
This is part 2 of our series on analytics and time series data in MarkLogic. The images shown are from a partner’s application, called Epinomy, which has been loaded with economic indicators data. Epinomy was built on MarkLogic and takes advantage of our support for both a document database and triple store.
Query Expansion
In part 1, we showed how analysts can modify the associations between economic concepts using Epinomy’s Concept Manager. Epinomy provides a peek under the hood to see how these concept associations are used in the search. This allows subject matter experts to quickly correct any false associations. Now we will look at how to expand queries. Here is an example of how the phrase “France GDP 2010” is expanded under the hood:
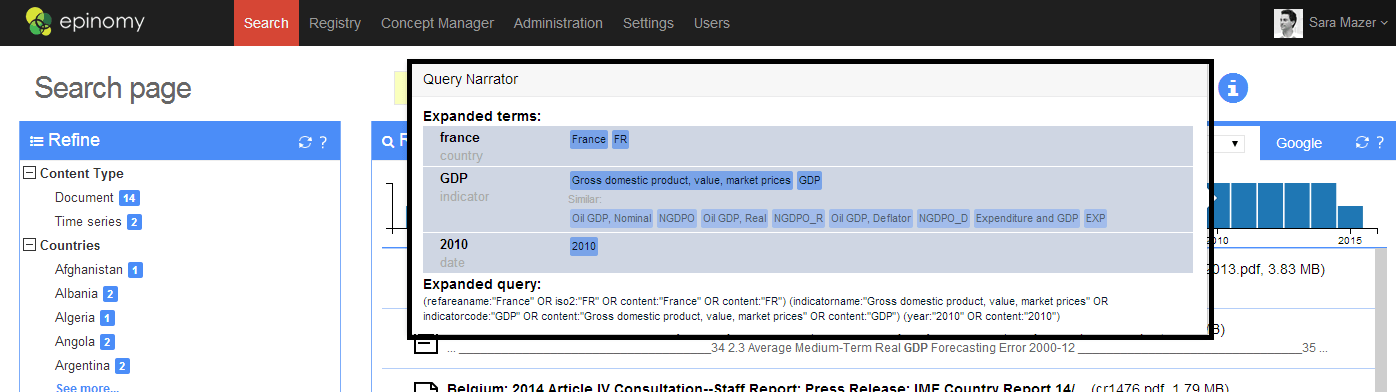
France is expanded to its ISO-2 code FR, GDP is expanded to “Gross domestic product, value, market prices” and we also know that indicator is similar (through associations in the triple store) to such concepts as NGDPO_R, NGDPO_D, and so on.
ETL
Of course, MarkLogic supports ETL, too. It can certainly transform the data as it is loaded in, or after, if a new name or data model is desired. Because MarkLogic has integrated search, as soon as the data is transformed it is available for searches. In analytics organizations, sometimes MarkLogic is used exclusively to bring in data from various sources and then transform it on export into specific formats required by legacy systems, such as for additional analysis or archival.
MarkLogic can store the entire dataset or it can function as a metadata repository. Users can search the metadata repository and MarkLogic can send web service requests to pull the entire dataset from a legacy or licensed system if needed. In the case of time series data, often the overhead of storing the values is small compared to the amount of metadata. So, it makes sense to try and keep in all in the same place. However, economic databases may be licensed in such a way that prohibits the values from being stored, and in those cases MarkLogic can manage the communications to those systems.
Data as a Service / Keeping External Data Up To Date
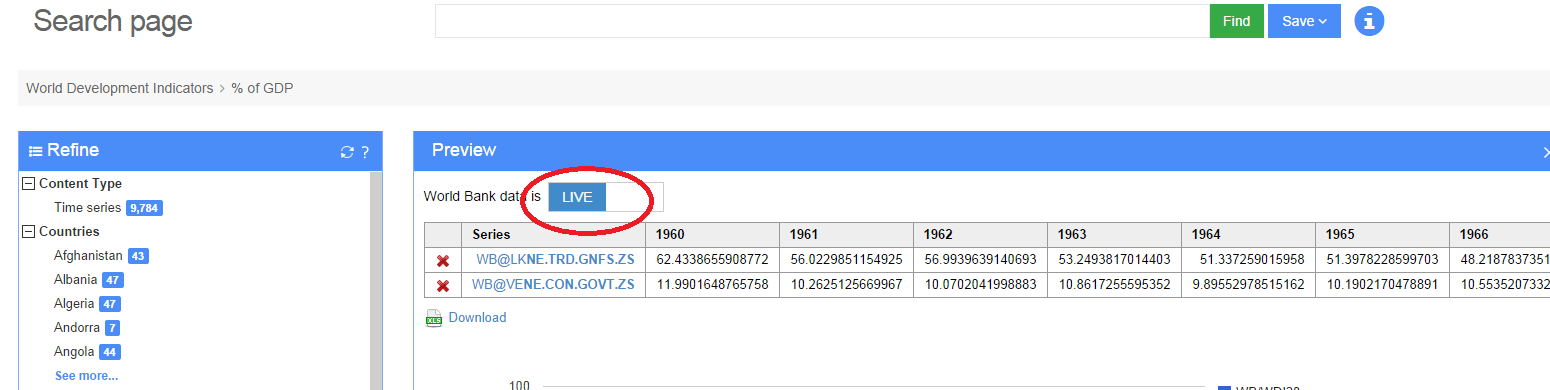
MarkLogic will provide your data as a service regardless of where it is on the network or cloud. Because time series data often changes frequently, a problem can occur when you are not the owner of the data. An external organization might publish data and you may find what is in your database is stale. For example, revisions occur frequently in economics. Because MarkLogic is an application server, it can accept push feeds via web services, or be scheduled to regularly check for new data. In addition, the Epinomy team built in a nice “live” toggle button as a “sanity checker” that when pushed, sends out a web service request immediately to check for, and import, any new data:
Search Faceting on Time Series Data
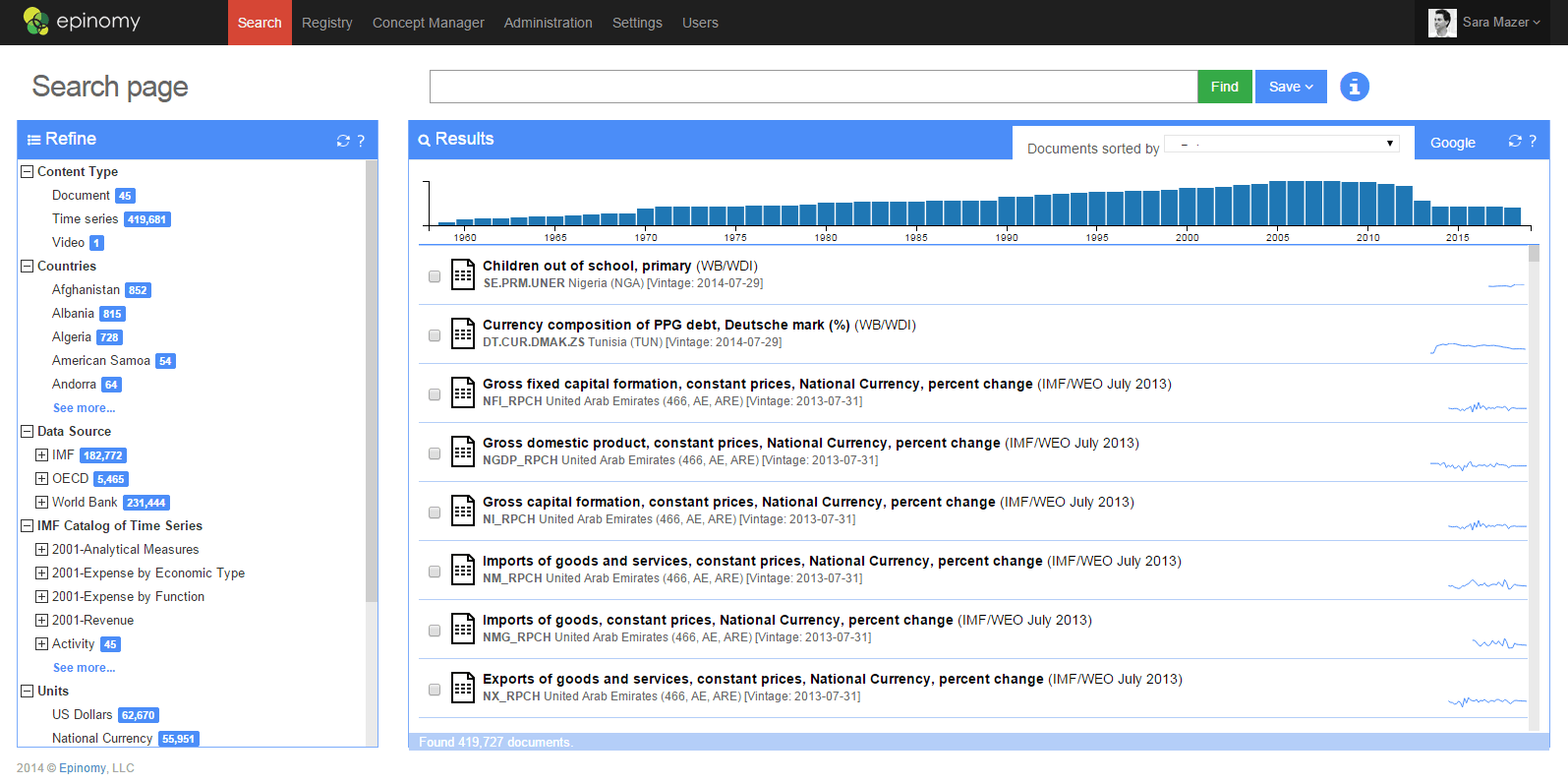
Once we have the data loaded, users want to search their data and perform additional analytics. In Epinomy, we have faceted searching of time series and related data organized by taxonomies loaded into the Taxonomy Manager. The facets are mainly driven by triples and are truly dynamic. For example, if an analyst is researching an economic term that is only published by a certain world organization, all other facets that pertain to other organizations disappear. Facets can also come from the data itself, such as units used for the values (e.g. percent of GDP). A facet is driven by range indexes, and is really the building block of most analytical functions in MarkLogic.
In addition to faceted searches, a search bar provides the support for ad-hoc queries. Since we are dealing with time oriented data, an interactive histogram allows for quick selections of specific time periods to constrain the search. Below the histogram are snippet results of either the economic indicator data itself, with a preview of the indicator over time in a sparkline, or snippet results of unstructured data such as publications or video.
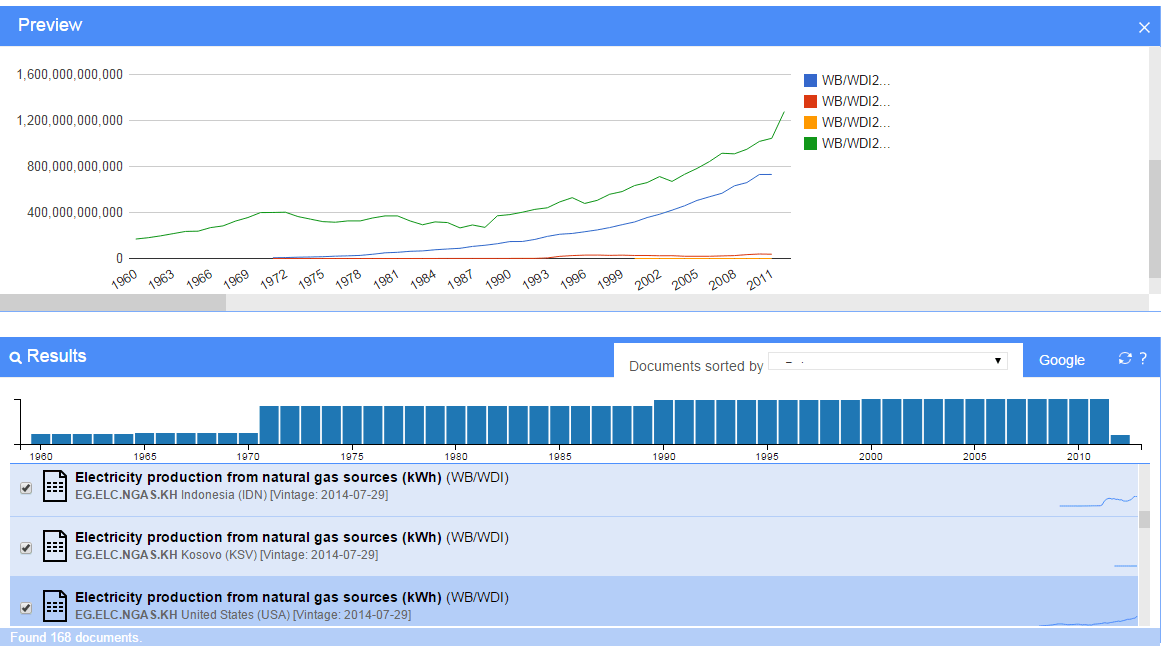
When indicators are selected, a line chart appears to ease comparisons of data and this data can be easily exported to a spreadsheet like Excel for additional manipulation. Here’s what the line chart looks like in Epinomy.
Third-Party Analytics
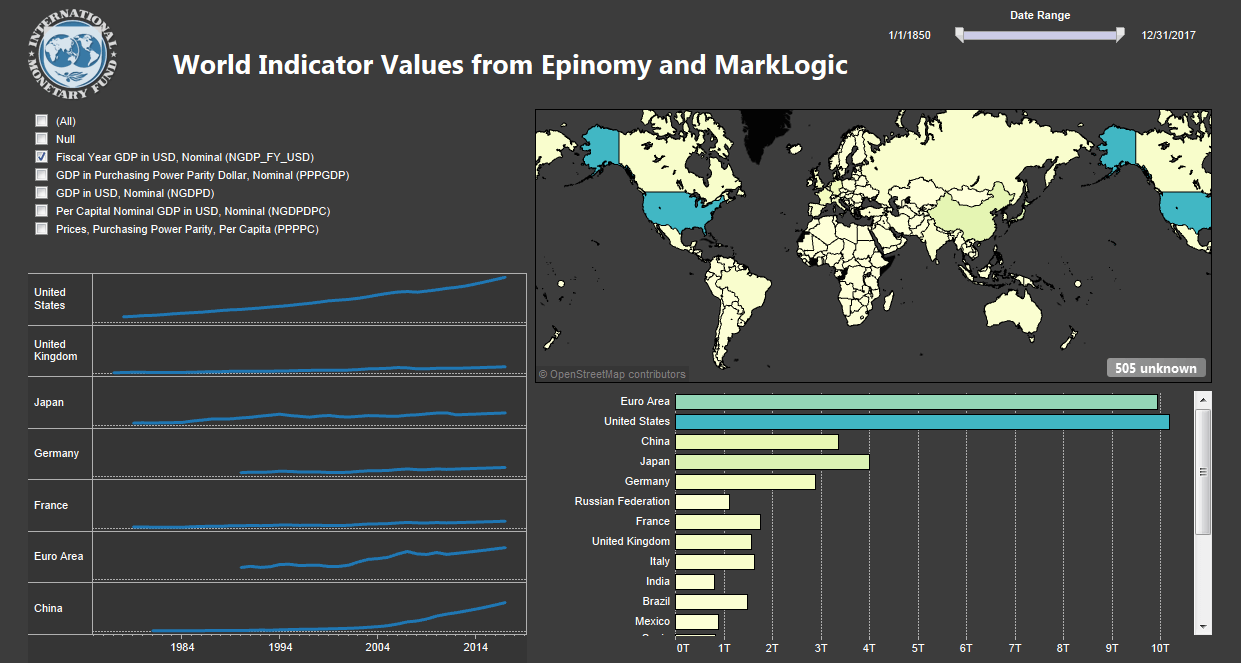
MarkLogic can perform analytics and support charts, graphs and maps directly. However, some analysts have legacy third-party tools they want to continue using. MarkLogic is a NoSQL database in the real sense of “Not Only SQL” because it can look like a relational database to external analytics applications. BI tools such as Tableau, SAS, or Excel (really any tool that has an ODBC connection) can work with MarkLogic by sending SQL through ODBC. For our application’s use case, we were asked to show integration with a third-party tool such as Tableau. Tableau is another MarkLogic partner that recently built in a custom MarkLogic connector, so we connected Tableau and built a dashboard:
Data Modeling for BI
We found it best to have an indicator’s values over time be stored in the same document for search and sparkline visualization performance. However, when you want to connect tools that can only understand SQL such as Tableau, you should model your data with these tools in mind. Following the Guidelines For Relational Behavior, you should try to avoid repeating element names that will be measured in a BI tool in the same XML (or JSON) document. Therefore, each value/time pair should be in its own XML (or JSON) document.
Our friends at Epinomy spent a great deal of time determining the optimal way to model time series and related data in MarkLogic. Modeling time series in entirely in triples (we used a model similar to SKOS SDMX by Sarven Capadisli as our guide) was tried, but in our use case the data needed to be sliced in so many dimensions (source, version, date, country, etc) that the number of joins in SPARQL ended up not being the most efficient method. Modeling time series in XML using range indexes provided the best performance and also supports the “views” that the BI tools use.
Flexibility in Storage and Support of Applications
MarkLogic provided our partner the flexibility to choose the best method of storage and the flexibility to easily modify the data models. Epinomy has a hybrid approach in its data model to support both search and BI, with a comprehensive indicator document and several small indicator value/time documents. Economic indicator values that are designated as equivalent are managed in the thesaurus, and otherwise related terms are managed using MarkLogic’s triple store. Countries and groupings are modeled using triples. Associations between unstructured and the structured time series are also managed in the triple store. In all, MarkLogic provided a great foundation to support both search and analytics due to its capability to store structured and unstructured content and link data together using its triple store.
For more information, contact info@marklogic.com and check out our partner Epinomy’s site and be sure to watch their video!

