
Welcome to 2015! The New Year is a time to take stock of lessons learned in previous years and plan for the future; perfect to evaluate what is working well and not so well — in life and business. Understanding the past and trying to predict the future is what analytics is all about. Sometimes with careful analysis you can catch a single event, a tipping point (as Malcolm Gladwell famously wrote), which takes you in another direction. It could be a simple bold move such as an investment in a new technology like NoSQL that leads to new insights or revenue streams. We’re going to look at how economic indicators can be better analyzed – faster and easier — using Enterprise NoSQL.
 Change is often scary and made when continuing with the status quo is more difficult than the move to something new. In 2015 MarkLogic has made it easier than ever to adopt a new platform with native JavaScript/JSON support in version 8 and an overall enhanced developer experience. But many potential MarkLogic customers have a significant investment in the traditional SQL world. They are trying to decide if it is easier to stick with the increasingly difficult task of adding new data sources by extracting new data and transforming it into tables, updating data models and updating their data warehouses vs. trying something new like NoSQL.
Change is often scary and made when continuing with the status quo is more difficult than the move to something new. In 2015 MarkLogic has made it easier than ever to adopt a new platform with native JavaScript/JSON support in version 8 and an overall enhanced developer experience. But many potential MarkLogic customers have a significant investment in the traditional SQL world. They are trying to decide if it is easier to stick with the increasingly difficult task of adding new data sources by extracting new data and transforming it into tables, updating data models and updating their data warehouses vs. trying something new like NoSQL.
So let’s talk about the future of analytics and how MarkLogic can help. Analytics of the future will not be done in silos but across heterogeneous sets of data. Organizations are starting to merge tabular data with research reports, images, videos, blog posts (like this!), and Twitter feeds. There has never been more variety or volume to manage than now, and these new data sources are being brought in more frequently and quickly than ever.
More Meaning More Quickly
So, how can an Enterprise NoSQL database platform help analysts and data scientists? MarkLogic helps you quickly find what you need and helps you understand the value of your data within a larger context. Simply put, it can provide more meaning to your data more quickly. Let’s take a look at a real example using an application powered by MarkLogic built by our partner, Epinomy LLC. Epinomy, the app, was built for managing time series data. Time series data can be any data value that is measured over time, such as a patient’s lab results or economic indicators.
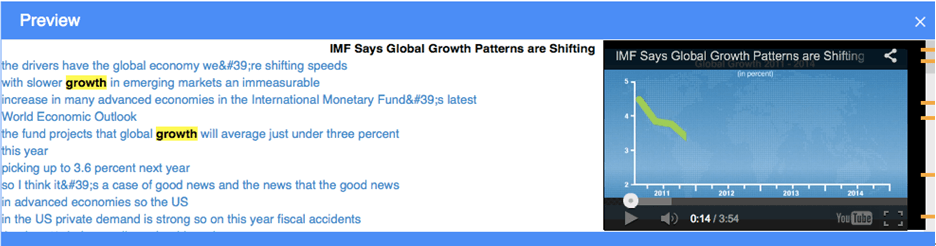
In this example, Epinomy was loaded with economic datasets, publications, and video from many external (i.e. World Bank, OECD, and IMF) and internal sources for an international non-profit banking and lending organization. Because MarkLogic is an application server that supports REST, some data came in via web services, and some batch imports were done using MLCP, MarkLogic’s content pump. Video was incorporated into the application using YouTube’s auto transcription service. Transcripts were easily loaded in and a YouTube widget was embedded directly within the application.
Here, a search for content takes users directly to the 10 second segment that is clicked on by the user:
Loading Data “As-Is”
One of the questions we hear the most from those switching from the SQL world to MarkLogic is related to our load “as-is” claim. How can MarkLogic load data “as-is”? MarkLogic does this through its Universal Index. Every word, phrase, work stem and token, value, and parent-child structure is indexed. Also part of the Universal Index includes security indexes, geospatial indexes, collections, and triple store indexes. You can load in any data, search and find it immediately in the next clock cycle with very little effort.
In the process of loading data in and converting it into the internal storage format (XML, JSON or triples) some insight into the data is gained right away. For example: <GDP>3.65</GDP> means that the value of GDP is 3.65 in XML notation. Some refer to XML as self-describing due to the meanings you can infer from element and attribute names. (However, we understand some people disagree with this assertion.) What people coming from the SQL world are really wondering is how can MarkLogic associate terms from different sources with different names together without needing to do ETL or up front data modeling? Loading as-is does not mean you don’t ignore a data model, rather you don’t need all the answers up front. In building Epinomy, the team took advantage of MarkLogic’s load as-is capability to quickly bring in the data from multiple sources and created a simple search application to gain a better understanding of the data.
Associating Similar Terms From Disparate Sources
Once we understood the data, we had ideas on how to present the data and how we’d want to model it going forward. In all honesty, we didn’t choose the best data model initially, and as new requirements were added, the data model had to change a few more times. Isn’t this really typical, though? How many projects have you worked on that didn’t have any change in requirements? MarkLogic provided us with the platform and flexibility to try different models out and “fail fast” instead of potentially spending months on modeling just to find out a year later we were wrong. (We ended up with a hybrid data model with some data stored in MarkLogic as triples and some stored as XML.)
But, getting back to associating terms with different names from different sources, how did we do this without ETL? Well, MarkLogic is perfect for this because it is a document-based NoSQL database which allows for flexibility in naming and associating terms. First, storing data in JSON or XML allows for a hierarchy so that you can have a parent with several child nodes. So, as you load data or modify data, you can just stick in another child name. I could have some economic term “GDP” with children “XZY_GDP” and “ABC_GDP.” I could then create my search application such that when a child name “ABC_GDP” is searched and found, all data from its parent GDP is returned. In essence, you can have multiple names for things really easily in a document database. Also, when using XML, we can take advantage of XML markup. So, we could also have associated names added as an attribute to the data. Since MarkLogic supports a thesaurus, Epinomy uses this capability to manage similar terms.
MarkLogic also natively handles triples. (A triple is just a fact, a subject-predicate-object statement such as “John LivesIn London” or “London IsIn UK”. Using semantics you can then infer “John lives in the UK” without having to explicitly have this fact anywhere in your database.) Epinomy makes use of MarkLogic’s triple store to associate unstructured data such as publications or video to the time series (economic indicators) data. Upon loading of a document, Epinomy checks its Taxonomy Manager to see what taxonomies have been loaded in. If there are term matches in the document to a loaded taxonomy, a triple is created that links the term to related economic indicators. Here’s a screenshot of the Concept Manager page:
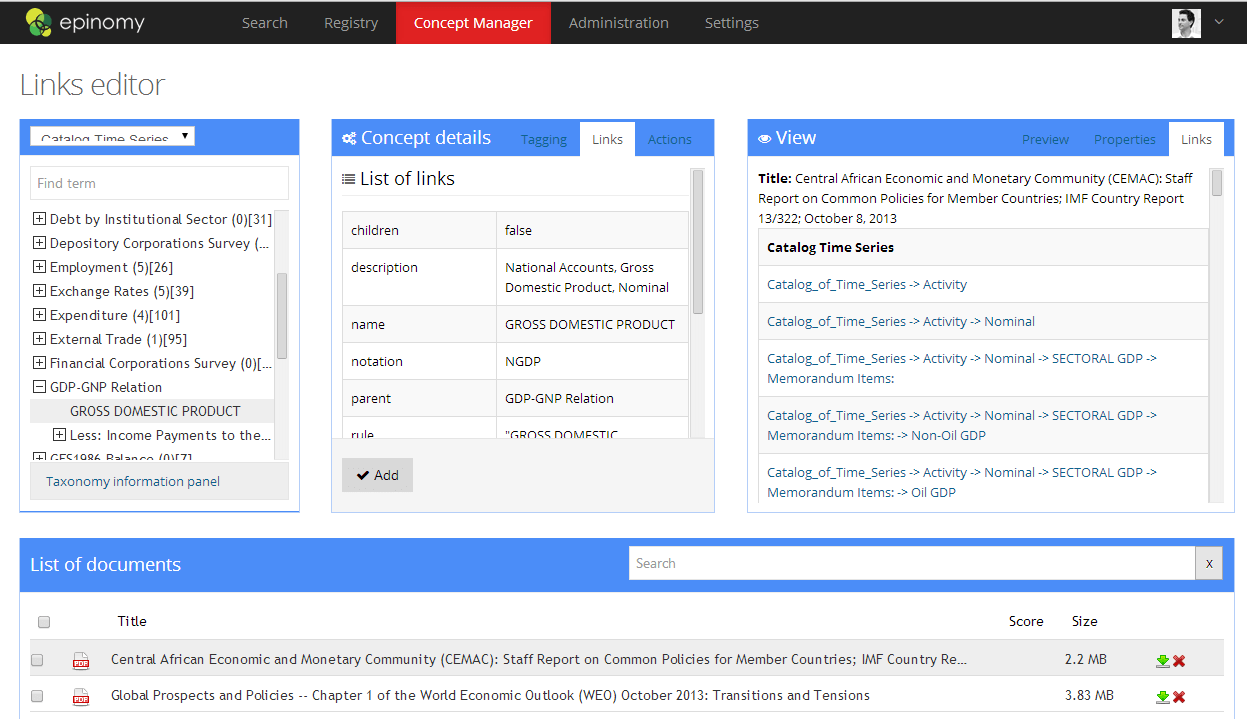
Users can select a taxonomy from a pulldown menu, navigate or search to find a term, then find associated thesaurus terms or triples in the Concept Details panel. Items can be dragged from the Taxonomy Manager (left panel) to the Concept Details (middle panel) to create either a new thesaurus entry or a new triple store entry. On the right hand side panel, a preview of links (triples) appears from the selected document. This whole page allows non-technical business analysts the ability to find or modify associations between terms saving valuable time for the IT organization.
In Part 2 we will dive a little deeper into the query expansion, talk about an idea for keeping your data up to date, and show examples of search facets for time series data. We’ll also talk about connecting this information to third party visualization tools such as Tableau. If you can’t wait, you can check out a video here.

