
We’ve been doing a lot of work with Medicaid (payer) data, and using FHIR more and more lately — even for persistence (!). This blog post covers some things we have learned, with specific techniques to make FHIR useful for storing healthcare data.
Our team is supporting Medicaid customers, so we focus on payer data — which provides challenges since FHIR is more oriented toward clinical data. Our approach is successful so far, and what we’ve done should be useful to anyone looking to store or simplify FHIR data, including clinical data.
The solution we’ve developed is evolving with every sprint, and new capability is still being added. Our initial release has made us confident that the approach will be valuable to both our own customers and data modelers and NoSQL implementers alike – even those who don’t work with MarkLogic.
Our initial work is part of MarkLogic’s Medicaid Starter Kit, which is being released in beta around the time this blog is being written. You can view the current version of the accelerators at the GitHub links at the end of this blog post.
Background — the Medicaid Accelerators
The reason we need a standardized persistent model at all is that we are building the MarkLogic Medicaid Starter Kit. This is our second Medicaid Accelerator, and like most Accelerators, ours are partial solutions that allow our partners and customers to move faster, as they customize and extend data models and processing; that is, we provide a starting point, not an end point.
Our desired, medium-term scope for the Starter Kit is:
- A starter data model, comprising five FHIR data domains
- Some sample input data
- Mappings from the sample data to the canonical FHIR data model
- MDM: Matching, merging, and deduplication to create a Master Person Index (and perhaps also a Master Provider Index)
- A security model covering PII, PHI, and other role-based access at the property level
- Data lenses (“TDEs”) that create analytic data projections into SQL
- De-identification rule sets (“redaction rules” in MarkLogic parlance)
- Quality and data cleanup rules
- Schemas and validation steps
- Data services or transforms for data consumption — APIs and bulk export
- HAPI FHIR data integration to facilitate CMS mandated interoperability, per the Final Rule
We need a data model
Early on, we realized that none of these items can be standardized without first standardizing an underlying data model. The more our customers and partners share a data model, the more they can share all the artifacts above. So, having a standard model is the first step in creating a range of sharable, pre-built configuration and code artifacts for the community.
For example, MarkLogic MDM rules are stated in terms of the canonical model — e.g., one rule may be that: if the SSN, Family Name, and Date of Birth are the same, two records are flagged as duplicates. These rules are stated in terms of the properties in the Member or Patient records, so having property names and structure is needed to state the rule.
Similarly, the security model indicates which individual data properties are secured by which roles (e.g., only people with the PII-Reader role can access givenName,familyName, and all Identifiers). Redaction rules, quality or validation constraints will refer to the data models as well.
FHIR to the rescue
A number of our customers have directly stored JSON FHIR records in MarkLogic, or modeled their data based on FHIR, over the years with mixed results.
The bad news is that pure FHIR data models are too complicated and deeply nested to be great persistence models. But the good news is that we have seen enough attempts, workarounds, and issues to know how to address the problem. Below, we outline our approach to making FHIR a good persistence model.
Our Data Modeling Prime Directive: The data model will be simpler than FHIR, but can be mechanically mapped into true FHIR formats if needed, and transparently relates to the official FHIR spec.
This provides a number of advantages:
- Users and developers can understand the model if they are familiar with FHIR
- While our simplified model is not exactly FHIR, every field in our starter model relates to a FHIR element, which makes the FHIR documentation relevant to our model too
- FHIR often provides “many ways to do it” which can be confusing, and lead developers or data experts to make mistakes — such as confusing the text, code, and display elements in a complex FHIR structure — but we strive to provide one “code” value to set
- We can (and will) build a mechanical, configuration-driven transform to convert our simpler model into the more complex FHIR model, if true FHIR records are needed to interoperate with standard tools
- Much of the thinking and maturity of the FHIR spec accrues to our simpler model
Why is the FHIR model not already ideal for persistence?
FHIR is an interchange format — or message format as I like to think of it. It is built for completeness, flexibility, and web use. This message bias shows up largely in the use of codable concepts where the coding system is variable and can be arbitrary. Codings include both a system that defines the code together with the actual code, so someone with type II diabetes may be represented in many ways, such as:

or

(bold parts show the differences in the two)
However, these structures are verbose and make queries difficult — what would one query on to find people with diabetes? A persistent model is better if the codes and system are standardized (meaning the coding system is implicit and uniform).
So we would rather store:
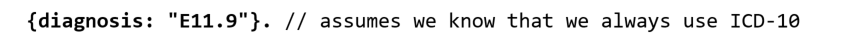
which is simple, easy to query, space-efficient, and easier to deal with in mappings, parsing, validation etc. as well. Working with dozens of nested structures in pure FHIR is a constant tax on all work done with these models.
MarkLogic specifics in these data models
In some ways, the approach and the specific sample models in our Starter Kit are generic, and useful for anyone storing FHIR data. In other ways, they are probably specific to MarkLogic, e.g., MarkLogic is a multi-model data store, natively built to integrate four main data models and access patterns:
- JSON data
- Text search on semi-structured or unstructured data
- Triple store capability for RDF and knowledge graph handling, and ontologies
- SQL data projections (read-only) for analytics
We know this simple model works well in MarkLogic, and supports a wide variety of use cases including basic query, text search, extracting knowledge graphs for RDF and semantic reasoning, etc.
However, other data technologies are less fully-integrated, requiring many data stores to accomplish what MarkLogic does. If using many data stores, or if the JSON handling capabilities and query are weaker, this model may need to be adjusted. Nonetheless, I’m hopeful and confident that this work will be useful to people using a variety of tech stacks.
The technical approach
To really review the technical approach, you should download the MarkLogic Medicaid Starter Kit and give it a spin, but the basics are simple.
For clarity, call our persistent model ES-FHIR and refer to the actual FHIR spec as “True FHIR” where there may be some confusion. The key, conceptual equation is:
ES-FHIR + Metadata = True FHIR
In the example above, we store a single code of “E11.9” as the “diagnosis” which is quite simple. The property name “diagnosis” matches the FHIR property of “diagnosisCodableConcept” so even as we store a simpler structure than FHIR defines, the naming convention tells us that “diagnosis” represents and maps to the FHIR “diagnosisCodableConcept” structure. So we already have two parts of the puzzle: this is a code (as documented by the related FHIR definition) and the code is E11.9.
The remaining/missing information (the “Metadata” in the equation above) is constant, and does not need to be stored in every document. Namely:
- Which coding system are we using?
- What is the display text corresponding to ICD-10 code E11.9?
- … and perhaps a few other things we are not including in this blog example for brevity
Both of these can come from static reference data. The mapping of ICD-10 codes to display text is in the public ICD-10 ontology. MarkLogic natively stores and queries RDF, OWL, and ontologies using SPARQL, so we can import the ontology and look that up if anyone needs the data in an outgoing query or process.
The coding system is even simpler — we are storing everything in ICD-10, so that can be looked up in a metadata configuration file for lookup whenever needed.
Finally, we know the structure of a FHIR Codable concept, so we know how to format all this as JSON if we ever need the “True FHIR” JSON format reconstructed, e.g. for interoperability purposes.
How will we store this metadata that allows us to restore the full FHIR complexity when and if needed?
A notional metadata file
The accelerator is built to allow a simple and mechanical mapping to fully-compliant FHIR APIs. This is still in development, but the approach is illustrative of the power of using modified FHIR for persistence. (Note that MarkLogic natively supports RDF, ontologies, and SPARQL, so we can directly use SPARQL syntax to specify the technique of looking up reference data like display names in RDF representing ICD-10.)

If you take a minute to study it, you can see that the persistent format holds the critical, record-specific information — which is only the ICD-10 diagnosis code — and the rest is static reference data from our metadata structure together with the existing ICD-10 ontology information.
To help this along, we have imported much of this reference data directly from the HL7 FHIR website.
Other simplifications
The approach for simplifying codable concepts above also works for other complex structures, such as Identifiers, References, FHIR metadata sub-objects, and the like. A simple, scalar persistent field is used, and a naming convention helps us associate our “ES-FHIR” properties with True FHIR properties in the spec — but if and when we transform to True FHIR on egress we will add the full complexity back in using reference data structures.
This blog is getting a little long, so I’m not going to sketch out Identifiers or others here. The point is that we have found that “flattening” or simplifying codable concepts, identifiers, and other structures provides a lot of utility, and the other structures which we do not modify — such as addresses, telecom contact details, time periods, and the like — are already pretty simple and represent what we need rather well.
FHIR for payers
Healthcare payers have slightly different terminology, and a different scope from clinical data where FHIR originally matured. Is this a deal-breaker (we asked ourselves, and our partners)?
Fortunately, we have not found that to be an obstacle thus far. In the payer area, we think of people receiving care as “members” of Medicaid programs or insurance plans, but they are undeniably also “patients.” FHIR calls them patients, so we use the FHIR Resource Types as our data entity names as well, and that seems fine.
Often, additional fields or entire data resources must be added to cover all the data required in the payer space. In those cases, we simply do not have a FHIR model to base our model on, but the patterns and structures of FHIR still serve us well when modeling this additional data. We say we create “FHIR-like” models in those cases that have the naming conventions, structure, and look and feel of FHIR models.
Extensions and non-FHIR data
The astute reader may be asking — what about the official FHIR Extension mechanism for data that is not covered by the FHIR spec? For example, a customer recently discussed how they want to manage their Sanctions data. It is critical for Medicaid processing, fraud prevention, and monitoring to know who’s under a sanction, but FHIR does not cover sanctions.
FHIR does define an extension mechanism, but the resulting structure is far too complex for persistence. Therefore, for these additional types, we have prototyped using FHIR data types and substructures, but creating completely new models.
For example, we re-use the Period data type and will also use common substructures such as ContactPoint where needed and call that sub-object property “telecom” as is the convention in many FHIR resources — even when creating totally new resources such as Sanctions to support Medicaid programs.
Summary
We have seen challenges, along with our partners and customers, over the past few years in using FHIR effectively as a persistent data model. In response, we are distilling simplification techniques into a Medicaid Starter Kit with five starter models that map closely to five FHIR resources (hewing specifically to US Core IG v 4.0.0).
The benefits of using FHIR, but simplifying it for persistence, are substantial – by basing our model on FHIR, we avoid creating and maintaining a completely separate persistence model. By leveraging years or decades of work on FHIR, we avoid modeling missteps that are easy to make with healthcare data. When FHIR is required (e.g., by the CMS interoperability rule, or a system that uses FHIR for interchange) it is easy and mechanical to convert the efficient, simple persistence model into the fully-compliant FHIR model. Our related HAPI FHIR integration project illustrates this benefit.
The main trick is to take information that is constant from record to record — such as the coding system being used, display text, or other data already available in standard ontologies — and remove it to create persistent JSON record formats. Beyond stripping out repeated, static information, we also flatten the structure itself to simplify development and data processing.
This makes the persistent format (ES-FHIR) somewhat different from the message format (True FHIR) but in a mechanically reversible way. It gives us interoperability, maturity, and links to robust documentation — yet preserves efficiency and readability.
The beta version of the Medicaid Starter Kit holds the first of these models, and we will evolve and refine them more over time as we extend and harden the Starter Kit. I hope people take a look, and if starting a new MarkLogic project around healthcare data, use these as their own starting point.
We look forward to hearing from you and collaborating as you do that.
Download the Code
All the materials you need to get started are available on GitHub:

