MicroStrategy and NoSQL MongoDB ODBC Meetup

Last week, I was invited by the local MicroStrategy User Group to talk about making sense of MongoDB data with MicroStrategy. According to my new friends, MongoDB is surfacing in business applications including call centers, master data management, order management repositories, and more. Rather than letting the new technology cause disruption, this group decided to take control and contact Progress DataDirect for a NoSQL data dive.
DataDirect MongoDB ODBC drivers disrupt disruption at MicroStrategy shops
It was great to get feedback from the group that reinforces our unique approach to MongoDB connectivity. Because I think this information is so important, I wanted to share it with you as well.
The following is a recap of the demo I gave for MongoDB ODBC connectivity from MicroStrategy Analytics Desktop:
- Download and install the Progress® DataDirect® MongoDB ODBC driver (32-bit for MicroStrategy Analytics Desktop).
- Launch 32-bit ODBC Administrator using the shortcut from the DataDirect MongoDB ODBC program group and create an ODBC Data Source, “MongoDB."

ODBC MongoDB Driver Setup
- In the advanced tab, set the following value in the extended options field for MicroStrategy compatibility:
defaultvarcharsize=255;leadingunderscorereplace=mongo
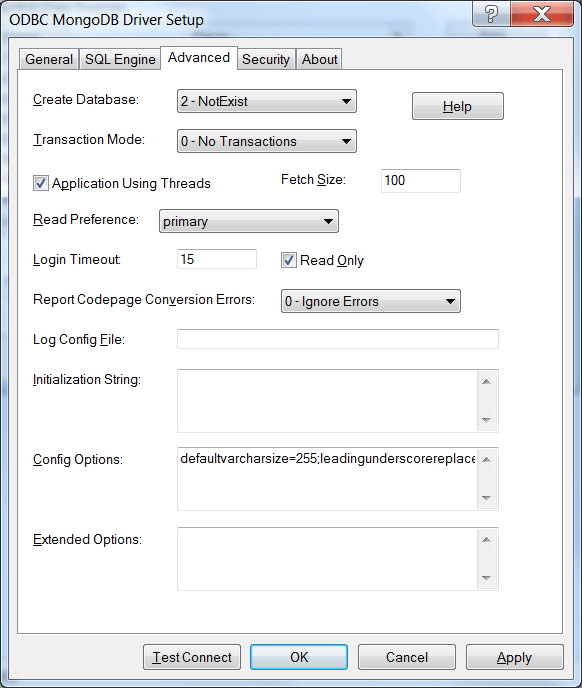
ODBC MongoDB Driver Setup, Advanced Tab Settings
- Launch MicroStrategy Analytics Desktop.
MicroStrategy Active Desktop example
- Click Database > Import.
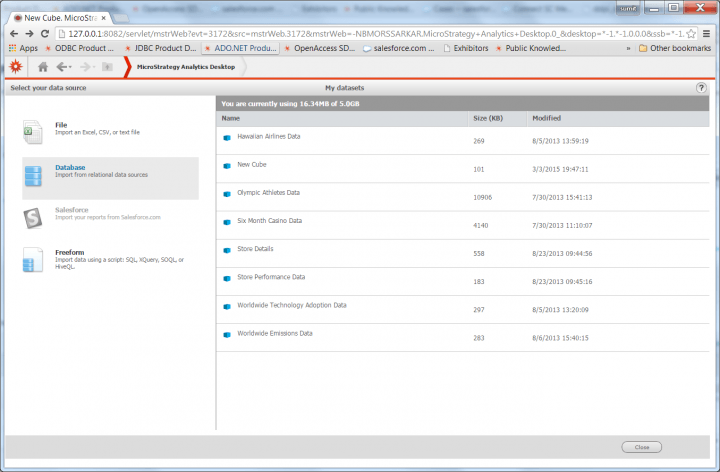
Importing your database into MicroStrategy
- Select the DSN Connections radio button and choose your “MongoDB” ODBC DSN.
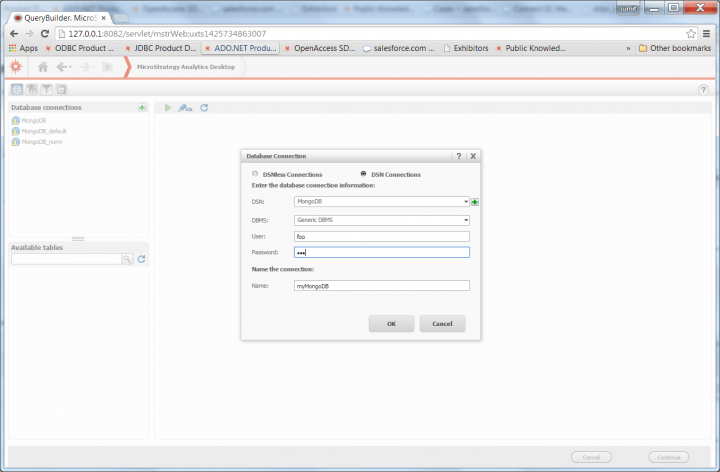
Choosing your "MongoDB" ODBC DSN
- Bring in the tables from the DataDirect MongoDB schema which normalized the collection designed for reliable SQL querying. You will notice child tables were set up with foreign key relationships to avoid data loss from embedded documents or arrays. In my example, here are the collections stored in MongoDB:
> db.worldcup.insert({ “_id” : 1, “year” : 2014, “location” : “Brazil”, “teams”: [ {“country” : “Brazil”, “first” : null, “last” : “Jefferson”, “goals” : 0 },{“country” : “Brazil”, “first” : “Dani”, “last” : “Alves”, “goals” : 0 }, {“country” : “Brazil”, “first” : “Thiago”, “last” : “Silva”, “goals” : 1 } , {“country” : “Chile”, “first” : “Claudio”, “last” : “Bravo”, “goals” : 0 }, {“country” :”Chile”, “first” : “Eugenio”, “last” : “Mena”, “goals” : 0 } , {“country” : “Colombia”, “first” : “David”, “last” : “Ospina”, “goals” : 0 }, {“country” : “Colombia”, “first” : “Cristian”, “last” : “Zapata”, “goals” : 0 }, {“country” : “Colombia”, “first” : “Mario”, “last” : “Yepes”, “goals” : 0 } , { “country” :”Germany”, “first” : “Manuel”, “last” : “Neuer”, “goals” : 0 }, {“country” : “Germany”, “first” : “Kevin”, “last” : “Grosskreutz”, “goals” : 0 } , {“country” : “Mexico”, “first” : “Jose”, “last” : “Corona”, “goals” : 0 }, {“country” : “Mexico”, “first” : “Francisco”, “last” : “Rodriguez”, “goals” : 0 }, {“country” : “Mexico”, “first” : “Carlos”, “last” : “Salcido”, “goals” : 0 }, {“country” : “Mexico”,”first” : “Rafael”, “last” : “Marquez”, “goals” : 1 } , { “country” : “USA”, “first” : “Tim”, “last” : “Howard”, “goals” : 0 }, {“country” : “USA”, “first” : “DeAndre”, “last” : “Yedlin”, “goals” : 0 }, {“country” : “USA”, “first” : “Omar”,”last” : “Gonzalez”, “goals” : 0 }, {“country” : “USA”, “first” : “Michael”, “last” : “Bradley”, “goals” : 0 }, {“country” : “USA”, “first” : “Matt”, “last” :”Besler”, “goals” : 0 } ] } ) >WriteResult({ “nInserted” : 1 }) > db.worldcup.insert({ “_id” : 2, “year” : 2010, “location” : “South Africa”, “teams” : [ {“country” : “Uruguay”, “first” : “Fernando”, “last” : “Muslera”, “goals” : 0 }, {“country” : “Uruguay”, “first” : “Diego”, “last” : “Lugano”, “goals”: 0 } , { “country” : “Netherlands”, “first” : “Maarten”, “last” : “Stekelenburg”, “goals” : 0 }, {“country” : “Netherlands”, “first” : “Gregory”, “last” : “van der wiel”, “goals” : 0 }, {“country” : “Germany”, “first” : “Manuel”, “last” :”Neuer”, “goals” : 0 }, {“country” : “Germany”, “first” : “Marcell”, “last” : “Jansen”, “goals” : 1 }, { “country” : “Spain”, “first” : “Iker”, “last” : “Casillas”, “goals” : 0 }, {“country” : “Spain”, “first” :”Raul”, “last” : “Albiol”,”goals” : 0 } ] }) WriteResult({ “nInserted” : 1 })From the available tables, you’ll see WORLDCUP and WORLDCUP_TEAMS.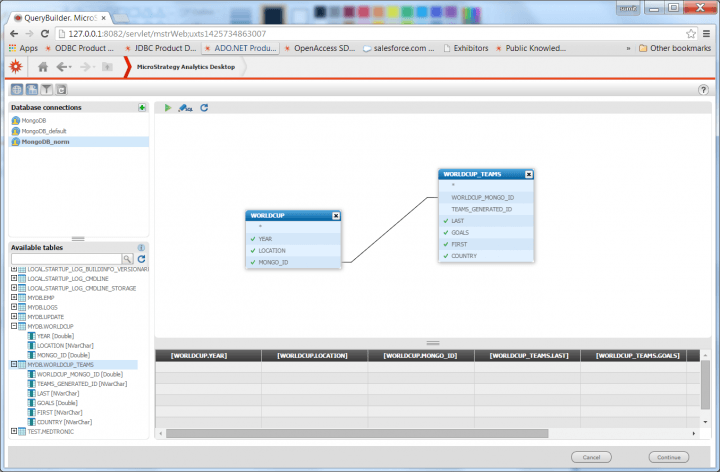
Example child table settings with foreign key relationships
- If you were doing this prior to Progress DataDirect’s introduction of reliable SQL query capabilities to the industry, the same data would look something like the following, which scared the room. (Sorry, guys!)
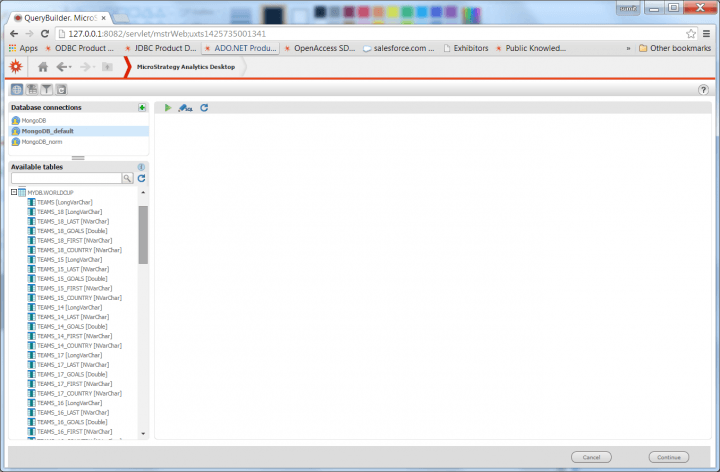
The same data shown without Progress DataDirect SQL query capabilities.
- After selecting the columns (shown in #7), we created a simple visualization calculating the count of teams and goals for each World Cup game. The MicroStrategy professionals thought this was pretty awesome when looking at the sample JSON documents.
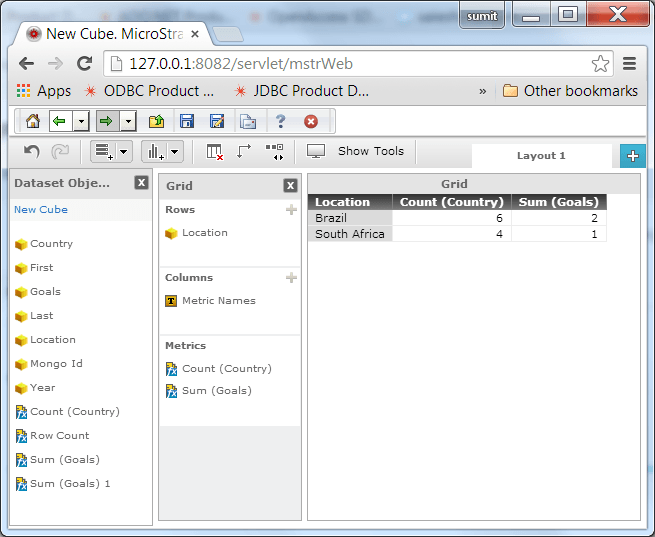
Data calculation from MongoDB data
Empowering User Groups one at a time
I always try to stay active in the community, so I had a fantastic time meeting with end users of our partner, MicroStrategy. I was also excited to learn about cool data capabilities in MicroStrategy that include data blending, data wrangling, multi source support and the Usher mobile identity platform … cool stuff!!
My favorite feedback was from a BI architect who planned on going back to the office to proactively look for disruptive sources to consume directly with the new MSTR data capabilities rather than play hot potato with the data warehousing team.
Other data source topics of interest mentioned include:
- Salesforce (SaaS)
- Cassandra (NoSQL)
- Google Analytics (Hyper Cube)
- Apache Spark (Big Data)
- Oracle Clouds (Eloqua, RightNow)
- VoltDB (NewSQL)
What next?
Sound interesting? If you want to give my demo a try for yourself, make sure you pick up a trial of our DataDirect MongoDB ODBC driver from our website.

