
In this post, I am going to explain how you can significantly reduce the cost and time associated with ETL, by introducing how MarkLogic approaches the process. With MarkLogic, the goal is not really to “get the ETL out of here” — the goal is to take a new, modern approach in which you load as is, search, harmonize, and enrich your data, which we call the “E-L-T approach” — Extract, Load, then Transform. Our customers regularly use this MarkLogic approach because it’s faster and more agile. Translated: You get to production in weeks or months rather than years.
But I am jumping ahead of myself. First let’s look at what has traditionally been required for data integration: Extract, Transform, Load.
- Extract – The process of getting data out of the source database(s). This step usually includes not only extracting the data but then validating that the extraction ran as expected.
- Transform – The process of changing the schema of the data to make it uniform with other data sources and matching the target schema before loading to the target database. This may include simple reformatting like updating a date format or choosing columns to ingest, but is often more involved, requiring pivoting, aggregating, disaggregation, translating, encoding, and more.
- Load – The process of loading or ingesting the data into the permanent, target database. This involves strategic decisions about the timing and frequency of loading data, and whether the data overwrites or expands on any existing data.
Although ETL may seem like a simple, 3-step process, it’s actually very expensive and time-consuming.
ETL Software Is Expensive
To make the process more manageable, a proliferation of tools have come onto the market. Examples of ETL software vendors include: Informatica (PowerCenter, PowerExchange, Data Services, and 15 other products), IBM (Suite of Infosphere products), SAP (Data Services, Process Orchestration, Hana Cloud Integration, etc.), Oracle (Data Integrator, GoldenGate, Data Service Integrator, etc.), SAS (Data Management, Federation Server, SAS/ACCESS, Data Loader for Hadoop, Event Stream Processing), and the open source Talend (Open Studio, Data Fabric, etc.). Needless to say, there are plenty of vendors looking to tap into the ETL market and it’s surprising to me just how many ETL tools a single vendor tries to convince organizations they need!).
In total, organizations spend $3.5 Billion on ETL software for data integration each year (Gartner. Forecast: Enterprise Software Markets, Worldwide, 2013-2020, 1Q16 Update. 17 March 2016). All of these tools are designed to prepare the data to be moved into an operational database or data warehouse. But, the ETL work takes up a disproportionate amount of project time and money. In fact, 60 to 80 percent of the total cost of a data warehouse project may be taken up by ETL software and processes (TDWI, Evaluating ETL and Data Integration Platforms).
ETL Requires Lots of Time and Manpower
If procuring the tools are expensive — that’s just the beginning. There is a lot of work to set up, use, and manage the ETL tools and database connections. Once the tool is set up, there’s even more work to gather the data sources together, do all the data modeling, and manage the changes that occur throughout the process. The facts show that a typical large-scale data integration project at a Fortune 500 organization takes anywhere from two to five years to complete; from the time the project kicks off to when an app is launched into production! Adding it all up, the total cost of ETL and associated data integration efforts are closer to $600 Billion a year (estimate according to MuleSoft). That estimate seems high to me, but either way, I think we can all agree that ETL is a really expensive problem.
Reduce the Cost and Time Spent on ETL
MarkLogic takes a different approach to solving the data integration problem. How is MarkLogic’s approach different?
First, MarkLogic can handle multiple schemas in the same database which means you can load your data as is rather than having to define and agree on a single “über schema” up front. This makes it possible to get going faster and eliminate a lot of painful rework that typically has to be done with a relational database when a change is required or new data source comes along.
Second, MarkLogic makes it possible to harmonize and enrich the data inside MarkLogic. In other words, you can do all of your transform work (the “T” in ETL) after loading the data right inside MarkLogic with the trust and reliability of a transactional database. And, you don’t have to buy and maintain a separate tool.
So, how much do you save in money and time?
A typical MarkLogic data integration project goes up to four times faster than the traditional approach to data integration with a relational database and ETL tools. Customers using MarkLogic have demonstrated this speed in multiple large projects across industries. And it’s not just about speed — the quality of the data that you get as a result is actually better as well. We’ll get into more of that later, but first, let’s get a better understanding of the traditional approach to data integration.
Challenges With Relational Databases and ETL
When integrating data from silos, most organizations are working with a number of relational databases and they are trying to efficiently move the data from all those relational databases to another.
The most common reasons for wanting to integrate data are:
- Launching a new app that requires legacy data
- Building a unified, 360-degree view of your data in an analytical data warehouse
- Building a new system for Master Data Management (MDM)
- Migrating data between operational systems for internal or inter-enterprise purposes
- Support for governance, audits, or other monitoring
- Merger & Acquisition
- Or, you just don’t want to get rid of your data and you need a permanent home for it
In each scenario, the process of integrating data may look a little bit different depending on the scope of the project, type of data sources, and which tools are being used. The general process, regardless of use case of pattern, always involves lots of ETL in order to make heterogeneous data homogenous so that it conforms to a single schema. If you engage in this process, it usually looks something like this:
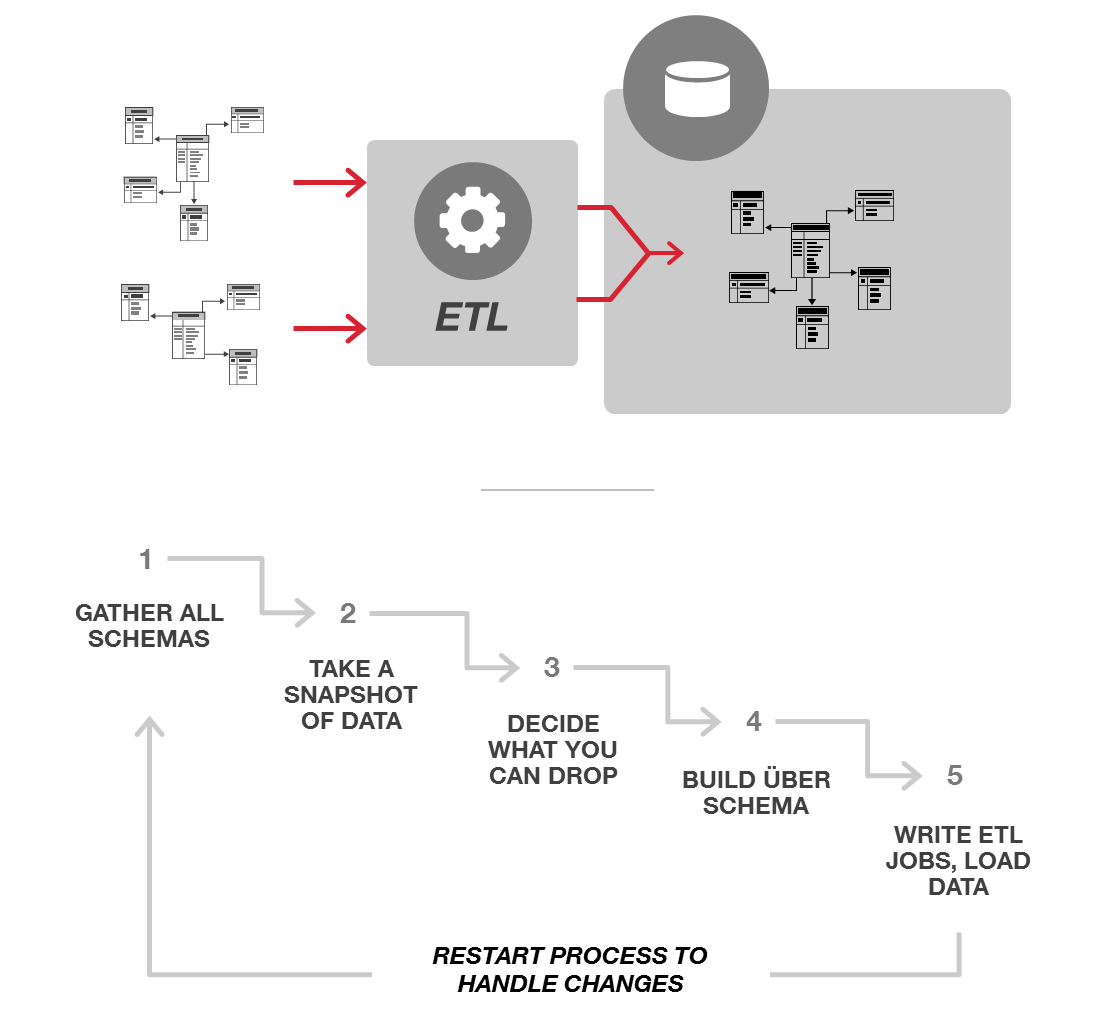
1. Gather All Schemas Together
You first need to know what data you have and how it is organized. This requires gathering all of the schemas that describe how your data is stored into a superset. Typically, this information is not in the database. Schemas are usually depicted in Entity-Relationship Diagrams (ERDs) that are often printed out and hanging on a wall or are saved somewhere in a folder. In consulting for other organizations, I’ve found that the DBA who’s been there the longest usually has the file.
2. Analyze the Schemas
Once you have all the schemas, you need to squint at them and figure out what they mean, how they work, and what they have in common. You may need to look at your data (and in some cases your code) to really make sense of them. For example, if you have an entity such as a customer, you may need to look at a bunch of different rows in different tables to get a complete picture of what a “customer” is in the database and how it relates to the business.
3. Decide What to Drop
If you try to integrate all of your schemas AND keep all of your data, you’ll never get it done. So, you typically decide what data isn’t that important, and only take the data you really need to have for the project you’re currently working on. Just consider if you had a data integration problem that involved 30 schemas—you’d definitely start to think about dropping some “low priority” data so that you don’t have to model it 30 times. So, maybe the application you’re building on the combined data doesn’t actually need the transaction status from the first model, and maybe you can get away with not having the shipping address, and maybe you could really simplify the model if you went with just the one phone number per customer … you get the idea.
4. Build an Über Schema
Now, you need to build “one schema to rule them all” — a schema that can accommodate all the data you decided to keep from all the different source systems. In addition to mapping out the new schema, you also have to decide how to handle all the exceptions like garbage data in a typed field, how to retain metadata about the source of each data element, and what transformations were made to get it to fit the new schema. And, if you want to capture changes to your data or to your schema over time, you have to figure out how to version it all.
5. Write ETL Jobs and Load Data
Assuming you made it to this stage, you finally get to start moving the data. This involves making sure any necessary transformations are done and then bulk loading all the transformed data into your new database.
6. Restart Process to Handle Changes
If a new data source comes along or another change is made during the process that impacts the schema, you have to go back and restart at Step 1 unless you get lucky and can fit your new data source into the existing über schema. But, typically, the new data source introduces a new many-to-many relationship or a different concept of the data that requires a change (which also has downstream impacts on existing applications). You’ve never come across any examples in which suddenly a person can have many addresses when you were expecting just one, or there are a bunch of VARCHARs in a table, right?
The MarkLogic Approach to “ETL”
With MarkLogic, the data integration process is much simpler and faster:
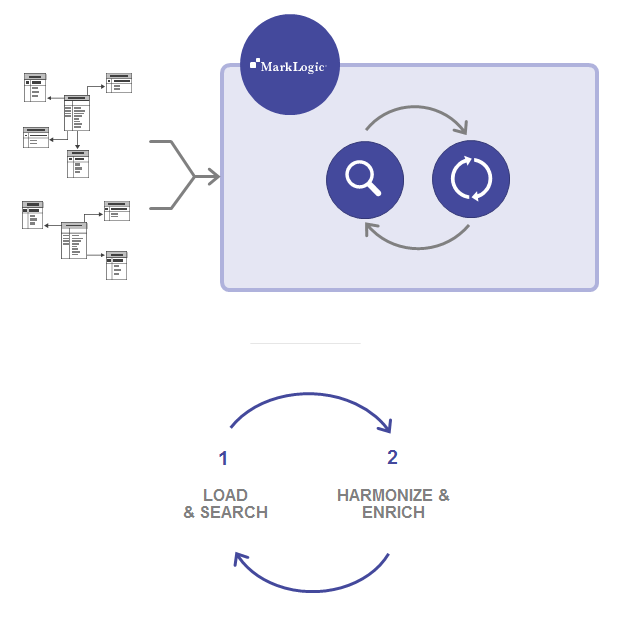
1. Load Data As Is
Load some initial data sources into MarkLogic as is and use MarkLogic’s powerful built-in search capability (the “Ask Anything” Universal Index) to help you understand the data from day 1. There’s no need to create one schema to rule them all. You can continue to load more data at any time, even if the schema is different. MarkLogic can easily handle multiple schemas in the same database and all the data is immediately searchable.
2. Harmonize the Data
This is akin to the “T” in ETL, but it’s different from traditional ETL in two key ways. First, you don’t have to throw away any data. Second, you don’t have to transform ALL of the data. For example, if one schema says “Postal Code” and another says “Zip”, you can transform just those elements in the data so you can query consistently by “Zip.” But, you harmonize in a way that you don’t have to throw away the original data that said “Postal Code.” We’ll get into more detail on how MarkLogic does that below.
3. Enrich the Data
In addition to harmonizing the data, you can enrich it to provide additional context and meaning for your business. You extend the raw data taken from your silos with new or extended data to enable new applications, features, or analytics. For example, imagine you have a record with a street address—you can enrich the data by simply adding GPS coordinates (which is a schema change that is no problem with MarkLogic’s document model).
4. Load More Data
Because data integration with MarkLogic is iterative and not a “big-bang,” all-at-once approach, you can just keeping loading data and continue to evolve your data model as necessary.
By using this process, customers are typically delighted to hear that they don’t even need to use an ETL tool for data integration because they can do everything they need inside MarkLogic. This helps simplify the process and saves a lot of money.
And the process goes much faster—about 4 times faster. Based on direct comparisons of MarkLogic to the traditional relational database + ETL approach at a number of Fortune 500 organizations, large scale MarkLogic projects were typically launched in 6 months rather than 2 years. The graphic below shows where you will typically find the time savings:
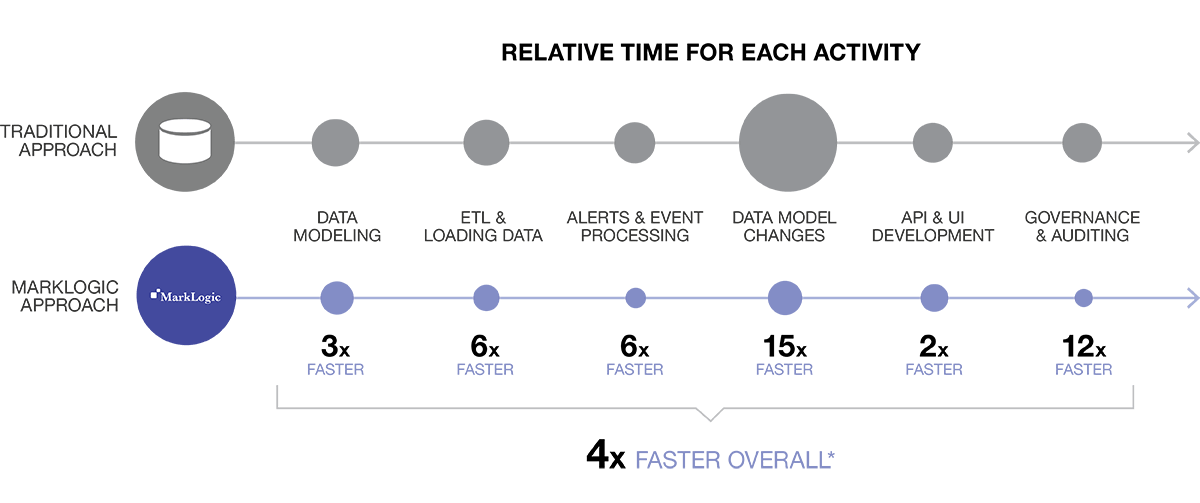
*Based on actual comparison data at a Fortune 500 company, and average project speeds with other customers across industries.
In addition to faster project timelines, the quality of the end result is much better. Rather than creating yet another silo, you now have a place to manage all your data in a schema-agnostic manner, relate all the data to each other via meaningful business concepts, and store it in a reliable and transactional manner (and, unlike other NoSQL database, MarkLogic can do multi-document transactions that are 100% ACID compliant).
You can use MarkLogic to both “run the business” and “observe the business” without resorting to endless cycles of ETL. Your data can continue to grow and grow, and you can stop spending time and energy moving it around between silos. Moving data between silos has no real inherent value in and of itself, so the less of that the better.
Deeper Dive
Now, let’s jump into a bit more detail about each step in the process to better understand how MarkLogic achieves these results when integrating data from silos.
Step 1 – Load Data As Is
MarkLogic is schema-agnostic, using a flexible data model that stores data as JSON and XML documents (and RDF triples, but let’s just focus on documents for now). Documents are flexible, hierarchical data structures as opposed to the strict rows and columns, and MarkLogic can manage documents that come in different shapes. In other words, MarkLogic can handle multiple schemas in the same database and you can just load your data as is. This means that:
- You don’t have to create an über schema and transform all of your data to that schema prior to loading it into the database
- You can load some of your data now, and some later—you don’t have to boil the ocean
- You don’t need an ETL tool to do all the prep work and transformation work before loading the data
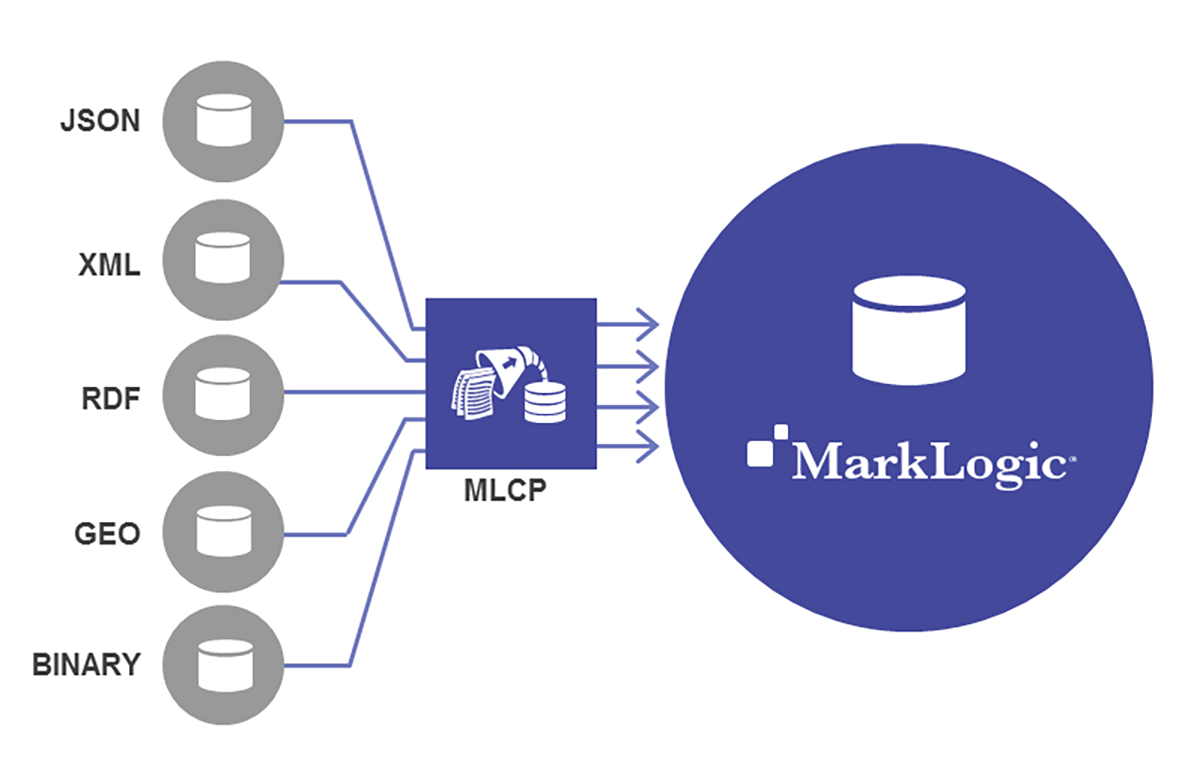
To load data, customers typically use a tool called MarkLogic Content Pump, or MLCP, to bulk load data. MLCP is an efficient, powerful tool, and you can even use it to do drive transformation on ingest if you want to, though you can also wait to transform that data to harmonize it once it’s inside MarkLogic (if you’re interested, watch a quick on-demand tutorial video from MarkLogic University). If you don’t want to use MLCP, you can also load data using other methods such as the REST API, Java Client API, Node.js Client API, or native Java / .NET connectors.
Once the data is loaded, you can search it because it is immediately indexed with MarkLogic “Ask Anything” Universal Index. It’s like Google search in the database—you can search by a keyword and see what documents have that keyword.
The built-in search capability is critically important for data integration. Going back to the example mentioned earlier, imagine that you’ve loaded documents about customer records and they have information about Zip codes. But some records may list a “Zip Code” and others may list a “Postal Code.” With MarkLogic, you could search for “94111” and find all the records that have that zip code. In a relational data integration project, you would have had to harmonize all of the records before loading them. It was either that, or not bring the zip code along with the rest of the data. In fact, you would have spent a lot of time harmonizing all of the attributes for all of the entities across all of the source schemas, whether you needed to query them or not. It was that or leave them behind.
If you’re interested in a deeper dive into the load as is phase, you can read this blog post, What Load As Is Really Means.”
Step 2 – Harmonize Your Data
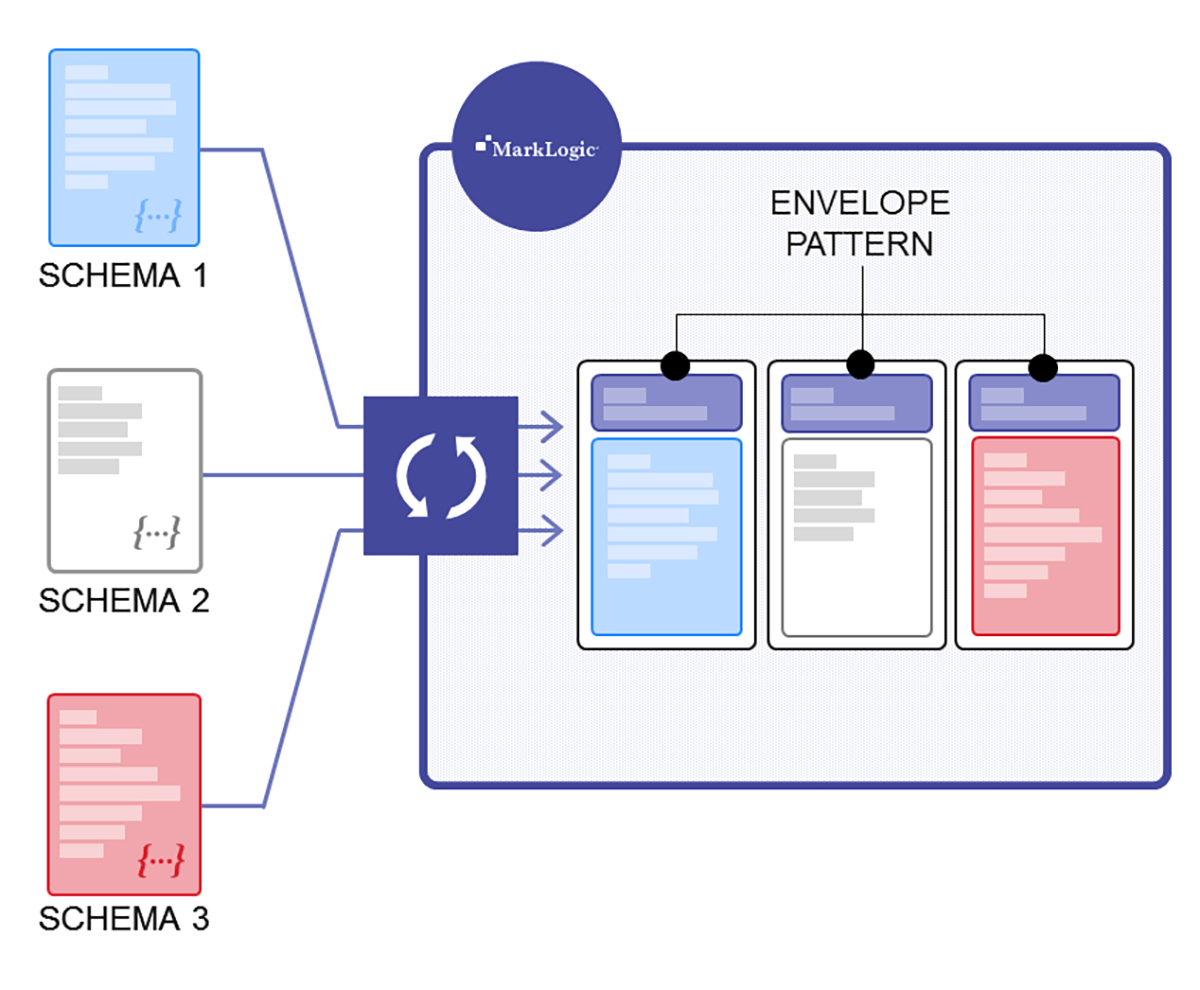
After you’ve loaded data and examined what you have, the next question is: Which parts of your data do you really need to harmonize in order to query consistently? You want to take your idiomatic (i.e., native, raw) representations of data in–no matter how quirky–and provide clean canonical representations out.
Zip code may be an important thing to harmonize because you’ll need it in your application. But maybe some records list each person’s favorite football team—you can leave that alone. You can still query about football teams because of MarkLogic’s indexing, but it may not be important to query for it consistently across all data sources.
Once you’ve decided what you want to start harmonizing, you can start employing the envelope pattern in order to build an evolving canonical model (i.e., a simple design pattern for maintaining agreed-upon data definitions). The envelope pattern is a best practice data integration pattern in MarkLogic that involves creating an envelope that contains only the canonical elements you want to query across consistently. So if you think you need Zip, then you can put that element into the envelope. If later on you also want to add “City,” “State,” “Favorite NFL Team,” or anything else, it’s easy.
Here is an example of the envelope pattern, where the original source data was added to a new root with the property “source” in each JSON document:
// Document 1:
{ "envelope" : { "Zip" : [ 94111 ] } ,
"source" : { "ID" : 1001 ,
"Fname" : "Paul" ,
"Lname" : "Jackson" ,
"Phone" : "415-555-1212 | 415-555-1234" ,
"SSN" : "123-45-6789" ,
"Addr" : "123 Avenue Road" ,
"City" : "San Francisco" ,
"State" : "CA" ,
"Zip" : 94111 }
}
// Document 2:
{ "envelope" : { "Zip" : [ 94111 , 94070 ] } ,
"source" : { "Customer_ID" : 2001 ,
"Given_Name" : "Karen" ,
"Family_Name" : "Bender" ,
"Shipping_Address" : {
"Street" : "324 Some Road" ,
"City" : "San Francisco" ,
"State" : "CA" ,
"Postal" : "94111" ,
"Country" : "USA" } ,
"Billing_Address" : {
"Street" : "847 Another Ave" ,
"City" : "San Carlos" ,
"State" : "CA" ,
"Postal" : "94070" ,
"Country" : "USA" } ,
"Phone" : [
{ "Type" : "Home" , "Number" : "415-555-6789" } ,
{ "Type" : "Mobile" , "Number" : "415-555-6789" } ] }
}
For this example, it may be important to harmonize by “Zip” because you’re building an application that shows how many customers you have in each geography and what they bought, and that lets you drill down further into product categories, types, and full text product descriptions. Your geographies are defined by zip codes, so you’ll need to query consistently by “Zip.”
It’s actually quite straightforward to add the envelope in MarkLogic. For the purposes of showing how straightforward it is, this is an update query you would run to add the envelope as a JSON property:
declareUpdate (); //get all documents from the “transform” collection
var docs = fn.collection(“transform”);
for (var doc of docs) {
var transformed = {}; //add a property as an empty object to add further data the original document
transformed.envelope = {}; //save the original document in a new property called “source”
transformed.source = doc;
xdmp.nodeReplace(doc, transformed);
}
By using the envelope pattern, you’re building your canonical data model in an agile way, from the ground up. Your model can meet the combined requirements of all the applications and services that use this data, but each application only needs to understand the parts of the model it uses. And, because there is a consistent canonical form in each record, it’s easy for anyone to use the data coming out of MarkLogic without having to understand the source schemas from the upstream systems.
Step 3 – Enrich Your Data
So, what if you don’t just want to transform your data and harmonize it, but you also want to add something to make it more valuable? That’s where data enrichment comes in. Although optional, this step is extremely useful and keeps important information tied directly to the data it pertains to rather than being non-existent or difficult to find, which is usually what happens in other databases.
In the example below, “metadata” is added to the document that includes information about the source of the data, the date it was ingested, and the lineage of the data.
{ "metadata" : {
"Source" : "Finance" ,
"Date" : "2016-04-17" ,
"Lineage" : "v01 transform" } ,
"canonical" : { "Zip" : [ 94111 ] } ,
"source" : { "ID" : 1001 ,
"Fname" : "Paul" ,
"Lname" : "Jackson" ,
"Phone" : "415-555-1212 | 415-555-1234" ,
"SSN" : "123-45-6789" ,
"Addr" : "123 Avenue Road" ,
"City" : "San Francisco" ,
"State" : "CA" ,
"Zip" : 94111 }
}
You may also want to add important such as geospatial coordinates for example. This sort of schema change is really difficult with relational databases, but incredibly easy with the document model:
{ "metadata" : {
"Source" : "Finance" ,
"Date" : "2016-04-17" ,
"Lineage" : "v01 transform"
"location" : "37.52 -122.25", } ,
"canonical" : { "Zip" : [ 94111 ] } ,
"source" : { "ID" : 1001 ,
"Fname" : "Paul" ,
"Lname" : "Jackson" ,
"Phone" : "415-555-1212 | 415-555-1234" ,
"SSN" : "123-45-6789" ,
"Addr" : "123 Avenue Road" ,
"City" : "San Francisco" ,
"State" : "CA" ,
"Zip" : 94111 }
}
Another Optional Step – Add Semantics
Above, I outlined how to take advantage of MarkLogic’s document model, but that’s only part of the story. Beyond the simple transformations above, there are many more things you can do by taking advantage of MarkLogic’s multi-model capabilities when you add semantic triples. For example, you can add triples metadata to create relationships between documents that makes it easy to handle joins and query across the many relationships in your data. For example, perhaps Customer 1001 placed Order 8001 and order 8001 contains Product 7001. With triples, the database can infer that Customer 1001 ordered product 7001. These are three simple facts that describe meaningful relationships and are naturally modeled as triples. And, because data and queries are composable in MarkLogic, you can write queries across both documents and triples together. This is a unique feature that other enterprise databases don’t have.
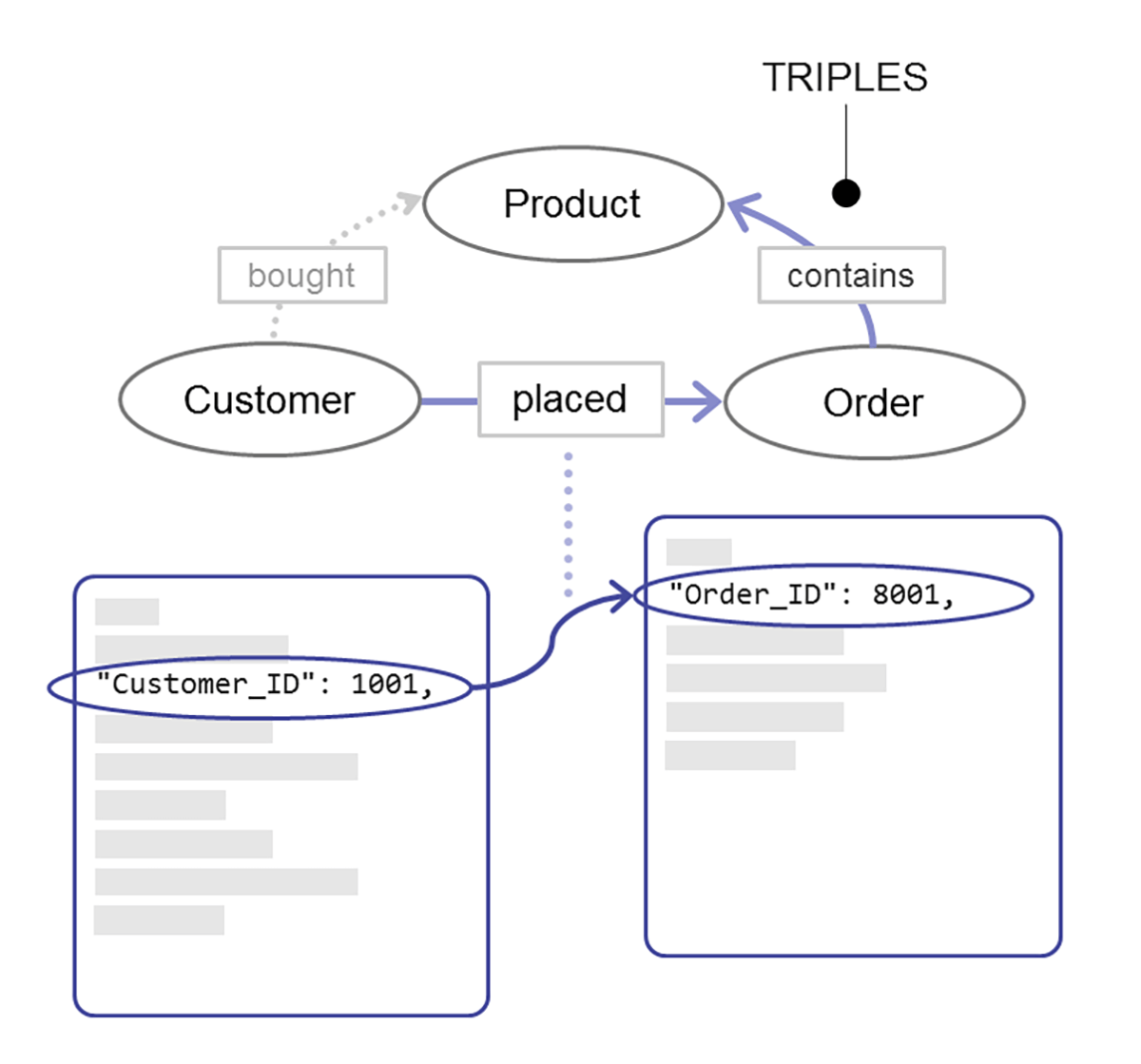
In a relational database, relationships are actually quite weak, but with semantics, you have a meaningful graph that you can use to your advantage. There is much more to add about using semantics for data integration, but I’ll stop there as that is a topic for another post.
If you’re interested in learning more about how to do harmonization, including the use of semantics, I would encourage you to check out our new on-demand training course provided by MarkLogic University, Progressive Transformation Using Semantics.
Step 4 – Load More Data
Rather than having to define your schema up front and load all data according to that one schema, MarkLogic makes it possible to continue loading new data sources—regardless of whether they match the canonical schema that you’ve started using.
So, for each new data source, you just continue loading as is. Then you figure out what you want to promote from that new data into the evolving envelope. If your source schema doesn’t have something that maps to your canonical schema (for example, it doesn’t have a zip code), then just don’t put anything there. If it contains something new that you now want in your canonical model, just add it. You don’t need to rebuild your whole database, because a change to the canonical model from integrating a new schema doesn’t impact any of your existing data or any of the applications or services consuming your data.
The End Result With MarkLogic
One of the big advantages of MarkLogic is that you can speed up the process of data integration by up to four times. Completing a project in 6 months rather than 2 years is hugely significant—just imagine what your team could do in that time. With MarkLogic, it’s easier to get data in from silos and do the transformation work inside MarkLogic in order to build your operational data hub using an agile process that is better and faster than with relational databases and traditional ETL. To recap, here is a summary of why MarkLogic’s “ELT”—load as is and harmonize—approach is better and easier than traditional ETL:
- Load and search source data as is
- Preserve lineage, provenance, other metadata
- Harmonize only what you need
- Update the model later without re-ingesting
- New schemas don’t impact existing data/apps
Another key advantage of MarkLogic’s approach is that it is much better for data governance. This is important because in most cases it’s not just one app that’s driving the need to integrate data. There may be one specific use case you’re starting out with, but the larger goal is to permanently disrupt the cycle of creating silos so that your data can be centralized, unified, and designed to answer the call of many different use cases. What you don’t want to do is create a new silo that works only for one use case.
To break the cycle of silos, you have to think about the data governance aspects of your new data hub, including security, privacy, lifecycle, retention, compliance, and other data-based policy rules that must exist independent of the applications using the data.
Let’s consider how lineage and provenance play roles in data governance. With MarkLogic, you can know where each attribute came from, when it was extracted, what transform was run on it, and what it looked like before. Nothing is lost in the ETL process. MarkLogic’s schema-agnostic design accommodates your source data, canonicalized (transformed) data, and metadata all in the same record, and all of it is queryable together. With this approach, you get to spend less time moving data around your enterprise and fixing bugs in transform code, and more time building applications and getting real value from your data. There are similar benefits for security, privacy, and compliance that you get from having all of your data together and tracked in a unified, centralized hub.
Next Steps
There’s a lot to learn about this topic, and this post is intended to show a little bit more detail about why MarkLogic is so great for data integration. If you’re interested in learning more, I encourage you to check out the following resources:
- Escape the Matrix – Engaging keynote by SVP of Engineering, David Gorbet, goes into more depth about how MarkLogic’s approach differs from traditional ETL. He includes specific modeling examples, and covers semantics
- Progressive Transformation On-Demand Tutorial – MarkLogic University provides this 16-minute overview of how to do progressive transformation. You’ll get a deeper dive, including a look at the queries to run
- Decimating Data Silos With Multi-Model Databases – Learn more about the multi-model approach and different pros and cons for various approaches in MarkLogic when building an Operational Data Hub

