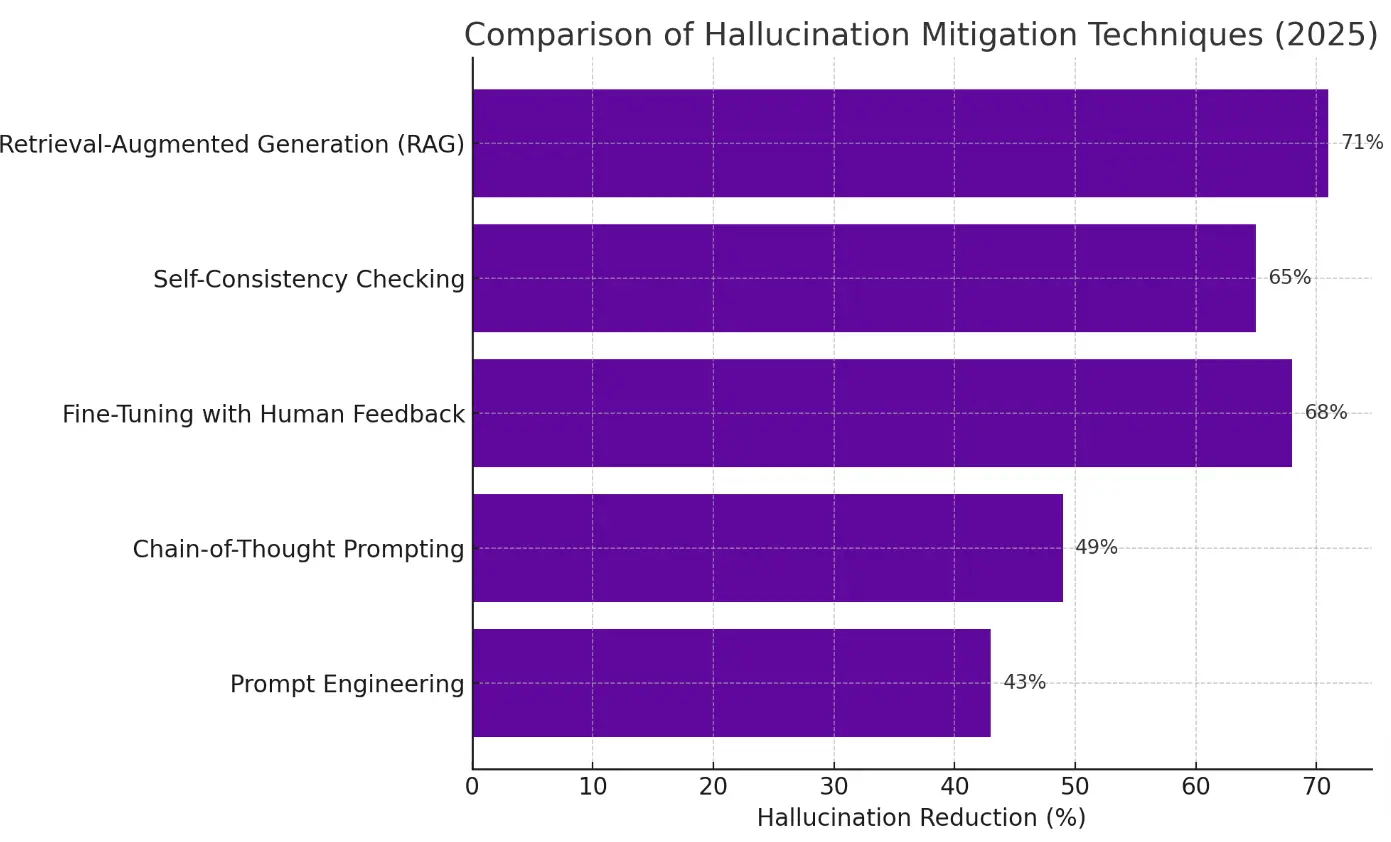
That improvement shows up in higher accuracy, better user trust and systems that work reliably in domains where mistakes have real consequences.
If you’re building AI into workflows where accuracy matters, retrieval is important. It’s the difference between a system that guesses and a system that knows.
Ready to see how retrieval grounding works with your data? Try Progress Agentic RAG and connect it to your knowledge base, or schedule a demo to explore how retrieval strategies adapt to your specific use case.
And now, you can use the insights of Progress Agentic RAG inside your website: Progress unveiled the first Generative CMS. Progress Sitefinity CMS powered by Progress Agentic RAG transforms enterprise knowledge into adaptive experiences—each assembled in real time by AI that understands your users, your brand and your goals.
Request early access for Sitefinity Generative CMS and get started with your own innovations.

