JDBC connection pooling tutorial
Java connection pooling with JDBC applications
This tutorial provides information to help developers implement a connection pooling strategy for applications that must handle connection pooling. To start, we will guide you through an overview of JDBC connection pooling as specified by the JDBC 3.0 specification. Then, we will demonstrate how to use the Progress DataDirect Connection Pool Manager (which is shipped with Progress DataDirect® for JDBC Drivers) for your applications.
DataDirect for JDBC drivers support connection pooling for Oracle, SQL Server, PostgreSQL and many more data sources.
How JDBC connection pooling works
Establishing JDBC connections is resource-expensive, especially when the JDBC API is used in a less than optimal server environment, such as when a DataDirect for JDBC Driver is running on a Java-enabled web server. In this type of environment, performance can be improved significantly when connection pooling is used. Connection pooling allows you to reuse connections rather than create a new one every time an application needs to connect to the database. To facilitate connection reuse, a memory cache of database connections, called a connection pool, is maintained by a connection pooling module as a layer on top of a standard JDBC driver product.
Connection pooling is performed in the background and does not affect how an application is coded; however, the application must use a DataSource object (an object implementing the DataSource interface) to obtain a connection, instead of using the DriverManager class. A class implementing the DataSource interface may or may not provide connection pooling. A DataSource object registers with a JNDI naming service. Once a DataSource object is registered, the application retrieves it from the JNDI naming service in the standard way.
For example:
Context ctx = new InitialContext();
ConnectionPoolDataSource ds =
(ConnectionPoolDataSource)ctx.lookup("EmployeeDB");
Connection conn = ds.getConnection("scott", "tiger");First, the lookup determines whether there is a data source that matches the specified value, such as EmployeeDB. If the DataSource object provides connection pooling, the getConnection method returns a connection from the pool if one is available. If the DataSource object does not provide connection pooling or, if there are no available connections in the pool, the getConnection method creates a new connection. Note that reused connections from the pool behave the same way as newly created physical connections. When the application has finished its work with the connection, the application explicitly closes the connection.
For example:
Connection con = ds.getConnection("scott", "tiger"); // Do some database activities using the connection... con.close();
The closing event on a pooled connection signals the pooling module to place the connection back in the connection pool for future reuse.
About the connection pooling framework for the JDBC API
The JDBC 3.0 API provides a general framework with hooks to support connection pooling rather than specifying a particular connection pooling implementation. This way, third-party vendors or users can implement the specific caching or pooling algorithms that best fit their needs.
The JDBC 3.0 API specifies a ConnectionEvent class and the following interfaces as the hooks for any connection pooling implementation:
- ConnectionPoolDataSource
TheConnectionPoolDataSourceinterface acts as a factory that createsPooledConnectionobjects. - PooledConnection
APooledConnectionobject acts as a factory that createsConnectionobjects. APooledConnectionobject maintains the physical connection to the database, while theConnectionobject created by thePooledConnectionobject is simply a handle to the physical connection. - ConnectionEventListener
TheConnectionEventListenerinterface receivesConnectionEventobjects fromPooledConnectionobjects when a connection closes or a connection error occurs. When a connection created by aPooledConnectioncloses, the connection cache module returns thePooledConnectionobject to the cache. - JDBCDriverVendorDataSource
A JDBC driver vendor must provide a class that implements the standardConnectionPoolDataSourceinterface. This interface provides hooks that third-party vendors can use to implement pooling as a layer on top of their JDBC drivers.
- JDBCDriverVendorPooledConnection
A JDBC driver vendor must provide a class that implements the standardPooledConnectioninterface. This interface allows third-party vendors to implement pooling on top of their JDBC drivers.
- PoolingVendorDataSource
A third-party vendor must provide a class that implements theDataSourceinterface. This interface is the entry point that allows interaction with their pooling module. The pooling vendor's class uses the JDBC driver'sPooledConnectionDataSourceobject to create thePooledConnectionsthat the pool manages.
- PoolingVendorConnectionCache
The JDBC 3.0 API does not specify the interfaces to be used between theDataSourceobject and the connection cache. The pooling vendor determines how these components will interact. Usually, a connection cache module contains one or multiple classes. In Figure 1, thePoolingVendorConnectionCacheclass is used as a simple way to convey this concept. The connection cache module should have a class that implements the standardConnectionEventListenerinterface.
Figure 1 shows this general framework.
Figure 1: JDBC 3.0 Connection Pooling Architecture
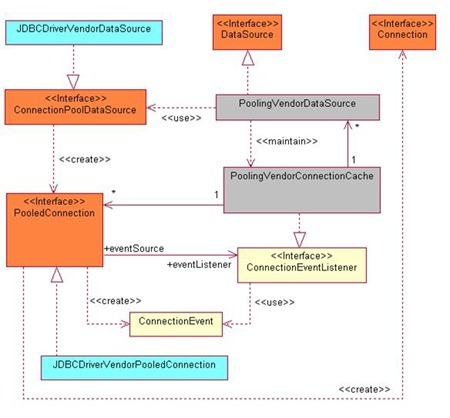
When an application makes a connection by calling DataSource.getConnection() on a PoolingVendorDataSource object, the PoolingVendorDataSource object performs a lookup in the connection cache to determine if a PooledConnection object is available. If one is available, it is used. If a PooledConnection object is not available, the JDBC driver vendor's ConnectionPoolDataSource creates a new PooledConnection object. In either case, a PooledConnection object is made available.
The PoolingVendorDataSource object then invokes the PooledConnection.getConnection() method to obtain a Connection object, which it returns to the application to use as a normal connection. Because the JDBC driver vendor implements the PooledConnection interface, the JDBC driver creates the Connection object; however, this Connection object is not a physical connection as in the non-pooling case. The Connection object is a handle to the physical connection maintained by the PooledConnection object.
When the application closes the connection by calling the Connection.close() method, a ConnectionEvent is generated and is passed to the cache module. The cache module returns the PooledConnection object to the cache to be reused. The application does not have access to the PooledConnection.close() method. Only the connection pooling module, as part of its clean-up activity, issues the PooledConnection.close() method to actually close the physical connection.
Creating a data source
This section provides examples on how to create pooled and non-pooled DataSource objects for DataDirect for JDBC drivers and register them to a JNDI naming service
Creating a DataDirect Data Source Object
This example shows how to create a DataDirect for JDBC drivers DataSource object and register it to a JNDI naming service. The DataSource class provided by the DataDirect for JDBC drivers is database-dependent. In the following example, we use Oracle, so the DataSource class is com.ddtek.jdbcx.oracle.OracleDataSource.
If you want the client application to use:
- A non-pooled data source, the application can specify the JNDI name of this data source object as registered in the following code example (
jdbc/ConnectSparkyOracle). - A pooled data source, the application must specify the JNDI name (
jdbc/SparkyOracle) as registered in the code example in the following Creating a data source using the DataDirect Connection Pool Manager.
//********************************************************************//// This code creates a DataDirect Connect for JDBC data source and // registers it to a JNDI naming service. This DataDirect Connect for // JDBC data source uses the DataSource implementation provided by // DataDirect Connect for JDBC Drivers.//// This data source registers its JNDI name as <jdbc/ConnectSparkyOracle>.// Client applications using non-pooled connections must perform a lookup // for this name.////********************************************************************// From DataDirect Connect for JDBC:import com.ddtek.jdbcx.oracle.OracleDataSource;import javax.sql.*;import java.sql.*;import javax.naming.*;import javax.naming.directory.*;import java.util.Hashtable;public class OracleDataSourceRegisterJNDI{public static void main(String argv[]) { try { // Set up data source reference data for naming context: // ----------------------------------------------------- // Create a class instance that implements the interface // ConnectionPoolDataSource OracleDataSource ds = new OracleDataSource(); ds.setDescription( "Oracle on Sparky - Oracle Data Source"); ds.setServerName("sparky"); ds.setPortNumber(1521); ds.setUser("scott"); ds.setPassword("test"); // Set up environment for creating initial context Hashtable env = new Hashtable(); env.put(Context.INITIAL_CONTEXT_FACTORY, "com.sun.jndi.fscontext.RefFSContextFactory"); // The specified directory must exist before running the application env.put(Context.PROVIDER_URL, "file:c:\\JDBCDataSource"); Context ctx = new InitialContext(env); // Register the data source to JNDI naming service ctx.bind("jdbc/ConnectSparkyOracle", ds); } catch (Exception e) { System.out.println(e); return; }} // Main} // class OracleDataSourceRegisterJNDICreating a Data Source Using the DataDirect Connection Pool Manager
The following Java code example creates a data source for DataDirect for JDBC Drivers and registers it to a JNDI naming service. The PooledConnectionDataSource class is provided by the DataDirect com.ddtek.pool package. In the following code example, the PooledConnectionDataSource object references a pooled DataDirect for JDBC Drivers data source object. Therefore, the example performs a lookup by setting the DataSourceName attribute to the JNDI name of a registered pooled data source (in this example, jdbc/ConnectSparkyOracle, which is the DataDirect for JDBC Drivers DataSource object created in Creating a DataDirect Data Source Object.
Client applications that use this data source must perform a lookup using the registered JNDI name (jdbc/SparkyOracle in this example).
//********************************************************************//// This code creates a data source and registers it to a JNDI naming // service. This data source uses the PooledConnectionDataSource // implementation provided by the DataDirect com.ddtek.pool package.//// This data source refers to a previously registered pooled data source.//// This data source registers its name as <jdbc/SparkyOracle>// Client applications using pooling must perform a lookup for this name.////********************************************************************// From the DataDirect connection pooling package:import com.ddtek.pool.PooledConnectionDataSource;import javax.sql.*;import java.sql.*;import javax.naming.*;import javax.naming.directory.*;import java.util.Hashtable;public class PoolMgrDataSourceRegisterJNDI{ public static void main(String argv[]) { try { // Set up data source reference data for naming context: // ---------------------------------------------------- // Create a pooling manager's class instance that implements // the interface DataSource PooledConnectionDataSource ds = new PooledConnectionDataSource(); ds.setDescription("Sparky Oracle - Oracle Data Source"); // Refer to a previously registered pooled data source to access // a ConnectionPoolDataSource object ds.setDataSourceName("jdbc/ConnectSparkyOracle"); // The pool manager will be initiated with 5 physical connections ds.setInitialPoolSize(5); // The pool maintenance thread will make sure that there are 5 // physical connections available ds.setMinPoolSize(5); // The pool maintenance thread will check that there are no more // than 10 physical connections available ds.setMaxPoolSize(10); // The pool maintenance thread will wake up and check the pool // every 20 seconds ds.setPropertyCycle(20); // The pool maintenance thread will remove physical connections // that are inactive for more than 300 seconds ds.setMaxIdleTime(300); // Set tracing off since we choose not to see output listing // of activities on a connection ds.setTracing(false); // Set up environment for creating initial context Hashtable env = new Hashtable(); env.put(Context.INITIAL_CONTEXT_FACTORY, "com.sun.jndi.fscontext.RefFSContextFactory"); env.put(Context.PROVIDER_URL, "file:c:\\JDBCDataSource"); Context ctx = new InitialContext(env); // Register the data source to JNDI naming service // for application to use ctx.bind("jdbc/SparkyOracle", ds); } catch (Exception e) { System.out.println(e); return; }} // Main} // class PoolMgrDataSourceRegisterJNDIConnecting to a Data Source
Whether connection pooling is used does not affect application code. Code changes are not required because the application performs a lookup on a JNDI name of a previously registered data source. If the data source specifies a connection pooling implementation during JNDI registration (as described in Creating a data source using the DataDirect Connection Pool Manager), the client application benefits from faster connections through connection pooling.
The following example shows code that can be used to look up and use a JNDI-registered data source for connections. You can specify the JNDI lookup name for the data source you created (as described in Creating a Data Source Using the DataDirect Connection Pool Manager).
//********************************************************************// // Test program to look up and use a JNDI-registered data source.//// To run the program, specify the JNDI lookup name for the // command-line argument, for example://// java TestDataSourceApp JNDI_lookup_name////********************************************************************import javax.sql.*;import java.sql.*;import javax.naming.*;import java.util.Hashtable;public class TestDataSourceApp{public static void main(String argv[]){ String strJNDILookupName = ""; // Get the JNDI lookup name for a data source int nArgv = argv.length; if (nArgv != 1) { // User does not specify a JNDI lookup name for a data source, System.out.println( "Please specify a JNDI name for your data source"); System.exit(0); } else { strJNDILookupName = argv[0]; } DataSource ds = null; Connection con = null; Context ctx = null; Hashtable env = null; long nStartTime, nStopTime, nElapsedTime; // Set up environment for creating InitialContext object env = new Hashtable(); env.put(Context.INITIAL_CONTEXT_FACTORY, "com.sun.jndi.fscontext.RefFSContextFactory"); env.put(Context.PROVIDER_URL, "file:c:\\JDBCDataSource"); try { // Retrieve the DataSource object that bound to the // logical lookup JNDI name ctx = new InitialContext(env); ds = (DataSource) ctx.lookup(strJNDILookupName); } catch (NamingException eName) { System.out.println("Error looking up " + strJNDILookupName + ": " +eName); System.exit(0); } int numOfTest = 4; int [] nCount = {100, 100, 1000, 3000}; for (int i = 0; i < numOfTest; i ++) { // Log the start time nStartTime = System.currentTimeMillis(); for (int j = 1; j <= nCount[i]; j++) { // Get Database Connection try { con = ds.getConnection("scott", "tiger"); // Do something with the connection // ... // Close Database Connection if (con != null) con.close(); } catch (SQLException eCon) { System.out.println("Error getting a connection: " + eCon); System.exit(0); } // try getConnection } // for j loop // Log the end time nStopTime = System.currentTimeMillis(); // Compute elapsed time nElapsedTime = nStopTime - nStartTime; System.out.println("Test number " + i + ": looping " + nCount[i] + " times"); System.out.println("Elapsed Time: " + nElapsedTime + "\n"); } // for i loop // All done System.exit(0);} // Main} // TestDataSourceAppNOTE: The DataDirect Connect for JDBC DataSource object class implements the DataSource interface for non-pooling in addition to ConnectionPoolDataSource for pooling. To use a non-pooling data source, use the JNDI name registered in the example code in section Creating a DataDirect data source object and run the TestDataSourceApp. For example:
java TestDataSourceApp jdbc/ConnectSparkyOracleClosing the connection pool
To ensure that the connection pool is closed correctly, the DataDirect Connection Pool Manager is notified automatically when an application stops running. However, the PooledConnectionDataSource.close method can also be used to explicitly close the connection pool while the application is running. For example, if changes are made to the pool configuration using a pool management tool, the PooledConnectionDataSource.close method can be used to force the connection pool to close and re-create the pool using the new configuration values.
Conclusion
Connection pooling provides a significant improvement on performance by reusing connections rather than creating a new connection for each connection request, without requiring changes in your JDBC application code.
DataDirect for JDBC drivers provide connectivity to Oracle, SQL Server, PostgreSQL and many more data sources.