
私たちはこれまで、メディケイド(保険者)データを使った作業を数多く行ってきましたが、最近はFHIR(読み方は「ファイア」)の利用が増えてきています。驚かれるかもしれませんが、これはパーシステンス(データの永続化)にも利用されるようになっています。本ブログでは、私たちがこれまでに学んだことをご紹介します。特にヘルスケアデータの格納においてFHIRを有効活用するための具体的なテクニックを取り上げます。
私たちのチームはメディケイドカスタマー担当で保険者(保険業者)のデータを扱うことが多いですが、FHIRはどちらかというと臨床データ向きなため、課題もあります。しかしこれまで私たちのアプローチはうまくいっているので、私たちがやってきたことは、FHIRデータ(臨床データを含む)を格納したりシンプル化したい人にとって参考になると思います。
この業務のためのソリューションを私たちは開発しましたが、これは各スプリントごとに進化しており、新しい機能が未だに追加され続けています。この初回リリースは、これまでMarkLogicを使ってきた方にもそうでない方にとっても、データモデリングやNoSQL実装の際に役立つことは間違いないと思います。
これは、「MarkLogicメディケイドスターターキット」(本ブログの執筆時にベータ版がリリースされています)の一部となります。このアクセレレーターの最新バージョンは、本ブログの最後にあるGitHubリンクから確認いただけます。
背景:メディケイドアクセレレーター
パーシステンス(永続化)の標準モデルが必要になったのは、「MarkLogicメディケイドスターターキット」を開発していたからです。これは私たちにとって2つめのメディケイドアクセレレーターですが、他のほとんどのアクセレレーターと同様、これはパートナーやカスタマーがデータモデルおよび処理をカスタマイズし拡張することで活動を加速するための、部分的なソリューションです。つまりこれは一連の活動の開始地点であり最終目標(完成形)ではありません。
このスターターキットにおける、私たちが望んでいる中期的スコープは以下のようになります。
- スターターデータモデル(FHIRの5つのデータドメインを含む)
- 入力データのサンプル
- このサンプルデータとカノニカルなFHIRデータモデル間のマッピング
- MDM: マッチング/マージング/重複解消による、Master Patient Index(およびおそらくはMaster Provider Indexも)の作成
- プロパティレベルでのセキュリティモデル(PII、PHI、その他のロールベースのアクセス)
- データレンズ(「TDE」)。SQLでの分析用データ射影を作成するもの
- 個人情報秘匿ルールセット(MarkLogicでは「リダクションルール」と呼ばれる)
- クオリティおよびデータクリーンアップのルール
- スキーマおよび検証ステップ
- データ利用のためのデータサービスおよび変換(APIおよび一括エクスポート)
- CMSによって決められている相互運用性(「ファイナルルール」)のためのHAPI FHIRデータ統合
データモデルが必要
基となるデータモデルをまず標準化しないことには、上記の項目を1つも標準化できないことに、私たちは早い段階で気付きました。データモデルを共有する顧客やパートナーが増えるほど、共有可能な上記のあらゆるものがさらに増えます。このように、標準モデルを持つことが、コミュニティにおいて共有可能なさまざまな事前構築済みのコンフィギュレーションやコードを作成する際の第一歩となります。
例えば、MarkLogicのMDMルールは、カノニカルモデルとして記述されます。ルールの一例としては、「2つのレコードにおいて社会保障番号、姓、誕生日が同じ場合、重複としてこれらにフラグを立てる」などがあります。これらのルールは、Member(会員)あるいはPatient(患者)というレコード内のプロパティとして記述されます。このため、ルールの記述には、プロパティの名前および構造が必要です。
同様に、セキュリティモデルにおいても、どのデータプロパティがどのロールによって守られるのかを指定します(例:PII-readerロールの人だけが、givenName、familyName、あらゆるIdentifiersを確認できるなど)。リダクションルールやクオリティ、検証の制約などもこれらのデータモデルを参照します。
FHIRによる助け
私たちの顧客の多くは、JSON形式のFHIRレコードを直接MarkLogic内に格納しています。あるいは、FHIRに基づいてデータをモデリングしています。こういった長年の取り組みの成果はさまざまです。
悪い知らせとしては、純粋なFHIRデータモデルは、優れたパーシステンス(永続化)モデルとして使用するには複雑すぎる(深い入れ子状になっているなど)があります。しかし良い知らせとしては、私たちがこれまでさまざまな試み、回避策、問題点の検討を十分行ってきたことにより、こういった課題への取り組み方を学べた、ということがあります。次に、FHIRを優れたパーシステンスモデルとするための私たちのアプローチの概要をご紹介します。
私たちのデータモデリングにおける「最優先指令」:このデータモデルは、現時点でもそして将来もFHIRよりシンプルです。しかし必要に応じて真のFHIR形式に機械的にマッピングしたり、FHIRの公式仕様に透過的に関連付けることもできます。
これには、多くのメリットがあります。
- FHIRに詳しいユーザーや開発者はこのモデルを理解できます。
- 私たちのシンプル化されたモデルは、厳密にはFHIRではありませんが、このスターターモデルの各フィールドは、FHIR要素に対応しています。これによりFHIRの解説文書を私たちのモデルでも利用できます。
- FHIRは同じことをやるのに大量の方法があることが多いので、かなり混乱します。またそのせいで開発者やデータエキスパートが間違いやすくなっています(テキストやコードがわかりにくかったり、要素が複雑なFHIR構造内で表現されるなど)。一方私たちは、規範的な「コード」値を1つ設定するようにしています。
- 標準的なツールとの相互運用のために真のFHIRレコードが必要な場合、このシンプルなモデルをコンフィギュレーションに基づいて、複雑なFHIRモデルに機械的に変換できます。
- FHIR仕様の考え方および成熟度の多くの部分は、私たちのシンプルなモデルにも反映されています。
FHIRモデルが未だにパーシステンスには理想的でない理由
FHIRはデータの相互交換形式です。あるいはメッセージ形式と考えても良いかもしれません。これは、完全性、柔軟性、webでの利用を目的として作られています。このようなメッセージのバイアスは、多くの場合、CodeableConceptの利用において出現します。この場合、コーディングシステムは可変的でランダムな可能性があります。コーディングにはコード定義システムと実際のコードの両方が含まれています。このため2型糖尿病の人を表現する方法はたくさんあります。以下のようになります。

あるいは

(2つの違いを太字で表しています)。
しかしこれらの構造は冗長であり、「糖尿病患者を探す」のようなクエリが困難です。コードおよびシステムが標準化されていた方が(つまりコーディングシステムが暗黙的で単一化されていた方が)、パーシステンスモデルは良いものとなるでしょう。
このため以下のように格納した方が良いです。
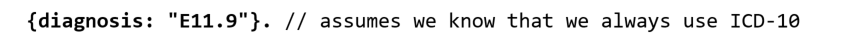
これはシンプルでクエリが楽です。またスペースも取りませんし、マッピング/パーシング/検証などにおいても扱いが楽です。純粋なFHIRに見られる数十もの入れ子構造は、モデルに関するこういった作業において常に負担となります。
これらのデータモデルにおけるMarkLogicの仕様
私たちのスターターキットのアプローチおよび個々のサンプルモデルは、ある意味極めて一般的なので、FHIRデータを格納するあらゆる人の役に立つでしょう。一方、これにはMarkLogic固有の部分もあります。これは、MarkLogicは「マルチモデル」のデータストアであり、以下のような4つのデータモデル/アクセスパターンをネイティブに統合できるように作られているためです。
- JSONデータ
- 半構造/非構造化データに対するテキスト検索
- トリプルストア機能(RDF/ナレッジグラフ/オントロジー用)
- 分析のためのSQL用データの射影(リードオンリー)
私たちはこのシンプルなモデルがMarkLogicではうまく行くことを確認しています。これはさまざまな使用シナリオ(基本的なクエリ、テキスト検索、RDFおよびセマンティック推論用のナレッジグラフの抽出など)に対応しています。
一方、他のデータテクノロジーはこれほど統合が進んでいないので、MarkLogicと同等のことを実現するには、数多くのデータストアが必要になります。多数のデータストアを使用する場合、あるいはJSON対応機能やクエリが弱い場合は、このモデルを修正する必要があります。いずれにせよ、さまざまなテクノロジースタックを使っている人にとってもこれが役に立つことを願っていますし、お役に立てることに自信を持っています。
テクニカルなアプローチ
このテクニカルなアプローチを実際に確認したい方は、MarkLogicメディケイドスターターキットを自分でダウンロードして試してみてください。いずれにせよ、この基本はシンプルです。
区別するために、私たちのパーシステンスモデルを「ES-FHIR」、また実際のFHIR仕様を「真のFHIR」と呼ぶことにします。ここで、主要な概念の方程式は次のようになります。
ES-FHIR + メタデータ = 真のFHIR
上記の例では、「E11.9」という1つのコードを「diagnosis(診断)」として格納しています。これはいたってシンプルです。このプロパティ名「diagnosis」は、FHIRのプロパティ「diagnosisCodeableConcept」に対応します。つまりFHIRの定義よりシンプルなものとして格納しても、この「diagnosis」はFHIRの「diagnosisCodeableConcept」構造のことであり、これにマッピングできることが命名規則によりわかります。このように、ここにはすでに2つの部分が存在します。つまりこれはコード(関連するFHIR定義によってすでにドキュメント化されている)であり、このコードはE11.9だということです。
残りの欠けている情報、つまり上記の方程式内の「メタデータ」は定数であり、すべてのドキュメントに格納されている必要はありません。具体的には以下のものがあります。
- ここで使用しているコーディングシステムは何か?
- ICD-10コード「E11.9」に対応する表示テキストは何か?
- …そして、このブログでは紙幅の都合上取り上げないようなものが、おそらく他にもいくつかあります。
これらは両方とも静的なリファレンスデータから来ています。ICD-10コードと表示テキストのマッピングは、公開されているICD-10オントロジー内にあります。MarkLogicはRDF、OWL、オントロジーをネイティブに格納・クエリできます(SPARQLを使用)。このためオントロジーをインポートしておくことで、その後のクエリや処理において必要なデータをルックアップできます。
このコーディングシステムはさらにシンプルです。私たちはすべてをICD-10として格納しているため、必要な際にこれをメタデータ構成ファイル内でルックアップできます。
最後になりますが、私たちはFHIRのCodeableConceptの構造を知っているので、JSON形式の「真のFHIR」を再構築しなければならない場合(相互運用のために)、これらすべてをJSON形式にフォーマット化できます。
それでは、複雑なFHIRを完全にリストアする必要がある場合の準備として、このメタデータをどのように格納しておいたら良いのでしょうか。
概念的なメタデータファイル
このアクセレレーターは、完全準拠型のFHIR APIにシンプルかつ機械的にマッピングできるように作られています。これはまだ開発段階ですが、このアプローチを見れば、修正されたFHIRをパーシステンスに利用するメリットが理解していただけると思います(注:MarkLogicはRDF、オントロジー、SPARQLをネイティブにサポートしています。このため、ICD-10を表現したRDF内の表示名などのリファレンスデータのルックアップ手法の指定に、SPARQLシンタックスを直接使用できます)。

ちょっと見ると、このパーシステンス形式にはレコード固有の重要な情報(ICD-10の診断コードのみ)が含まれており、残りは私たちのメタデータ構造からの静的なリファレンスデータおよび既存のICD-10オントロジー情報であることがわかります。
ここではこの方法を実現するために、こういったリファレンスデータのほとんどをHL7 FHIRのwebサイトから直接インポートしてあります。
その他のシンプル化
CodeableConeptをシンプル化する上記のアプローチは、他の複雑な構造(識別子、リファレンス、FHIRメタデータのサブオブジェクトなど)でも利用できます。シンプルかつスカラーのパーシステンスフィールドが使用されており、また命名規則を利用することで、私たちの「ES-FHIR」を仕様内のFHIRプロパティに関連付けられます。また出力時に真のFHIRに変換しなければならない場合、リファレンスデータ構造を使用して複雑なものに完全に変換できます。
長くなってしまうので、本ブログでは識別子などについては取り上げません。ここで言いたいのは、私たちはCodeableConept、識別子、その他の構造を「フラット化」(シンプル化)したものが、さまざまな状況で利用可能なことを確認したということです。またここで修正していない他の構造(住所、電話連絡先、期間など)は最初からシンプルであり、私たちが求めるものがすでにきちんと表現されています。
保険者にとってのFHIR
ヘルスケアの保険者では、用語が若干異なります。また主要な対象となっているのは、元来FHIRが扱ってきた臨床データではありません。では私たちのやり方は、ここでは全くうまくいかないのでしょうか。これについては社内およびパートナーたちに確認してみました。
幸いなことに、今までのところ、これが問題となったことはないようです。保険者は、ケアを受けている人々をメディケイドプログラムまたは保険プランの「会員」と考えますが、彼らは間違いなく「患者」でもあります。FHIRはそれらをpatients(患者)と呼んでおり、私たちもデータエンティティ名としてFHIRリソースタイプを使用していますが、それはそれで問題ないようです。
多くの場合、保険者が必要とするあらゆるデータをカバーするには、フィールドまたは別個のデータリソースを追加する必要があります。このような場合、私たちのモデルの基礎となるべきFHIRモデルは存在しませんが、この追加データをモデリングする際には、FHIRのパターンと構造が役立ちます。つまり私たちは、FHIRモデルの命名規則、構造、ルックアンドフィールを備えた「FHIRライク」なモデルを作成することになります。
拡張および非FHIRデータ
鋭い読者の方なら、FHIR仕様でカバーされていないデータには、FHIRオフィシャルの拡張(エクステンション)を使うのはどうかと思うことでしょう。例えば、最近あるお客様がSanctions(制裁)データを扱いたいと言っていました。メディケイド業務において不正防止は重要であり、誰が制裁の対象になっているのかを監視する必要があるのですが、FHIRには「Sanctions」が存在しないのです。
FHIRでは拡張機能を定義していますが、その構造はパーシステンスにはあまりに複雑です。このため、こういった追加のタイプ用に、私たちはFHIRのデータタイプおよびサブ構造に基づいてプロトタイプを作成し、完全に新しいモデルを作成しました。
例えば、私たちはPeriodデータタイプを再利用し、また一般的なサブ構造(ContactPointなど)を必要に応じて使用しています。またこのサブオブジェクトプロパティを、FHIRの多くに見られる慣習に基づいて「telecom」と呼んでいます。この方法はメディケイドプログラム用にSanctionsのような全く新しいリソースを作成する際にも利用できます。
まとめ
この数年間、私たちおよび私たちのパートナーや顧客も、FHIRをパーシステンス用の(=永続化用の)データモデルとして効果的に使用するにはさまざまな課題があることに直面してきました。これらの問題に取り組むため、私たちはシンプル化の技術を高めることで、5つのFHIRリソース(特にUS Core IG v 4.0.0対応)のそれぞれにきちんと対応する5つのスターターモデルを備えたメディケイドスターターキットを作成しました。
FHIRをパーシステンス用にシンプル化するメリットは極めて大きいです。私たちのモデルはFHIRに基づいているので、完全に別個のパーシステンスモデルを作成・維持する必要がありません。またこれは数十年にわたるFHIRの経験に基づいているため、ヘルスケアデータのモデリングで発生しがちなミスが起こらないようになっています。FHIRが必要な場合(たとえば、CMS相互運用性ルールに準拠するため、あるいはデータ交換にFHIRが必要なシステムで利用するなど)、この効率的でシンプルなパーシステントモデルを、完全準拠のFHIRモデルに簡単かつ機械的に変換できます。これに関連する私たちのHAPI FHIR統合プロジェクトには、このメリットが現れています。
ここで肝となるのは、複数のレコード間において共通する情報(使用されているコーディングシステム、表示テキスト、また標準オントロジーにすでに存在している他のデータなど)を把握することです。これらを削除することで、パーシステントなJSON形式のレコードを作成しています。繰り返し登場する静的な情報を削除しただけなく、構造をフラット化することで、開発やデータ処理がシンプルになっています。
このように、このパーシステンス形式(ES-FHIR)は、メッセージ形式(真のFHIR)と若干異なっていますが、機械的に真のFHIRに戻すことができるので相互運用性および成熟度がもたらされます。またしっかりとしたマニュアルも備わっており、効率性や可読性も保持されます。
メディケイドスターターキットのベータ版には、こういったモデルの第一弾が含まれています。今後、このスターターキットを拡張・強化し、進化・精緻化させていきたいと考えています。これをぜひ実際にご確認ください。そしてヘルスケアデータを扱う新規のMarkLogicプロジェクトの際には、これを基にしていただければと思います。
皆様からのご感想をお待ちしております。またコラボレーションの依頼もお待ちしております。
コードをダウンロードする
始めるために必要な素材は、すべてGitHubにあります。

