How to bulk insert JDBC batches into Microsoft SQL Server, Oracle, Sybase

Are you looking to improve performance of JDBC batch inserts into SQL Server, Oracle, and Sybase? If so, you are not alone based on the buzz surrounding codeless DataDirect Bulk Load in our Progress DataDirect JDBC drivers. The common requirement is to speed up inserts for large amounts of data from Java Application environments; and shops are pleasantly blown away at how easy it is to speed things up in a single step with no code changes required.
Before DataDirect Bulk Load, organizations were considering various approaches they considered less than desirable for their project. I've heard plans to redevelop the application to generate an intermediate CSV file and call external bulk load utilities after porting it from Linux to Windows. Another shop was even considering a Java to .NET layer to perform the insert.
How do you enable codeless DataDirect Bulk Load for your JDBC batch insert in a single step?
1. Add two options to your connection string:
;EnableBulkLoad=true;BulkLoadBatchSize=n (where n is an integer representing the JDBC batch size)
By the time you finish reading this sentence, you could have made the change yourself and be ready to start a batch to bulk insert! This is one of the most innovative features I've seen in a JDBC driver as it translates the batch inserts into the database's native bulk load protocol transparent to the application.
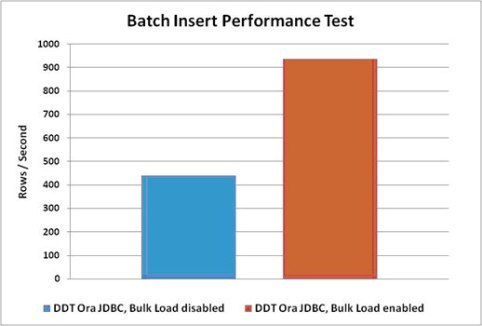
What about streaming result sets or consuming CSV files?
An additional feature of DataDirect Bulk Load is the DDBulkLoad extension. You can use it to bulk load or export CSV files to/from any DataDirect driver that supports DataDirect Bulk Load. Additionally, the drivers can be used to stream JDBC result sets from one data source to another.
Bulk Load from JDBC ResultSet rs:
DDBulkLoad bulkLoad = com.ddtek.jdbc.extensions.DDBulkLoadFactory.getInstance(Connection);
bulkLoad.setTableName("GBMAXTABLE");
bulkLoad.load(rs);
Bulk Load from CSV file:
DDBulkLoad bulkLoad = com.ddtek.jdbc.extensions.DDBulkLoadFactory.getInstance(Connection);
bulkLoad.setTableName("GBMAXTABLE");
bulkLoad.load("tmp.csv");
For complete details, please see the chapter on Using DataDirect Bulk Load in our User's guide.
Do you have any batch code samples for a POC to test performance between EnableBulkLoad=true|false?
Try the JDBC batch sample below to simulate batch to bulk insert performance and modify the column bindings for your table.
public void bulkInsertTest() {
int JDBC_BATCH_SIZE = 15000;
String dbConUrl = "jdbc:datadirect:sqlserver://nt64sl2003a.americas.progress.comsql2008;Port=1433; DatabaseName=test;User=test;Password=test;EnableBulkLoad=true;BulkLoadBatchSize=" +JDBC_BATCH_SIZE; String sourceTable = "mySource"; String destTable = "myDestination";
Connection insertConn = null;
Connection readConn = null;
ResultSet rs = null;
try {
insertConn = getConnection(dbConUrl); readConn = getConnection(dbConUrl);
insertConn.setAutoCommit(false);
String sql = "SELECT c1,c2,c3,c4,c5,c6,c7,c8,c9 FROM " + sourceTable;
Statement stmt = readConn.createStatement(); Statement insertstmt = insertConn.createStatement(); rs = stmt.executeQuery(sql);
insertstmt.execute("DELETE FROM " + destTable); String insertSql = "INSERT INTO " + destTable + " (c1,c2,c3,c4,c5,c6,c7,c8,c9) VALUES (?,?,?,?,?,?,?,?,?)";
System.out.println("Start: " + new Timestamp(System.currentTimeMillis()));
PreparedStatement psmt = insertConn.prepareStatement(insertSql); long counter = 0; long numRows = 0;
while (rs.next()) { counter++; numRows++;
int c1 = rs.getInt(1); Timestamp c2 = rs.getTimestamp(2); Timestamp c3 = rs.getTimestamp(3); String c4 = rs.getString(4); String c5 = rs.getString(5); Timestamp c6 = rs.getTimestamp(6); int c7 = rs.getInt(7); String c8 = rs.getString(8); String c9 = rs.getString(9);
psmt.setInt(1, c1); psmt.setTimestamp(2, c2); psmt.setTimestamp(3, c3); psmt.setString(4, c4); psmt.setString(5, c5); psmt.setTimestamp(6, c6); psmt.setInt(7, c7); psmt.setString(8, c8); psmt.setString(9, c9);
psmt.addBatch(); if (counter == JDBC_BATCH_SIZE) { // batch size psmt.executeBatch(); psmt.clearParameters(); psmt.clearBatch(); counter = 0; }
insertConn.commit(); } } catch (Throwable t) { t.printStackTrace(); } finally { try { readConn.close(); insertConn.close(); } catch (SQLException e) { e.printStackTrace(); } } }
How can the database be tuned to improve bulk load performance?
SQL Server 1. Verify the Database's recovery mode per msdn article on Considerations for Switching from the Full or Bulk-Logged Recovery Model. To verify the recovery mode, the database user can run the following query:
SELECT name, recovery_model_desc FROM sys.databases WHERE name = 'database_name' ;
Note the recovery_model_desc returned by this query (expect to return,'BULK_LOGGED').
2. Check the Prerequisites for Minimal Logging in Bulk Import.
Sybase For Sybase, some additional database configuration is required when the destination table for a bulk load operation does not have an index defined. If you are using a destination table that does not have an index defined, you can ask the database operator to execute the following commands: use master sp_dboption test, "select into/bulkcopy/pllsort", true
This option is required to perform operations that do not keep a complete record of the transaction in the log. For more information, refer to the Sybase documentation. Alternatively, you can define an index on the destination table. Failure to properly configure the database results in errors such as the following: "You cannot run the non-logged version of bulk copy in this database. Please check with the DBO."
Oracle DataDirect bulk load is supported on versions 9.0.1 and higher.
Who do these guys think they are?
You might be wondering, how does Progress DataDirect always seem to add ground breaking functionality to their JDBC drivers?
To get an idea, I googled the question and found that 3 of my DataDirect colleagues are JDBC Experts with offices down the hall from mine (Mark Biamonte, John Goodson, and Jesse Davis) working on the JDBC 4.1 specification. Therefore, you should expect innovation and superior data connectivity from DataDirect; and can get started today with a 15 day trial:
1 . Install Progress DataDirect Connect for JDBC using the instructions in the Progress DataDirect Connect for JDBC Installation Guide. You can download a free, 15-day trial of the Progress DataDirect SQL Server JDBC driver (including DB2, Oracle, Sybase, MySQL and Salesforce).
2. Or call 1-800-876-3101 to speak with a live Solutions Consultant to learn more about DataDirect JDBC bulk load.

