Semantic RAG Series Part 1: Enhancing GenAI with Multi-Model Data and Knowledge Graphs

In this five-part series, we show you how to design a robust Retrieval Augmented Generation (RAG) workflow with the Progress Data Platform, enhance LLM response accuracy and develop AI-enhanced applications to empower your organization with the right information.
Part 2: The Knowledge Graph
Part 3: Content Preparation
Part 4: Content Discovery
Part 5: Chat Integration
Businesses are integrating Generative AI (GenAI) in everyday workflows and product offerings to elevate user experiences and productivity, including AI agents, chatbots, content summarization, content generation tools and more.
While this innovation brings new competitive opportunities, organizations need to take the direct output of the GenAI with caution to preserve accuracy, authenticity and brand safety.
About GenAI and LLMs
Large Language Models (LLMs) are pre-trained models that enable GenAI. These models contain information from the public domain and use a statistical approach to answer questions. While GenAI and LLMs seem to have an answer for every question, they have some major limitations.
Risks of LLMs include:
- Hallucinations - Products of an LLM generating an answer that is false or inaccurate
- Data cutoffs - Limitations in the data based on the time windows for the model training
- Data bias - Results when the content used to train the model is incomplete or contains inherently biased representations
As foundational models become more sophisticated, they will be capable of drawing more accurate conclusions. The reality today, however, is that most LLMs still fabricate information and will give you wrong answers. If you see GenAI as a priority enabler of your business’s competitive strategy, you need to be aware that misguided answers carry a cost and can be detrimental to your reputation. One risk mitigation tactic is to augment your interaction with the LLM to share enterprise information. Allowing a foundational model to tap into deep, domain-specific knowledge can significantly increase response accuracy.
Enterprises have a treasure trove of valuable data, such as research, intellectual property and content at varying security levels that should not be publicly available. This means organizations need to be extra cautious about how this information is passed to LLMs.
One way to prevent the LLM from retaining information is to provide the data in the prompt context window. RAG is the process of providing additional information as context for the LLM. It has matured into a well-established pattern implemented by many information management products.
The Progress MarkLogic and Progress Semaphore teams introduce a unique approach to RAG—semantic RAG. It combines knowledge graphs and multi-model content with semantic tagging and a comprehensive hybrid search in a robust flow. This approach allows you to mix data models, such as semantic concepts, documents and vectors, split them into consumable chunks and retrieve them via a single-query API. This has proven to increase the accuracy of LLM responses significantly.
Why Knowledge Graphs and Multi-Model Data?
Most of the information produced by the enterprise is unstructured. The IDC, a global market intelligence firm, states that 80% of all information generated is unstructured. Unsurprisingly, Forrester says 80% of new data pipelines are built for ingesting, processing and storing unstructured data. Traditional systems struggle with unstructured and multi-model content. The ability to load data as is and handle data in varying formats, schemas and sizes is key.
Multi-model data represents items that don’t traditionally fit into rows and columns. Records such as XML, JSON, PDFs and Office documents are just a few formats the MarkLogic platform can manage.
Knowledge graphs are comprised of interconnected objects and facts. For example, the statement High-Fructose Corn Syrup is a Sweetening Agent expresses the relationship between a subject and an object. A knowledge graph also reflects the world around you. It can mimic business processes, real-life physical objects or even domains of study.
In the context of GenAI and RAG systems, knowledge graphs ground LLMs in facts and provide the semantic context for them to correctly interpret user intent and find the information most relevant to answer a user’s query. Because knowledge graphs are maps of your enterprise’s knowledge, they act as a consistent long-term memory for LLMs that can be easily and frequently updated with fresh facts. This provides a computationally efficient way for an LLM to access and surface insights with repeatable confidence and validate prompts for AI systems.
Additionally, adding a semantic layer on top of your system aids in information classification, organization and discovery. The ability for systems to understand your business' concepts and terminology is powerful. For example, the R&D organization may call a product by its code name while the marketing department refers to it by its commercial name. Building a knowledge graph of interconnected facts and harmonized terms allows you to operate on even ground.
The MarkLogic platform has the unique ability to handle multi-model content and knowledge graphs in the same database. Content can be structured, semi-structured and unstructured, while objects in the knowledge graph can be documents, business entities or parts of a record. With this fully transactional system you can maintain representations of information in documents, graphs and search indexes. We will discuss how it is possible to manage these different shapes and cross-query them with great efficiency and flexibility.
Constructing the RAG Workflow
The RAG workflow has two major components: Content preparation and content discovery.
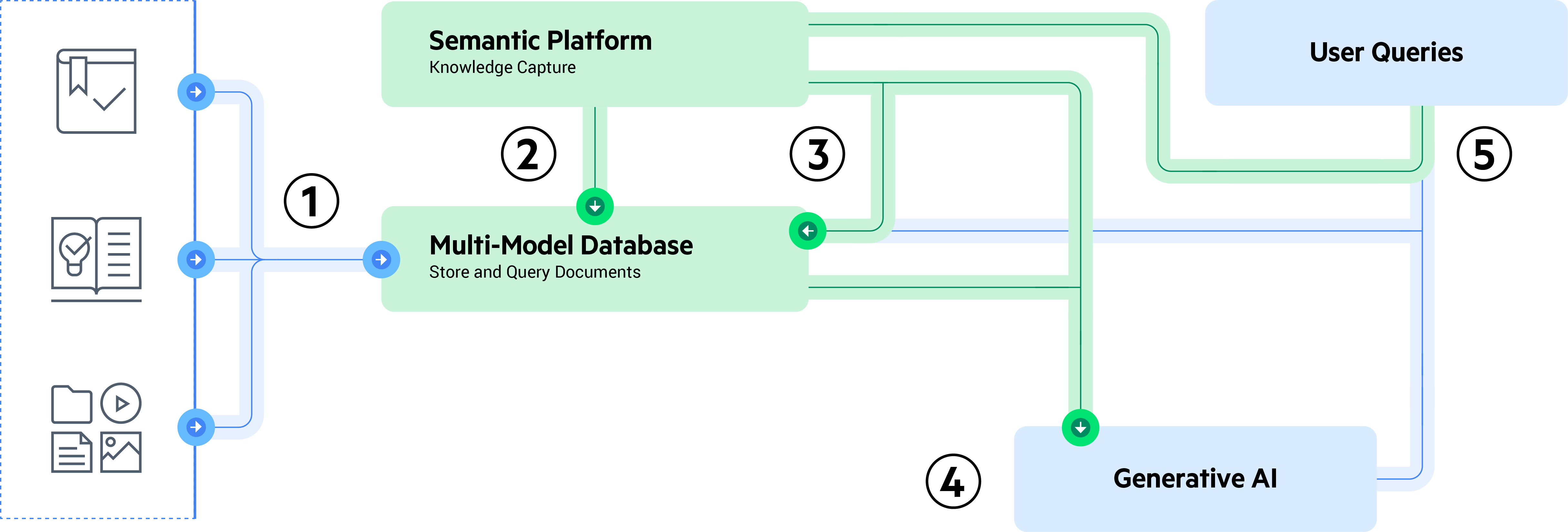
Content Preparation
Content preparation is the process of ingesting, chunking, vectorizing and classifying information to be used as part of the RAG context. Here are the steps we’re going to cover in this series:
- Ingest the as-is content into the MarkLogic Server. This can contain documents (Raw Text, XML, PDFs, Office documents, etc.). It is important to store the original for lineage and content references for user validation.
- Break each of the records into smaller components called chunks. This will allow you to provide more targeted content to the LLM and stay within the maximum number of tokens available for a context window.
- Classify the chunks. Classification is the process of semantically tagging content using a knowledge graph. This adds information into the records, such as citational metadata and aboutness tags.
- Add vector embeddings to the chunks. Vectors encode the meaning of content in a numerical representation. The vectors can be leveraged to re-rank your results based on the similarity to the question being asked. This will provide better context for the LLM.
Content Discovery
Content discovery is the process of finding relevant information in a large corpus of data. Part of the content discovery process is determining the key concepts within a user’s question, discovering relevant chunks and preparing a prompt.
- By intercepting the user’s question, you can determine the key concepts within it using the power of knowledge graphs. This is done in a similar fashion to the content preparation workflow.
- Relevance-based search can be used to search for these key concepts across the text body.
- Vector capabilities can be leveraged for re-ranking and semantic similarity.
- Prompt preparation involves adding the chunks to the context of the LLM so this proprietary knowledge can be used to answer the question.
Our flow must be built in a way that allows for corrections, so automation does not exacerbate inherent LLM malfunctions or inaccuracies. That means our starting point has to be small enough so subject matter experts (SMEs) can control and validate the output and help the model “learn.” This leads to more reliable technology.
Foundational models are already trained on all the data they can access on the internet, but they still lack the “tacit,” or social knowledge gained only through experience to make justified judgments. The key here is to not go the general-purpose way and instead deploy AI systems in small settings, on specific domains and progressively incorporate feedback from experts and interactions with users. That’s where knowledge graphs can help facilitate the model-expert learning experience.
Before we start preparing information for the LLM, let’s look under the hood of knowledge graphs and how to design and build one in our next article.
Download the Full Semantic RAG Whitepaper

