
This post is the second in a two-part series in which I address some of the common doubts people have about NoSQL. In the last post, I addressed the doubts that I often hear from people that who don’t think there are any problems with relational databases. In this post, I address the doubts about NoSQL.
So, if you’re reading this post, my guess is that we’ve made a slight crack in the relational armor, but haven’t yet made you a convert to NoSQL. You still have serious doubts about whether Enterprise NoSQL is what we say it is—that it really can get your projects done better, faster, and with less cost than relational.
Doubters: “NoSQL just delays having to deal with the details — you still need a schema.”
Our Answer: “NoSQL does address the details, it just does it with more agility.”
We say that with MarkLogic, you can load data as is. That is shocking to most people. It is also commonly misunderstood. Often what people hear is, “data never needs structure.” That, of course, isn’t true at all.
There are absolutely times when a schema is required to define the structure of the data. When you’re building a transactional app and you need to update a customer record, you need to have a common structure for the data. But you don’t always need a structure. What you need is the ability to define a schema when you need it. And, it may not be just one schema. You may need multiple schemas because you have multiple data sets that you ingested from multiple sources. MarkLogic is designed to handle multiple schemas. Relational databases are designed to handle one schema. That is at the crux of why the document model works so well.
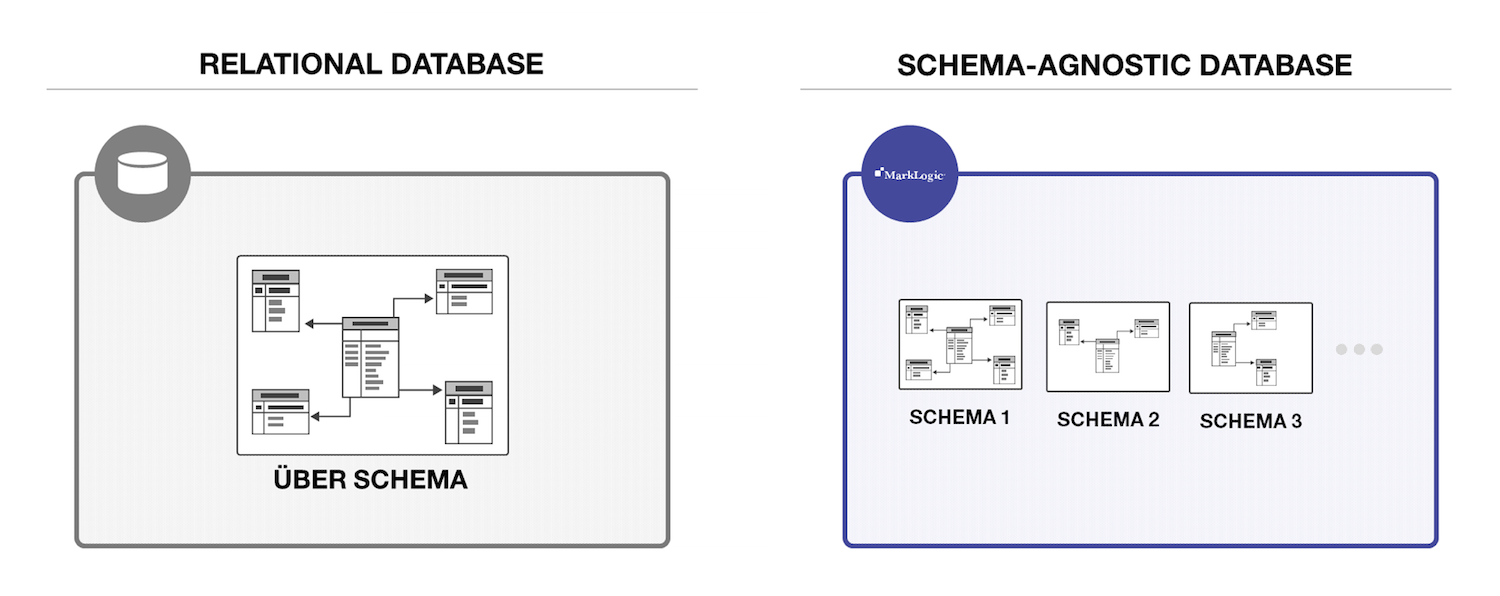
In my post, Get the ETL Out of Here, I provide more detail about how you can use MarkLogic’s ability to handle multiple schemas to your advantage when integrating data from silos.
In another post, Dan McCreary discusses <a href=”https://www.marklogic.com/blog/understanding-the-load-as-is-pattern/”MarkLogic’s load as is capability in significantly more detail. What you’ll find in both of those posts is that the process of data modeling and handling changes in MarkLogic is agile. And, similar to agile software development, you’re not putting off having to deal with the details, you’re just creating a system in which you can better handle the details at the right time.
At the beginning of a project, how would anyone ever be able to predict future new data sources? A new data source may arrive later that has a messy looking, very different schema from the data currently in your database. With a NoSQL database, you still have to do the work to harmonize that data together. But you can move faster with less risk because you don’t have to do all of the modeling in advance, re-write all of your ETL scripts, or decide what data to scrap as you transform your source data.
Doubters: “It’s only a matter of time before NoSQL gets slowed down by bureaucracy.”
Our Answer: “Actually, MarkLogic has to jump through the same hoops as any other database.”
This doubt usually follows the objection that relational databases are not in fact that hard to change. Once it becomes clear that they are indeed hard to change, this objection becomes a “people, process” problem, not a technology problem.
The reasoning goes that relational databases, having been around for 40 years, have more managerial overhead surrounding them. Executives have a better grip on them and tighter controls are put in place. If a new NoSQL database is claimed to have any improvement, it’s just because management hasn’t “caught on yet.” Eventually, it will be subject to the same controls and oversights—the same bureaucracy—as any other mission-critical technology. After that, it will take just as long to do anything with NoSQL as it does with relational.
True, there is more at play within large organizations than just the technology. People and process are also very important, but to say that bureaucracy hasn’t caught up with NoSQL isn’t true—at least not with MarkLogic.
In almost every case, MarkLogic has to go through the same reviews, testing, approvals, management and regulatory oversight as any other database. It may not be as true for some other open source databases being used for non-mission-critical use cases or prototype projects. For the more important use cases, however, it certainly is.
Examples of Where MarkLogic Is Used for Mission-Critical Operations
- KPMG KPMG built a MarkLogic-powered application to support client onboarding primarily for the purposes of compliance with regulation, tax, and reporting. The application uses intelligent automation of complex manual processes and maintains a fully traceable, auditable data workflow.
- Deutsche Bank MarkLogic replaced Oracle to be the global trade store for the bank’s operational trade data. The first production deployment that integrated over 30 trading systems launched in just six months—all while maintaining secure and consistent transactions.
- U.S. Combatant Command MarkLogic replaced Oracle to serve as the data layer for a command-wide knowledge- and information-sharing system for an increasingly diverse dataset that is consumed by a wide variety of programs and people in the US Department of Defense.
Projects go faster with MarkLogic not because of a lack of oversight and bureaucracy, but because MarkLogic enables organizations to be more agile than with relational. As I’ve already discussed, relational databases require a waterfall, big bang approach to data modeling decisions because they require all the data to be modeled up front.
With MarkLogic’s flexible data model, the processes can be more iterative and you don’t have to agree on a single schema up front.
Does the organization still have to understand and evaluate schema changes? Absolutely. Just because changes can be made more rapidly, doesn’t mean they are subject to a special approval process that’s unregulated and unsupervised.
Doubters: “NoSQL databases are only for simple applications, nothing more.”
Our Answer: “Maybe some NoSQL databases, yes. But not MarkLogic.”
In an interview with eWeek, Oracle’s EVP for Database Server Technologies, Andy Mendelshon, said, “The end of the story is pretty simple: NoSQL products are very good for very simple applications, where you’re pointing data back to the key, you’re getting a value back, and it can be a JSON document or whatever it is that people want. Relational SQL databases are really good when you’re trying to do more complex workloads, like getting a report back for your business and doing transaction processing.”
This is an extremely dismissive comment, but worth addressing because it’s partially true. In fact, there are many NoSQL databases that are meant for relatively simple use cases like managing session information for a web application or online gaming, or managing data feeds from social apps or IoT. Often, all you need is a simple key-value store. Or, you just need a simple document store that functions like a key-value store, which is what Mendelshon was specifically referring to. With some document databases, you just use the document ID as the key and the rest of the document is the value. You don’t need to index the whole document, you don’t need transactional consistency. You don’t need security. You just need something simple.
But not all document databases can be dismissed so casually, and certainly not MarkLogic. With regards to MarkLogic, Mendelshon’s comments are not true at all.
MarkLogic, is far more than a simple key value store and also has more capabilities than any of its document store competitors. This is primarily due to MarkLogic’s indexing and transactional capabilities, in addition to a host of other enterprise features.
With MarkLogic, the whole JSON or XML document gets indexed using a Universal Index, which allows you to search anything in the document and do very complex queries. If you have a customer record, you can search by its ID, but you can also search by the customer’s zip code, last name, or anything else.
MarkLogic also has ACID transactions and plenty of customers use it for very complex, high-performance transactions, including multi-document distributed transactions. MarkLogic has plenty of case studies in which the database handled many thousands of transactions per second for hundreds of thousands of users (see list of case studies above). Beyond that, MarkLogic also has enterprise-grade HA/DR and certified security.
Needless to say, MarkLogic can handle “more complex workloads, like getting a report back for your business and doing transaction processing.” MarkLogic is far more ready for mission-critical applications than other document databases. For example, we have one large banking customer that uses MarkLogic in addition to another open source document database. Out of the 200 reported downloads of that open source document database, 13 of which they have paid-for licenses, they have zero actual production applications using that document database.
In addition to being a document store designed for running enterprise applications, MarkLogic can also store RDF triples, a capability we refer to as semantics. This capability turns MarkLogic into a true multi-model database with these data models being integrated together in a single system, allowing you to query across all of your data with a single multi-model API.
With MarkLogic, you have the perfect system for storing all of your entities (as documents) and your relationships (as triples).
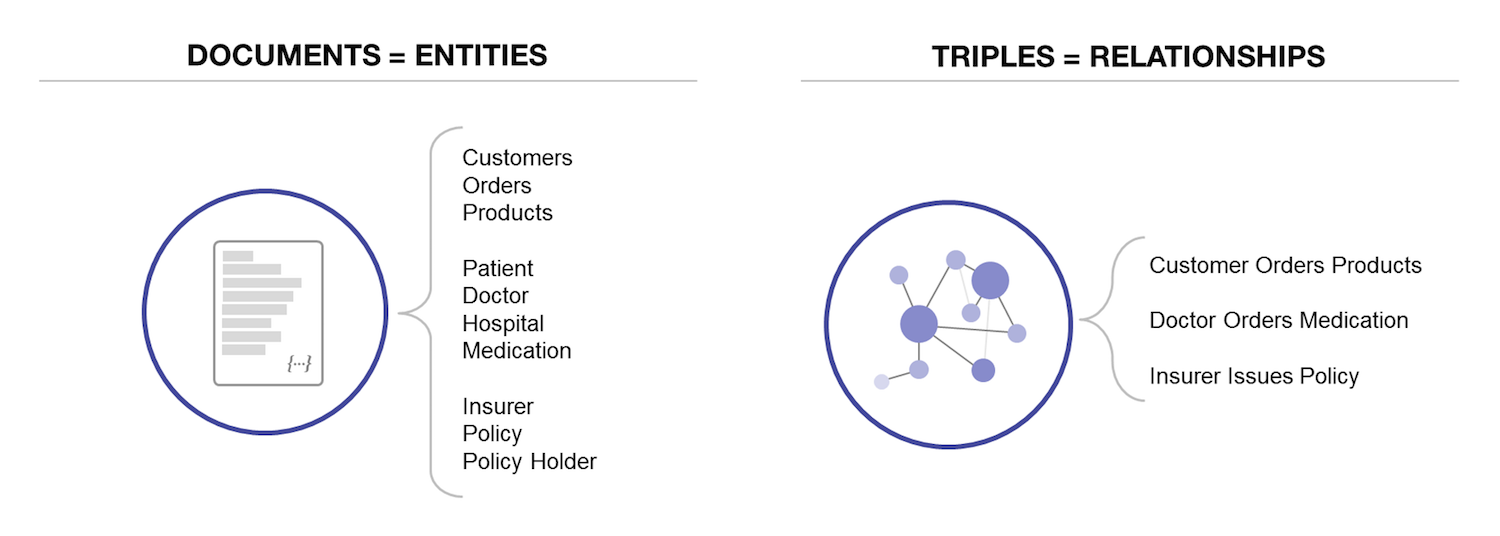
What is ironic is that with Oracle you would need a database, search engine, and triple store in order to replicate the capabilities you get with MarkLogic’s single unified system. With MarkLogic, you get a unified, multi-model database for modern, transactional, enterprise-grade applications.
For more information on this topic
Escape the Matrix, 45-min recorded video given by MarkLogic SVP of Engineering, David Gorbet. Great examples of disparate schema integration.
Aetna: Implementing an Enterprise Operational Data Hub, Mike Fillion, Director, Architecture Delivery, Aetna

