
At MarkLogic, we like to solve old problems with new ways of thinking. While many people are trying to find better ways to make operational and analytical databases interoperable, we decided to just combine the two. That’s right—you can use MarkLogic as a database for operations and analytics at the same time.
This isn’t just some aspirational architecture either, MarkLogic is doing this in production at a tier-1 investment bank where they are running their operational trade store on MarkLogic while simultaneously integrating with Hadoop to run MapReduce jobs for real-time big data analytics.
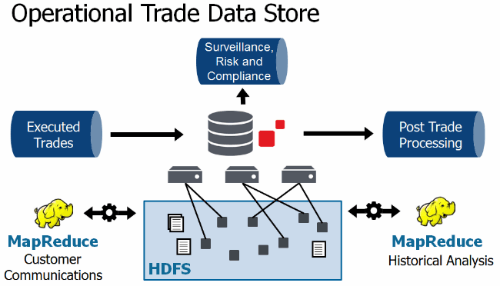
The example above shows an operational trade store architecture where, in addition to post-trade processing, MarkLogic also supports analytics, risk management and compliance, all from the same database. It also integrates with Hadoop for incremental enrichment of pre-trade communications (tying them to trade transactions), and for historical quantitative analysis.
The Best Tool For The Job
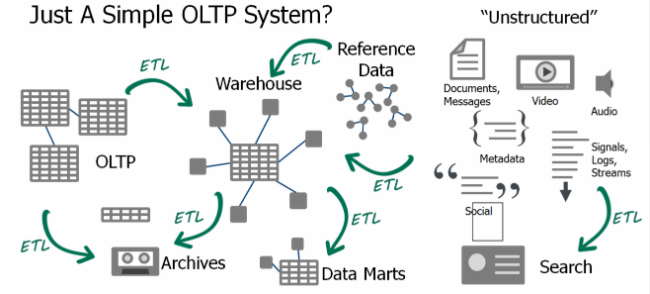
Had the bank taken the traditional route, using “the best tool for the job,” they would have used two different databases: one as an operational database and another database dedicated to analytics. Most databases simply cannot handle the different workloads due to the requirements for speed and capacity, so this approach used to make a lot of sense.
The operational database would be used for real-time ACID transactions to support the trade store. Then, the bank would have another database/warehouse/repository purpose-built for storing large data sets on which they would run analytics, either online or offline in bulk.
The problem, however, is that operational and analytic databases don’t work in silos. Operational databases and analytic databases must work in constant interaction, so you run into challenges trying to keep your analytic databases synchronized with your operational databases, and you end up having to manage multiple copies of the same data in different formats on different systems.
Rather than simply using the right tool for the job, pretty soon the bank’s architecture would start to look like an ETL mess, not the simple OLTP system originally planned.
A Better Database With Enterprise NoSQL
MarkLogic’s Enterprise NoSQL database simplifies the bank’s architecture by expanding on the typical responsibilities of the database. In fact, MarkLogic can act as a database, application server, and search engine all in one, but here we are just focusing on its capabilities to handle both operational and analytical workloads. Some of the key features that allow MarkLogic to run a variety of workloads include the following:
Shared Nothing, Scale-Out Architecture
A MarkLogic cluster can handle any-size dataset in a variety of formats, making it easy to just put all of your data in one place. MarkLogic’s distributed architecture also allows for very good query load separation, balancing the different operational and analytical loads across e-nodes and d-nodes.
Well-designed Indexes
MarkLogic has almost 30 indexes that can be toggled on and off, including range and geospatial indexes that can be used for in-database analytics. These indexes are what make it possible to have faceted search, aggregation and visualization, custom user-defined functions, co-occurrence, geospatial analytics, and integration with SQL, ODBC, and BI tools.
Tiered Storage and Replication
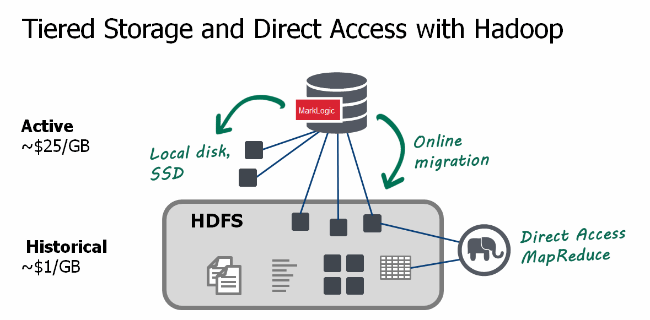
With MarkLogic, you can use any combination of SSD, local disk, SAN, NAS, HDFS, and Amazon S3 with real-time updates and guaranteed consistency. You can manage your storage tiers by policy (e.g., automatically archiving data that is more than 90 days old). This means you can keep your most recent and most important data in your expensive operational tier, but can still keep your other data available for analytic purposes in your less expensive tier (these tiers can differ between $1-25 per GB). And, you can run the same executables with the same APIs on all the tiers, so you can write one application that runs across them seamlessly and transparently.
Hadoop Direct Access
Direct access is a process whereby a Hadoop application can access the data in a MarkLogic data file without having to first mount it to a database. The implementation is very similar to file formats such as ORC (Optimized Row Columnar) or parquet (another Hadoop columnar file format) and uses a highly compact dictionary encoding on disk. With direct access, a MapReduce job can efficiently read all of the data in a MarkLogic data file. Thus, you’re able to index the data once for real-time queries and updates and leverage that same data format for large-scale batch processing. By using the same data format it is easy to maintain a single source of truth and reduce the amount of ETL required to translate data between operational and analytic environments.
A Single Source of Truth
With MarkLogic, the bank is able to have a single source of truth, a change that helps streamline operations, create more transparency, and save millions of dollars in the process.
Had the bank taken the traditional approach, it would have cost an estimated $16 Million just to duplicate the existing infrastructure (e.g., standing up Oracle, SQL Server, and mainframe instances in central archive). This doesn’t even include the reduced amount of time it takes to integrate application with MarkLogic, a significant factor for the dozens of legacy applications at the bank, some dating back to 1999.
By combing operational and analytical databases, the bank is also finding major improvements to security, privacy, and compliance. For example, the bank can easily manage its long term data retention program to create a permanent archive of relevant business records from trading, client info, settlements, etc. for the purposes of investigations and regulatory responses. And, there is only one “front-door” to the data because the same security policies can be applied to the operational and analytic databases because they are a single system.

