Understanding Today’s AI Models

Since before the launch of ChatGPT, OpenAI was already training and releasing AI models for mass use through its application and APIs. Personally, I had to go through the waiting list to access the use of the models, in addition to witnessing the release of models such as GPT-2,Codex and DALL-E in its first version. All these models have evolved tremendously, being very different from what they were back in those days. Today, I come to tell you about the current landscape of the main types of AI models, as well as the characteristics that distinguish them. Let’s get started!
Models Focused on Text Generation
Undoubtedly, the pioneering company in the development of Large Language Models is OpenAI. I remember that the first models it launched often regurgitated learned text; it was so much so that to check if a text had been written with AI, it was enough to copy and paste a part of it into a search engine, which would give you exact matches if it had been generated by one of these models.

Over time, and with the use of different techniques such as output evaluations, policies aimed at getting the models to generate content instead of just quoting it, among others, we have seen significant advancements in the responses generated by LLMs. Let’s take a look at some of the most popular LLM models today, as well as characteristics that have improved over time.
Main LLM Models and Their Reasoning Ability
OpenAI promotes its latest model GPT-5 as a model with intelligence level akin to that of a Ph.D.
According to the official documentation page, GPT-5is actually a unified system composed of several models, each with different reasoning capabilities, in addition to a router to select the appropriate model according to the task at hand. This points to two characteristics that are becoming increasingly common in LLM-type models. First, the ability to reason, which refers to performing an iterative process to obtain the best possible answer, and second, model selection according to the tasks to be performed.
Comparison of the GPT-5 Model and the o3 Model, Highlighting Improved Response Quality
The capacity for reasoning became evident when looking for alternatives to improve responses, given the limitations of having less and less material to train new models and the diminishing returns of accumulating more training data between their versions. This reasoning process involves breaking down the user’s request into intermediate steps, checking the response at the end to ensure that a correct conclusion is reached.
The effectiveness of reasoning-based models became very popular with the models fromDeepSeek, which still offers access to its models for free by registering on its portal, through a ChatGPT-like chat page. This is mainly because DeepSeek compared its models’ output to the best from OpenAI, with the difference being free access. Today, the version of DeepSeek’s models is at version 3.
It seems that reasoning is the way to go for now, as companies like Google have implemented this same approach in their latest 2.5 models and even created different versions that mirror the path taken by OpenAI.
Another extremely popular company in the AI model world is Anthropic, which with its Sonnet and Opus models, also based on reasoning, has gained significant popularity, especially among programmers, having a context window from 200,000 tokens to an impressive one million tokens for certain organizations.

The above are just some of the main providers of LLM models, although the list is quite extensive with competitors like Grok from xAI, Mistral, Llama from Meta, Phi from Microsoft, among others.
Improvements in the Context Window
The reasoning capabilities of AI models would not be as efficient if they couldn’t handle an increasingly larger context. The context window refers to the amount of tokens a model can manage when sending a request, in addition to the text returned as a response. A reasoning process involves many steps in the chain of thought, so it’s essential to handle increasingly larger contexts.
The increase in context windows results in something positive for users, allowing them to perform complex tasks like refactoring programming projects or synthesizing large datasets in a single execution. Models like those from Gemini speak of an upcoming context window of 2 million tokens, while other models like those from Grok already have it available in their reasoning models.
Mixture of Experts Architectures
One question you might ask yourself is, how do companies make their models faster? They actually use different techniques, many of which are secret to maintain an advantage over their competitors.
One known technique is the architecture called Mixture of Experts (MoE), which is an architecture composed of subnetworks called “experts,” specialized in different areas. This architecture allows for the selection of the ideal experts for a certain task, for example, to solve a mathematical equation or create a program. As a result, you get a high-quality response while using only a fraction of the total model.
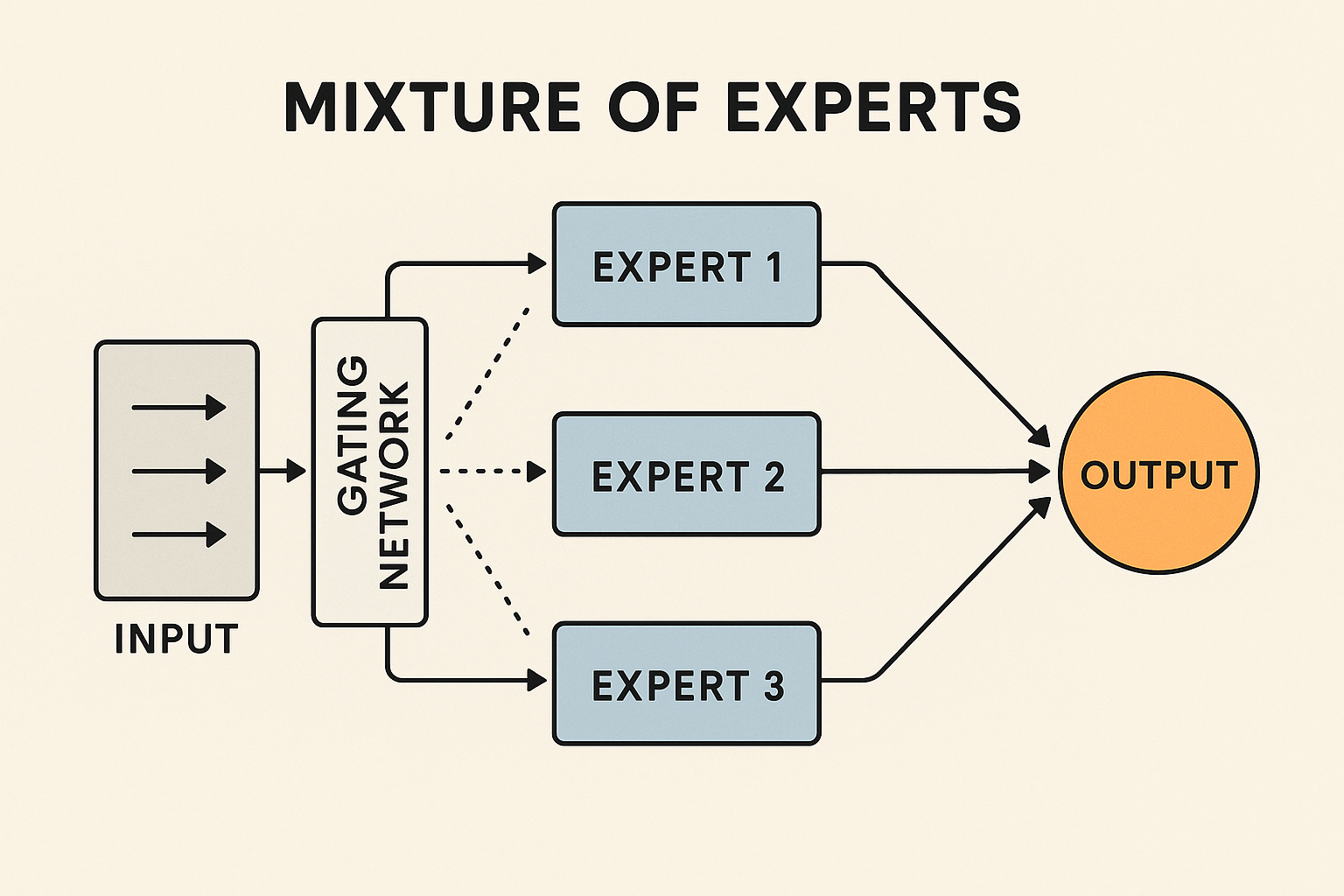
There are companies that have publicly admitted to using this technique in their models, such as Google with its Gemini models, xIA with its Grok models, among others. Although OpenAI has not publicly stated that it uses this architecture in its private models, it is believed to do so because its open-source models are based on this architecture.
Multi-Modal Capabilities in LLM Models
Another great advantage of the more recent models is that they are multi-modal. This means that they not only understand and return text, but they can also take documents, images and audio files as input. This represents an incredible improvement, as we can think of them as models that besides thinking, can see and hear.
With this feature, it is possible to provide a model with an image, which increases the context about a problem we want to solve; for example, providing a diagnosis on an X-ray or creating a prototype of an app, to which the model will respond better, saving us the effort of having to write out the content of the image ourselves, which indeed would be a significant challenge.
Image Generation Models
Not only have LLM models seen significant advances over the years. Another type of model that became popular thanks to OpenAI and its Dall-E models were image models.
On the site of the first version of Dall-E, it is still possible to find how the images generated by these early models looked:

It may even be surprising today to believe that it was generated by AI, but back in 2021, it was fascinating to be able to create images without being an expert in using specialized design tools and graphic knowledge. OpenAI’s latest model is called GPT Image 1, which has capabilities like modifying an image by adding details, generating the image with a transparent background, as well as selecting quality and size using pre-established values. Using the same prompt of the snail, I generated this image that allows us to verify the leap in quality regarding image generation.

Along with the evolution of OpenAI models, more companies joined the competition. One of the most well-known to date is Midjourney, which has always offered image generation with detailed textures, making it an excellent model for generating hyper-realistic photographs.
Another company specializing in image generation is Black Forest, which became popular with its Flux.1models that allow the creation of variations of an uploaded image, usually maintaining consistency with the objects in the image.
Lastly, the Gemini 2.5 Flash Imagemodel became quite viral as it allows modifying an image in just seconds, in addition to allowing multiple images to be input to create a completely new image taking the context from the input images while maintaining the consistency of the elements.
Video Generation Models
With the evolution of image models, the next natural evolution had to be in video generation. If someone had told me that in just a couple of years, we would move from seeing a deformed Will Smith eating spaghetti to having video shorts with people talking that look real, I wouldn’t have believed it.
Today, it’s impressive what companies like Google, with their Veo models, and OpenAI with its recent Sora 2 model have achieved by allowing the creation of high-quality videos, almost indistinguishable from those made by professional video companies. One of the features behind this is that they allow generating videos with sounds and people speaking, marking a milestone in video generation.

Another company doing impressive work in this field is Runway with its models Gen-4 and Aleph. The latter model allows edits on an existing video using only prompts, such as changing the style, adding objects, modifying a scene, generating new scenes while keeping objects, changing the angle of a shot in the video, among many other experiences.
In addition to them, there are other companies that also generate high-quality videos with high adherence to prompts, but still without the generation of audio or video editing. Among the most significant are Minimax with the models Hailuo, KuaishouTechnology with Kling AI, ByteDance with Seedance , and Alibaba Cloud with Wan.
TTS Generation Models
Another type of model that has evolved incredibly is one that allows generating voice from text. It is becoming increasingly difficult to detect an audio file generated by an AI model, as companies like ElevenLabs with their model ElevenLabs v3 are creating models that can integrate emotions into audio outputs. Other companies like OpenAI with their model GPT-4o mini TTS, Google with their models Gemini 2.5 TTS, or Hume AI with Octave 2 have not stood idly by and allow adding a prompt to guide the output generation, specifying details such as tone, punctuation, emotions, etc.
Conclusion
Throughout this article, we have explored the state of the art in different categories related to AI models that are making a difference today. From text generation to image, video, and high-quality audio generation, we must use the content generated by AI models with great responsibility. We should see these models as allies that enable us to achieve goals that previously seemed impossible for some, considering that they will continue to improve over time, becoming cheaper and more accessible to use.

