
MarkLogic has always invited the world to work with information in a different way. Instead of having to break apart your data so it can be stored in numerous tables, as you do with a traditional relational database, you store data in MarkLogic in the form in which it already exists—as documents.
With MarkLogic Semantics, introduced in MarkLogic 7, you have yet another way to represent your data: as one or more triples. A triple describes a relationship among data elements. It consists of a subject, predicate, and object (similar to human language):
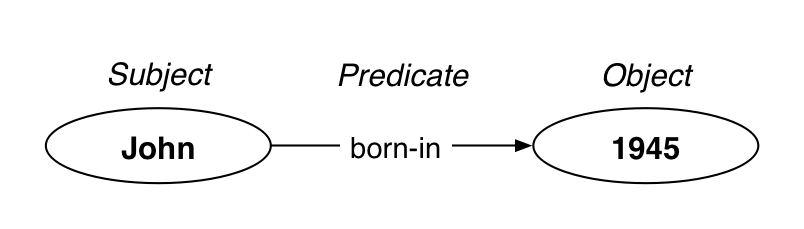
A key aspect of semantic data is not just that it describes relationships (that let you answer, “When was John born?”), but that these relationships can be interlinked. You can add more triples describing John, and also triples describing Mary, and some of these facts will intersect. This results in a connected web of information that can be represented as a graph:
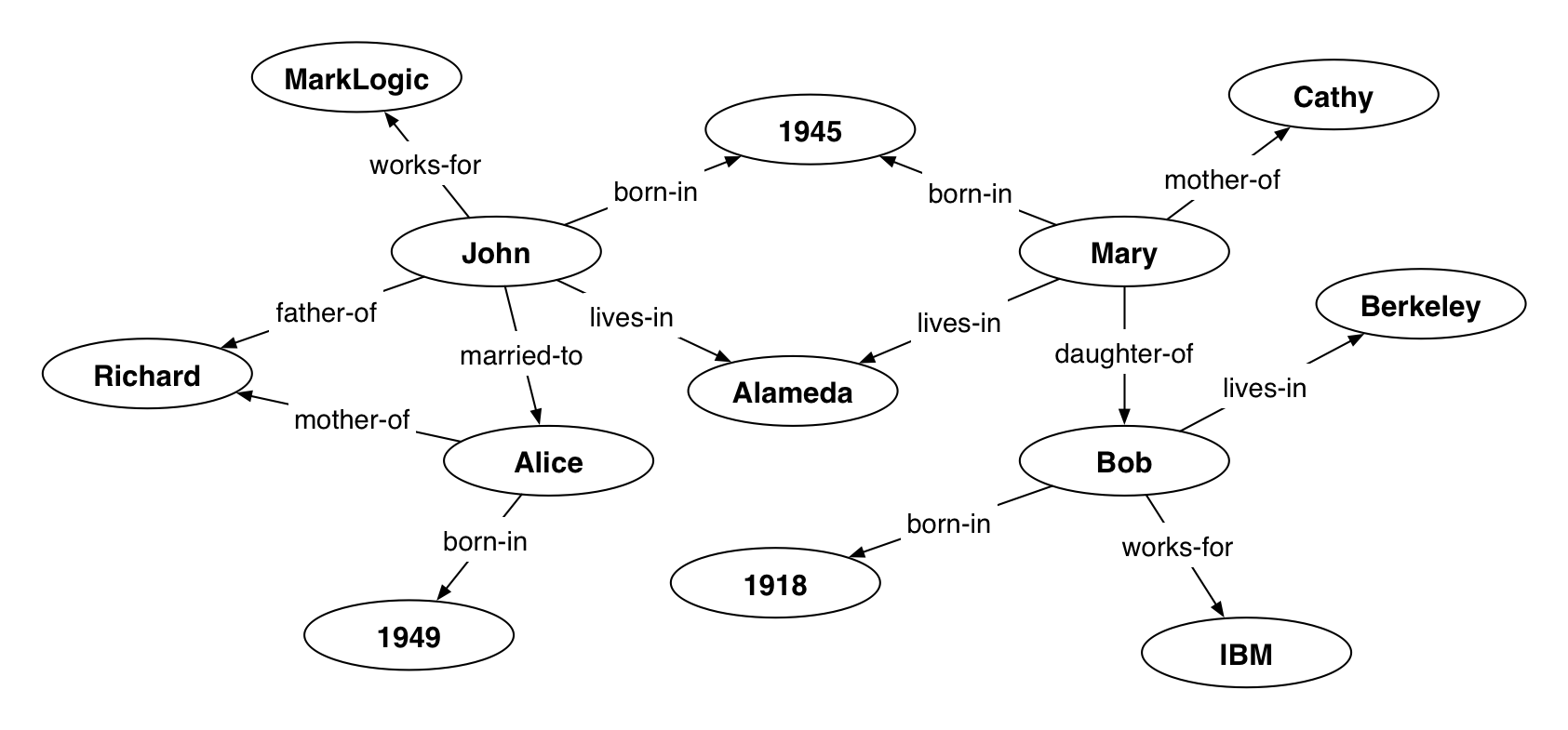
Presented with this new way of representing data, MarkLogic applications can parse large collections of triples to tell us interesting things. By quickly traversing a graph with lots and lots of facts, an application might tell us that John not only was born in the same year as Mary, but also lived on the same block and went to the same school. With the help of computers and semantic data, we can infer that John must have known Mary.
You can also combine triples with existing MarkLogic database documents. For example, you can use triples to define relationships between documents (by linking together document URIs) or you can embed triples within documents as a way to add metadata.
How does MarkLogic store and analyze semantic data? In many ways, MarkLogic works with triples similarly to how it works with other information. Triples themselves can be represented as XML or JSON documents, and MarkLogic can store them just like it does other kinds of data. This lets MarkLogic Semantics leverage all the existing enterprise features of MarkLogic such as security and transactional integrity when it comes to handling this new type of data.
But to be able to retrieve semantic data efficiently, and to be able to answer the complex questions people want to ask about the data (such as how facts about John are connected to all the other facts in our complex world), MarkLogic has developed some new and powerful techniques. These include special indexes for organizing triples and clever methods for optimizing complex semantic queries.
Storing Triples
Resource Description Framework (RDF) is the standard that describes how to represent facts using subject-predicate-object triples. In RDF, subjects and predicates are represented by internationalized resource identifiers (IRIs). IRIs are similar to URIs but have broader support for international characters. Objects can be IRIs but also can be typed literal values such as strings, numbers, and dates.
RDF describes conceptually how to define semantic information, but it doesn’t specify a format for representing triples. There are a variety of standards for representing RDF triples, some in XML and JSON formats, and MarkLogic can ingest triple information written in a number of them. Triples can also be added to MarkLogic using a variety of programmatic APIs. You can read more about loading triples. Here are examples of RDF triples in XML and JSON formats:
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:person="http://example.com/person#">
<rdf:Description rdf:about="http://example.com/person#John">
<person:bornOn rdf:datatype="xsd:date">1945-06-20</person:bornOn>
</rdf:Description>
</rdf:RDF>{ "http://example.com/person#John":
{ "http://example.com/person#bornOn":
[ { "value": "1945-06-20",
"type": "literal",
"datatype": "http://purl.org/dc/elements/1.1/date" } ]
}
}When MarkLogic ingests a triple, it turns the triple into an XML representation and then loads it as an XML document. So under the hood, MarkLogic represents semantic data the same way it represents regular XML documents. Consequently, triples can be managed with all the features and conveniences associated with other MarkLogic content. For example, they can be protected with role-based security, organized in collections and directories, and updated within ACID-compliant transactions.
Semantic triples can even be added to traditional XML or JSON content, by enclosing the triples in sem:triple tags (for XML) or in triple properties (for JSON). This enables you to enhance existing documents with subject-predicate-object facts and then search the content using both regular and semantic search strategies (more on this in a moment).
Triple Indexes
Indexes are the key to searching in MarkLogic. To support non-semantic search, a typical index maps all the terms in a database to the IDs of the documents in which they appear. To resolve a search for cat, the system looks up the index entry for cat and returns the corresponding documents. For semantic search, MarkLogic needs to support search patterns that represent triples, so the index structure for triples is slightly different.
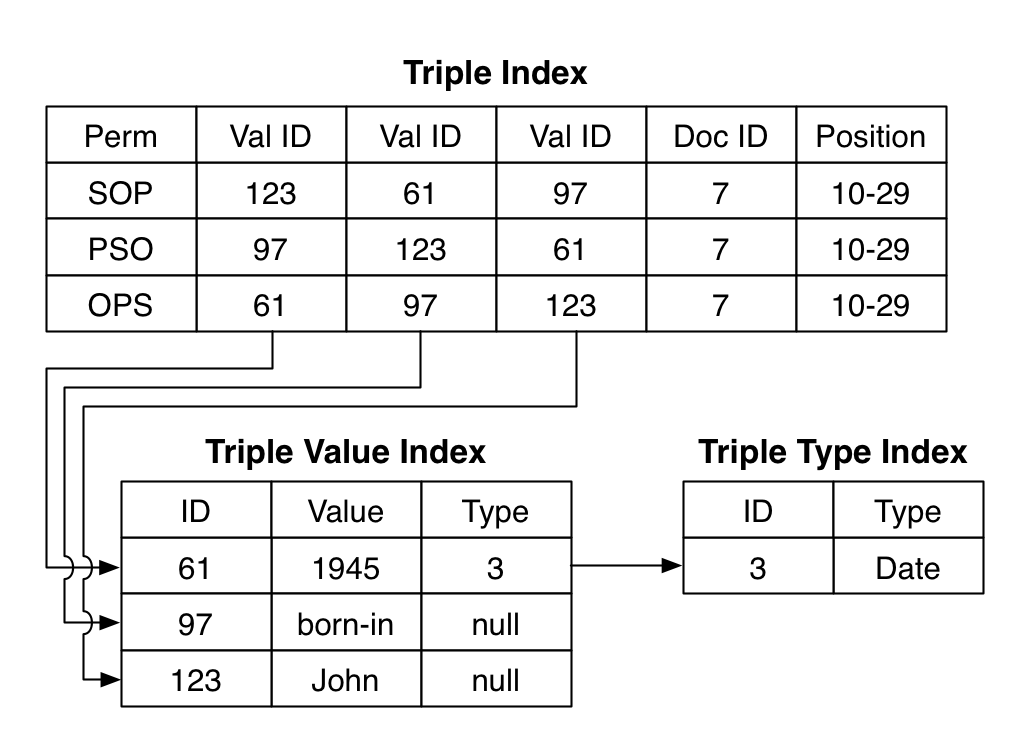
There are three special indexes for semantic search: a triple index, triple values index, and triple type index. The triple index stores the representations of the triples. You can think of each index entry as having three columns—for a triple’s subject, object, and predicate. There is also a column for mapping the triple to its corresponding document and columns for position information (if triple positions is turned on).
The order in which the three elements of a triple are stored impacts how fast MarkLogic can resolve a search. For instance, depending on the structure of a query, it might be faster to have the first element be the subject, predicate, or object. For this reason, each triple is stored as three different permutations in the triples index: subject-object-predicate, predicate-subject-object, and object-predicate-subject. An extra column in the triple store index specifies the permutation. Being able to choose among these three different permutations helps the system search as fast as possible.
The triple index doesn’t actually store the values (IRIs or literal values) that occur in each triple. Instead, the index represents them by integer IDs for faster lookups. The IDs are mapped to actual values in the triple value index. When triples are retrieved from the triple index for a search result, MarkLogic reconstructs their values by referencing the triple value index. This means that to return results for a semantic query, MarkLogic only has to access the triple indexes and not the original documents, which makes returning semantic results fast.
As mentioned earlier, object values in triples can be typed literals (strings, dates, numbers, etc.). MarkLogic takes this type information, and any other information not necessary for value ordering (e.g., date time zone information), and stores it in a triple type index. A null value in the triple type index means the value is an IRI. The triple type index is usually relatively small and can be memory mapped for fast access (unlike the other indexes).
Conceptually, the index structure for semantic triples in MarkLogic looks like this:
Querying for Triples with SPARQL
You can search for triples in your MarkLogic database using SPARQL, a query language for retrieving semantic data. It’s a lot like using SQL but for triples. To construct a SPARQL SELECT query, the most common type, you describe one or more triple patterns using IRIs, literal values, and variables. The XQuery and JavaScript APIs include semantic functions that let you write SPARQL queries. You can also run SPARQL inside MarkLogic’s Query Console and with the REST API.
For example, let’s say you have semantic data about university mascots that looks like this:
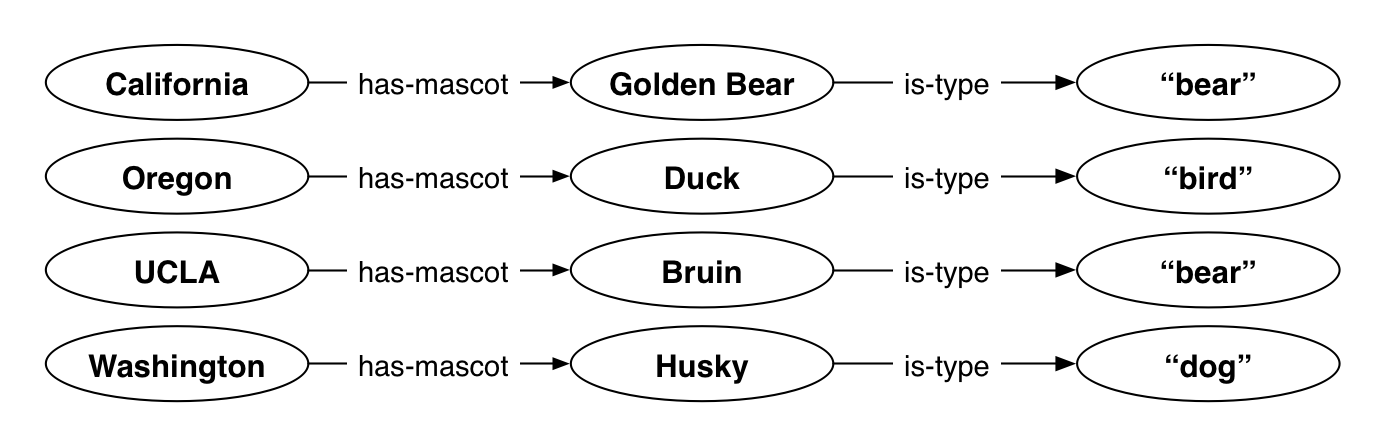
Each line above represents a pair of triples. The first triple describes the school’s mascot, and the second describes the mascot’s type. The following SPARQL query returns schools that have mascots that are bears:
SELECT ?school
WHERE {
?school <http://example.org/has-mascot> ?mascot .
?mascot <http://example.org/is-type> "bear"
}In SPARQL, variables are prefixed by the ? character, and values from matching triples are bound to that variable. IRIs are enclosed in brackets, and multiple patterns in a query are separated by the . character. In this example, the query’s WHERE clause defines two triple
patterns.
To resolve the query, MarkLogic processes each pattern and finds the triples that match in the triple index. The first pattern matches everything and returns four triples. For the second pattern, two triples are returned—the ones with "bear" as the object. To get the final result, MarkLogic joins the two sets of matches based on a shared variable—?mascot. This gives us two joined results. MarkLogic returns the IRIs for California and UCLA as the final result based on the ?school variable in the SELECT clause.
The example above is simple, but it demonstrates the two key steps in resolving a semantic query: retrieving triples corresponding to each pattern and then joining those sets of triples to get a final result. Complex SPARQL queries can include many more triple patterns as well as operators for modifying your query and filtering your results. Some of the operators will be familiar to those who have written relational queries in SQL (such as ORDER BY and LIMIT). You can read more about the SPARQL language and MarkLogic.
SPARQL queries can also be combined with the other types of MarkLogic search queries. Combining such queries is actually straightforward, since triples are stored as documents just like all other content in the MarkLogic database. When a SPARQL query returns a set of triples, those triples are associated with a set of document IDs. MarkLogic can intersect these document IDs with the document IDs returned from any other type of query. This lets us restrict our SPARQL search results to those triples associated with, for example, a certain collection, directory, or security role.
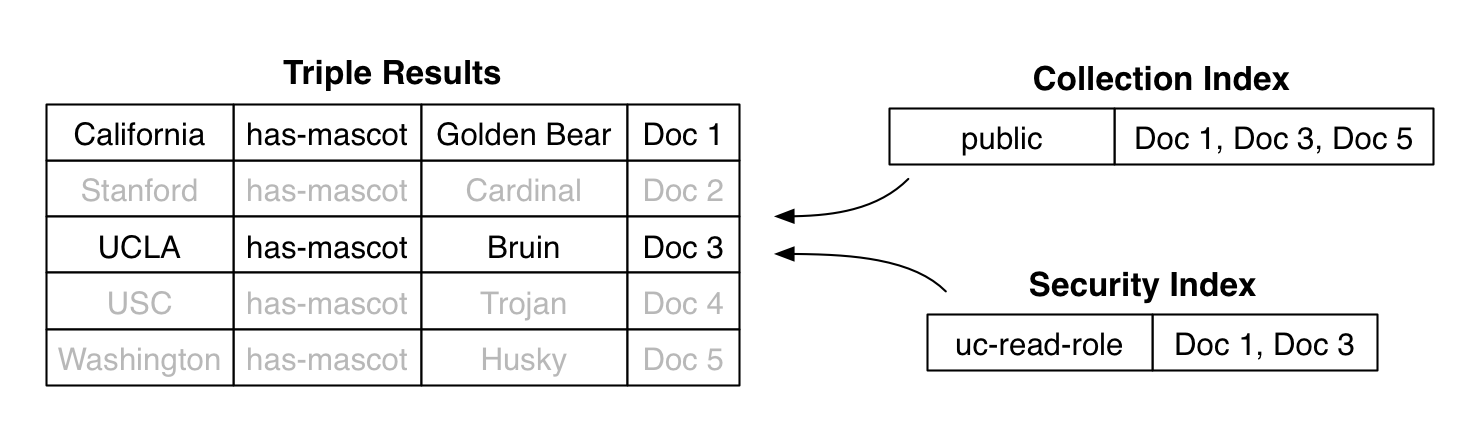
Figure: You can combine SPARQL queries with other types of MarkLogic queries. This lets you restrict the triples returned to, for example, certain collections or security roles.
Combination queries are especially useful when you have triples that are embedded in XML or JSON documents. You can write queries that search for specific words or phrases in the regular content of the document alongside SPARQL queries that search for triples stored in the same document. MarkLogic returns only the triples that satisfy all the parts of the combination query.
Optimizing Queries
There are a number of ways MarkLogic optimizes how it resolves a SPARQL query. The first is by limiting the number of entries it needs to check in the triple store index. When processing a triple pattern, MarkLogic first looks up any values that are present in the triple values index. Because the terms in the triple values index are stored in order and mapped to the triple index, MarkLogic can use the triple values index to narrow the range of the entries it needs to check in the triple index for that pattern. Or, if it sees that a value doesn’t exist at all in the triple values index, it knows the triples don’t exist in the triple index either and can stop looking.
Another way MarkLogic optimizes query resolution is by choosing the best permutation (out of the three permutations that are stored for each triple) when performing lookups in the triple store index. What makes one permutation better than another? In many cases, MarkLogic can join sets of triples more efficiently if both the sets are in order. Sometimes MarkLogic can ensure that sets are in order by retrieving them using a certain permutation. In our example, MarkLogic joins two sets of triples based on their ?mascot values. By retrieving the initial index data such that each set comes out ordered by the ?mascot value, MarkLogic can potentially use a faster algorithm when it comes to the join step.
There are a number of ways to join sets of triples when resolving a SPARQL query. Each has pros and cons that depend on the size of the sets being joined, whether the sets are in sorted order, and other factors.
- Hash join: This strategy takes one set of triples and puts them into a hash table, indexed on the value being joined. It then uses the hash table to find matches to the other set of triples. The hash join strategy is effective when one of the triple sets is small and the resulting hash table can be stored in memory, making the comparison step very fast.
- Scatter join: This strategy is similar to the hash join strategy but with an extra preliminary step. It takes the values being joined from one set and uses those values to constrain the lookup that generates the second set. In our example, a scatter join could take the mascot terms from the
is-typepattern and use them when resolving thehas-mascotpattern. Once it has the two sets, MarkLogic performs a hash join as in the previous strategy. Using a scatter join can be more efficient since it results in a smaller second set of triples; the tradeoff is that you can’t resolve the two sets in parallel as you can with some other types of joins. - Bloom join: With this strategy, MarkLogic hashes one set of triples into a compact representation, a short array known as a bloom filter. It can then use the bloom filter to check the second set of triples and perform the join. A bloom join has the advantage of using a small amount of memory. The disadvantage is that it can produce false positives. (False positives can be removed with a MarkLogic filter step after the join.)
- Merge join: This is a very efficient join strategy, but it only works when both sets are sorted by the term MarkLogic is joining. MarkLogic works through the sets of triples together in a single pass, comparing the values and joining the triples that match. To leverage merge joins, MarkLogic can try to ensure that the two sets are ordered by choosing the right permutation from the triple index.
Finding the Right Query Plan
Often times MarkLogic can solve a complex SPARQL query in any of a thousand different ways, depending on how it chooses to retrieve and combine the many sets of triples involved. MarkLogic can choose different join algorithms when merging sets of triples. It can execute the joins in different orders. It can select different permutations when retrieving triples from the triples index. The way MarkLogic structures the operations to solve a SPARQL query is called the query plan. The more efficient the query plan it can devise, the faster it will be able to return the results.
What MarkLogic doesn’t do is attempt to figure out the very best query plan using a fixed set of rules. Instead, it uses an algorithm called simulated annealing that takes advantage of computer-based natural selection to find a highly optimal plan in a fixed amount of time.
MarkLogic starts with a default plan based on how the SPARQL query is written, then estimates the efficiency of that plan using cost analysis. The analysis takes into account the cardinality of the triples, the memory used by the joins, and whether intermediate results come back ordered or unordered, among other things. (MarkLogic gathers some of the statistics used for cost analysis, such as the cardinality information, as it loads and indexes the triples.)
Then to improve the plan, MarkLogic:
- Mutates the operations in the plan to create a new version that will still return the same result. For example, it could use different join strategies or change the order of the joins.
- Estimates the efficiency of the new plan using cost analysis.
- Compares the efficiency of the new plan with the efficiency of the current plan and selects one or the other.
Next, if time’s up, it stops and uses the plan it has chosen to execute the SPARQL query. Otherwise, it repeats the steps.
During the selection process, MarkLogic will always choose the new plan over the current plan when the new plan’s efficiency is better. But there’s also a chance it will choose the new plan if the efficiency is worse. This is because query plans are related to one another in unpredictable ways, and discovering a highly optimal plan may require initially selecting an intermediate plan that is less efficient. As time goes by, the probability that MarkLogic will choose a new query plan that is less efficient goes down. By the end of the process, MarkLogic will have found its way to a plan that’s highly optimal (but not necessarily the most optimal).
This strategy for choosing a query plan offers an advantage: you can specify the amount of time MarkLogic spends optimizing by passing a setting in with your SPARQL query. You can allow more time for finding efficient strategies for complex queries and less time for simpler ones. You can also allow more time for queries that are run repeatedly for long periods of time. This is because MarkLogic will optimize such a query the first time and then store the optimized query plan in its cache. For subsequent executions, it can retrieve the plan from the cache.
Thanks to John Snelson, Stephen Buxton, and Charles Greer for their help with this article.

