
We all start out Jerry Seinfeld jokes with the phrase, “What’s the deal?” “What’s the deal with airline food?” He didn’t really use that phrase much, just like Andy Rooney never really said “Didya ever notice?”, but in my head when I ask the question “What’s the deal with XML?” I do it in a Jerry Seinfeld voice.
What is the deal with XML? In my last post I spoke about the reasons why XML (and JSON) are turning out to be a really big deal in the world of Big Data. Such a big deal that we needed to create a database that perfectly houses and leverages XML. Here’s the back story.
History of Database
In many ways XML databases are a return to the roots of the database. Before the world of rows and columns, all databases were document based. The original database was created in 1890 by Herman Hollerith an American inventor who was under contract to the US Census Bureau and built a tabulating machine using mechanical punch cards. Every record, was not only figuratively a document, it was literally a document.
In the 1950s computer makers found a way to speed up the reading of records, but the medium was the same: punch cards. In the 1960s and ’70s the physical documents gave way to electronically stored data files, but the early flat file databases were still comprised of documents. The first real departure away from a document database came with the modern relational database, first theorized in the late 1970 and brought into production in the late 70s and early 80s.
Advent of Relational
The relational database had some advantages over its document based parents, like being freed from proprietary hardware platforms and being able to serve multiple applications at the same time. It was also navigable using a “structured query language” or SQL. But it forced us to give up things as well. The advancements in speed and conservation of space required a rigid structure and data that looked the same across the tables and rows.
The historical “flat files” of the mainframe, with all their flaws, were less structured or “de-normalized” and allowed the designer the ability to craft the column the way they wanted and decode it later. Now everything had to fit in a standard format.
At the same time that relational databases were becoming more structured, programming was about to become a lot less structured. Traditionally programming was rigid and required code to be compiled or made into an executable to be interpreted by an operating system. But web pages were more like articles and less like computer programs, after all you browse the web like you do a newspaper. The pages simply needed to be “marked up” so that the browser knew when to bold and when to underline. Editors had been doing this for years with SGML.

A consortium of folks came up with the HyperText Markup Language or HTML and that became the backbone of the Internet. As more and more data traversed the web, another group saw the need for a data markup language that could take data in any format and transport it.
They could not predict column length or data type or really anything about the data. The language needed to be extensible and they thought using a similar style markup language to HTML would be convenient. And thus the eXtensible Markup Language or XML was born.
The beauty of XML was that is was self-describing. Each data field was declared prior to being used, and it could store any kind of data. The publishing industry had a huge advantage on the rest of the world when it came to HTML and XML because they had a lot of content and they were very familiar with the traditional markup process, having basically invented it. Shifting to digital markups was not that big an endeavor.
Best Database for XML — An XML Database (Of Course!)
As more and more data was converted into XML they needed a place to put it. Storing files in a file system was efficient, but those systems lacked the ability to search it and organize it. By now databases were all relational. Structures were fixed and stored in schema. XML was not. Combining XML and relational meant losing all the flexibility of XML. XML needed its own database. Out of desperation, the document database was (re)born.
XML was slow to catch on outside of a few industries. Publishing invested in it and a few others, but America’s darkest day would actually be XML’s moment to shine. September 11th revealed the failure of the rigid database. The intelligence community had all the information to connect the dots but couldn’t. The individual agencies didn’t share systems or file formats. Coming up with a unified data model to account for any kind of data was impossible on relational — but was run-of-the-mill for XML. XML began to proliferate the 3-letter agencies, which now could ingest data in any format and analyze it using powerful search capabilities and indexes, as good or better than were offered on relational. XML database vendors, like MarkLogic, brought along enterprise grade features like security, consistency, high availability and disaster recovery.
But intelligence agencies and publishing verticals did not have a lot of crossover into the commercial space. The XML database languished in relative obscurity throughout the first decade of the digital millennium. But another disaster would press XML into service in a big way.
Banking and XML
The 2008 financial meltdown forced intense scrutiny on to the financial service industry. It was clear from the events of the crash that in many cases the right hand did not know what the left was doing. Federal regulators demanded swift action, backed up by tough new legislation like Dodd-Frank. The banks needed to act quickly.
The banking industry had come to rely on relational technology. Account numbers and dollar balances fit nicely into the rigid format. But now they were being asked to produce a comprehensive look across 20 or 30 different systems and answer questions that were “to be determined.” How do you plan a database project when the sources are potentially unknown and constantly changing, and the reporting requirements can’t be immediately determined? Well, you can’t. It can’t be done with relational!
The Publishing and Intel communities offered up their secret: The document database. Any data source could be ingested as is and then the data could be joined together as it left the database, not as it was being collected. XML offered the flexibility to define each record independent of the next. Projects that had been in the works for years with no real progress were suddenly getting done in a matter of months. In one case the deal to purchase software took longer to weave its way through the procurement process than it did to roll out the first version of the solution.
Healthcare and XML
A few years later the Insurance industry began to take notice as HealthCare.gov was coming online. They had tried and failed with a relational model, because, as before with the financial services industry, the data sources could not be predicted or controlled. In this case, each state regulated insurance and dictated how the policy information was provided. The government did not even know how many states were going to participate until February of 2013, with the first open enrollment period beginning in October of that year.
Further complicating matters was the amount of personal information that had to be collected and referenced on each application to determine eligibility for tax subsidies. Had the system tried to enforce a rigid format for data exchange between all those parties, it would not have had a chance.
Although HealthCare.gov did have a rocky rollout, it was largely connectivity and data center issues. During the last open enrollment period of 2015, 12.7 million Americans bought insurance through the federal exchange in the span of 90 days; all that without a hint of trouble. XML databases had hit the big time.
Along the way there have been improvements. Along with XML, the Javascript Object Notation format or JSON was created and offers the same flexibility as XML, backed up by the power of Javascript, which has become ubiquitous in Internet development.
XML database developers are no longer forced to use proprietary APIs or niche languages like Xquery or Xpath to interrogate the data. MarkLogic supports direct data access using Java, Javascript/Node.js, REST and SQL along with the traditional XML options. Data can be stored in either XML or JSON and the database accommodates structured data along with unstructured data, text and binary objects.
Introducing the Multi-Model Database
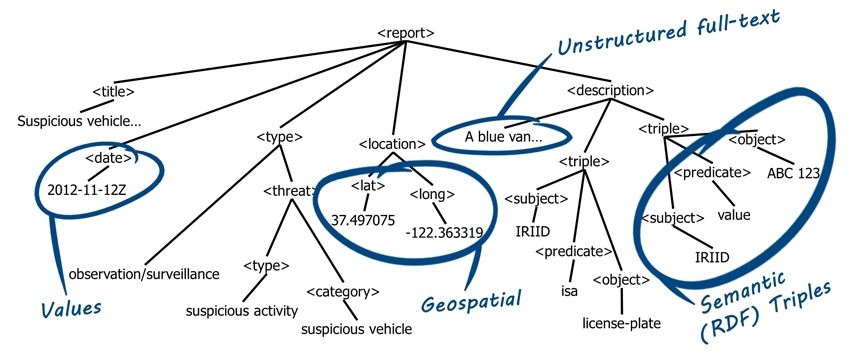
While government and publishing dominated the early days of XML databases, financial services, healthcare, retail and manufacturing companies are rapidly adopting the flexibility and power of the document database. MarkLogic has continued to expand and now operates as a Multi-Model database able to store XML/JSON documents, key/value pairs and RDF triples.
As a result, MarkLogic is no longer a sleepy little XML database or search engine vendor. It’s eponymous database now appears on 3 different Gartner® Magic Quadrants including the Magic Quadrant for Operational Database Management Systems. In the beginning, document databases were a niche, but they are fast becoming the best way to integrate data from silos, and MarkLogic is now one of the preeminent vendors.
The punch line to the question “What’s the deal with XML” isn’t as funny as a Seinfeld joke, but it does have the same kind of universal reach. XML databases now run some of the world’s largest applications and their momentum is growing. I don’t see relational going away anytime soon. After all, Mainframes are still around. But document databases are proving their value in major organizations everyday. In fact, do you know what would be a great place to store all that Mainframe data? That’s right, an XML database…

