New Tableau to MongoDB ODBC connection that respects NoSQL data

Tableau analysts may or may not know about the challenges in exposing NoSQL data sources, such as MongoDB, to data visualization tools like Tableau, Qlikview, Spotfire, Microstrategy, SAP Lumira, SAS, Birst, etc. Progress DataDirect loves a good challenge and engineered the first reliable SQL connector to MongoDB using ODBC or JDBC without following the widely unpopular flattened schema approach.
Getting Started on reliable Tableau connectivity to MongoDB:
1- Download and install the DataDirect MongoDB ODBC driver (32-bit or 64-bit depending on version of Tableau). Tutorial shows Tableau 8.2 working with the 64-bit MongoDB ODBC driver.
2- Create an ODBC Data Source to connect to MongoDB (see end of tutorial for sample data with arrays of embedded documents)
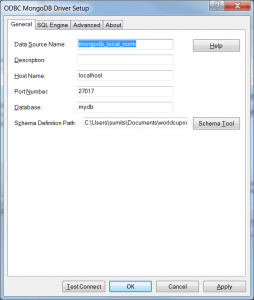
3- Launch Schema Tool and select "Normalized View" to create an intelligent virtual schema with a single click of the OK button
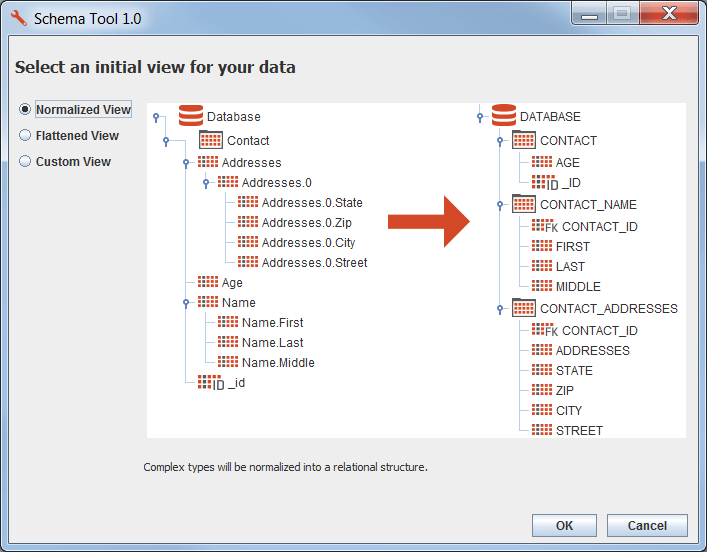
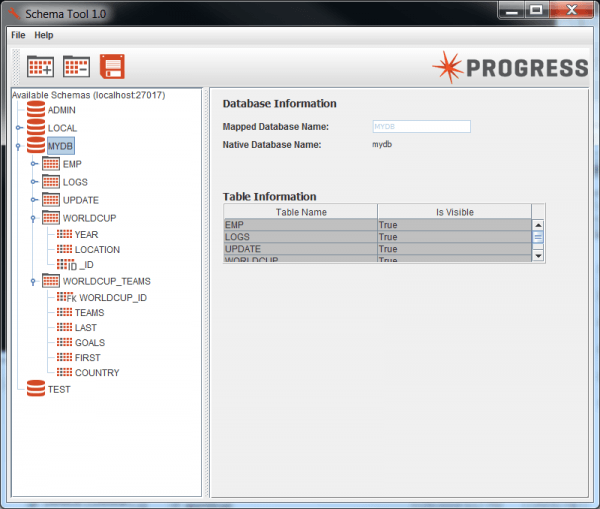
4- Launch Tableau and connect to MongoDB ODBC data source
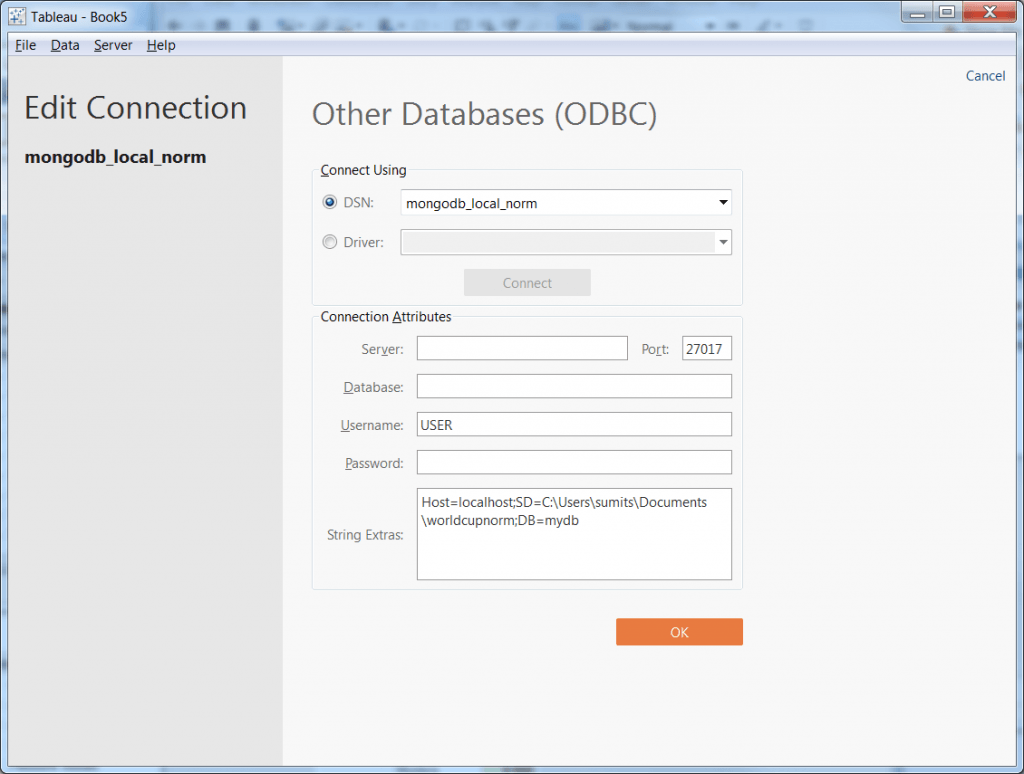
5- Bring in normalized virtual tables WORLDCUP and WORLDCUP_TEAMS. Note, this data resides in MongoDB within a single collection.
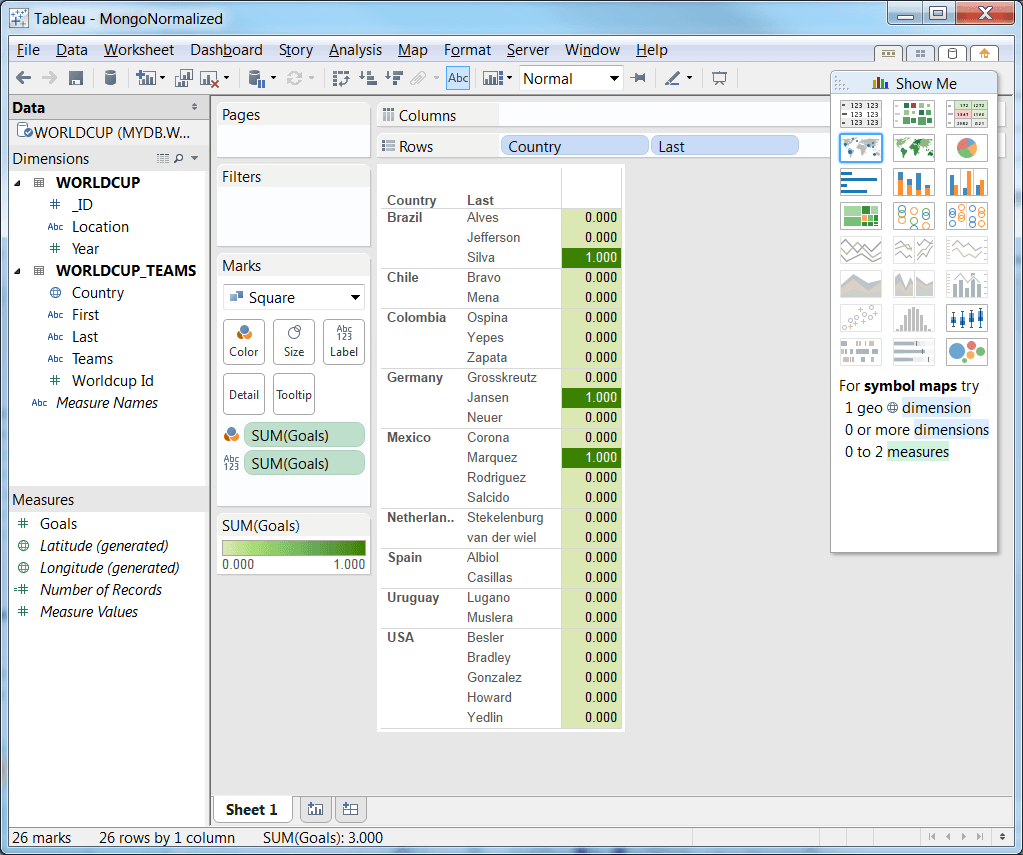
6. Now, you can ask a simple question such as goals by country and last name.
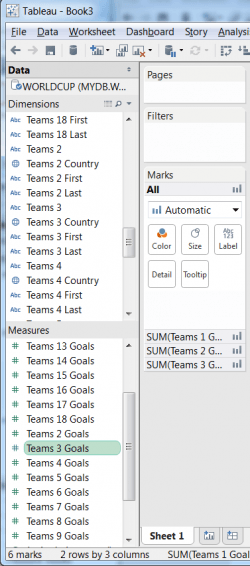
7. For comparison, it's impossible to ask the same question as step #6 when the data is exposed in a flattened schema like existing SQL connectors. Note how each individual team's players and goals are all separate measures and dimensions from the flattened view of the Worldcup data (TEAMS1_GOALS, TEAMS2_GOALS, TEAMS3_GOALS, etc). This approach does not represent MongoDB or NoSQL technology very well from Tableau.
What's the alternative to DataDirect's normalized and scalable virtual schema for Tableau?
To get an equivalent reliable connectivity experience from Tableau, you would need to:
- Sample MongoDB data to understand the data model
- Write mapping code to extract and normalize the data
- Physically load it into a relational database
- Create some kind of CDC capability for near real-time data connectivity
In summary, use the DataDirect MongoDB ODBC driver. It's easy to get started today. All you need to do is start a free trial, and you're off!
Try Now
Sample Data:
> db.worldcup.insert({ "_id" : 1, "year" : 2014, "location" : "Brazil", "teams": [ {"country" : "Brazil", "first" : null, "last" : "Jefferson", "goals" : 0 },{"country" : "Brazil", "first" : "Dani", "last" : "Alves", "goals" : 0 }, {"country" : "Brazil", "first" : "Thiago", "last" : "Silva", "goals" : 1 } , {"country" : "Chile", "first" : "Claudio", "last" : "Bravo", "goals" : 0 }, {"country" :"Chile", "first" : "Eugenio", "last" : "Mena", "goals" : 0 } , {"country" : "Colombia", "first" : "David", "last" : "Ospina", "goals" : 0 }, {"country" : "Colombia", "first" : "Cristian", "last" : "Zapata", "goals" : 0 }, {"country" : "Colombia", "first" : "Mario", "last" : "Yepes", "goals" : 0 } , { "country" :"Germany", "first" : "Manuel", "last" : "Neuer", "goals" : 0 }, {"country" : "Germany", "first" : "Kevin", "last" : "Grosskreutz", "goals" : 0 } , {"country" : "Mexico", "first" : "Jose", "last" : "Corona", "goals" : 0 }, {"country" : "Mexico", "first" : "Francisco", "last" : "Rodriguez", "goals" : 0 }, {"country" : "Mexico", "first" : "Carlos", "last" : "Salcido", "goals" : 0 }, {"country" : "Mexico","first" : "Rafael", "last" : "Marquez", "goals" : 1 } , { "country" : "USA", "first" : "Tim", "last" : "Howard", "goals" : 0 }, {"country" : "USA", "first" : "DeAndre", "last" : "Yedlin", "goals" : 0 }, {"country" : "USA", "first" : "Omar","last" : "Gonzalez", "goals" : 0 }, {"country" : "USA", "first" : "Michael", "last" : "Bradley", "goals" : 0 }, {"country" : "USA", "first" : "Matt", "last" :"Besler", "goals" : 0 } ] } )
WriteResult({ "nInserted" : 1 })
> db.worldcup.insert({ "_id" : 2, "year" : 2010, "location" : "South Africa", "teams" : [ {"country" : "Uruguay", "first" : "Fernando", "last" : "Muslera", "goals" : 0 }, {"country" : "Uruguay", "first" : "Diego", "last" : "Lugano", "goals": 0 } , { "country" : "Netherlands", "first" : "Maarten", "last" : "Stekelenburg", "goals" : 0 }, {"country" : "Netherlands", "first" : "Gregory", "last" : "van der wiel", "goals" : 0 }, {"country" : "Germany", "first" : "Manuel", "last" :"Neuer", "goals" : 0 }, {"country" : "Germany", "first" : "Marcell", "last" : "Jansen", "goals" : 1 }, { "country" : "Spain", "first" : "Iker", "last" : "Casillas", "goals" : 0 }, {"country" : "Spain", "first" :"Raul", "last" : "Albiol","goals" : 0 } ] })
WriteResult({ "nInserted" : 1 })

