Llama-REMi v1: The Next Evolution in RAG Evaluation

Previously published on Nuclia.com. Nuclia is now Progress Agentic RAG.
Our commitment to innovation drives us to continually refine the tools and technologies we provide to our clients. Today, we’re excited to introduce Llama-REMi v1, the successor to REMi v0, our groundbreaking open-source Retrieval Augmented Generation (RAG) evaluation model. While REMi v0 set a high standard for RAG evaluation, Llama-REMi v1 takes this technology to the next level, with significant improvements in speed, alignment and usability.
Building on the Foundations of REMi v0
REMi v0 marked an important milestone in RAG evaluation, as it was the first open model to be specialized on RAG evaluation. Built on Mistral AI’s Mistral 7B model, it offered a reliable, efficient way to assess the quality of RAG pipelines. The open-source release of REMi v0 and its accompanying library, nuclia-eval, empowered the community to adopt and implement efficient RAG evaluation methodologies instead of relying on large foundational models.
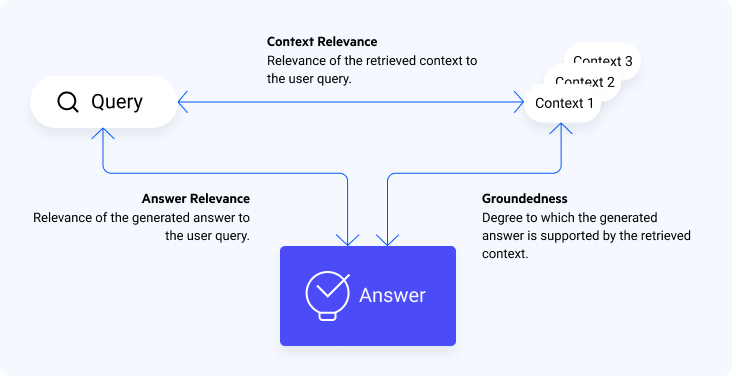
It’s evaluation, based on the RAG Triad provides, three metrics:
- Answer Relevance: Relevance of the generated answer to the user query.
- Context Relevance: Relevance of the retrieved context to the user query.
- Groundedness: Degree to which the generated answer is grounded in the retrieved context.
Even though REMi v0 was a success, we recognized opportunities for improvement. The feedback highlighted the need for faster inference speeds and even better alignment with human judgment. With these goals in mind, we embarked on the journey to create Llama-REMi v1.
The Power and Improvements of Llama-REMi v1
Llama-REMi v1 leverages the Llama 3.2-3B base model, a more powerful and efficient foundation compared to its predecessor. This choice was driven by the need to provide higher accuracy while maintaining lightweight and accessible deployment options. Llama-REMi v1’s training incorporated the same dataset as REMi v0, with enhancements to improve context relevance alignment with human judgment. Notable advancements include:
- Rescaled Context Relevance Scores: Context relevance evaluation has been redefined in Llama-REMi v1 to better match human interpretations. In REMi v0, context relevance scores were often too strict, which misaligned with user expectations. By rescaling the training dataset with updated methods, such as incorporating a reranker to weight the score, we’ve ensured that context relevance more accurately reflects the effectiveness of the retrieval step. This adjustment not only improves model alignment but also enhances interpretability for end-users.
- Enhanced Alignment: With its upgraded base model, training-time improvements and improved context relevance scoring, Llama-REMi v1 delivers evaluations that better align with human judgment, ensuring more accurate and actionable metrics.
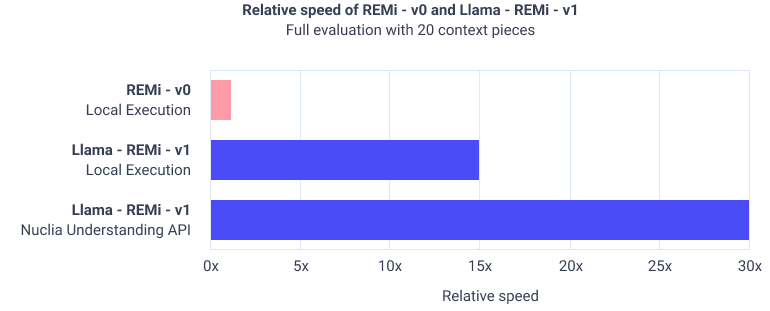
- Optimized Inference Speed: Hosted on specialized inference servers, Llama-REMi v1 delivers up to 30x faster evaluation times compared to REMi v0. This allows the evaluation to be much faster and opens up the possibility for clients to evaluate an interaction as soon as it is completed.
- Served through Nuclia Understanding API: Aside of offering automatic evaluations through our client in their Activity Log, we deployed a new endpoint so that they can leverage REMi at their wish and evaluate any given RAG interaction, with any or all of the metrics available.