
A key feature of MarkLogic is ACID compliance. ACID stands for atomicity, consistency, isolation, and durability, and meeting these four requirements means that transactions in MarkLogic are reliable.
Consider a transaction that reads or updates properties in a set of documents. If another transaction simultaneously tries to update the same set of properties, will it conflict? What if there’s a system failure while a transaction is underway? Fortunately, MarkLogic is able to handle these tricky situations by being ACID-compliant.
The ACID properties are defined as follows:
- Atomicity: A transaction is an atomic unit of work. Either all the data modifications in a transaction are performed or none of them are performed.
- Consistency: When completed, a transaction leaves all data in a consistent state. The data written to the database is valid according to all defined rules.
- Isolation: Transactions run in isolation from one another. This means that transactions running concurrently have the same result as if they were run one after the other.
- Durability: After a transaction is completed, its effects remain even in cases of unexpected interruptions. A durable database has mechanisms to recover from system failure.
Several key features enable MarkLogic to support the ACID properties:
- Document locks to protect data during updates and keep transactions from conflicting with one another
- Timestamps on documents that ensure a query only sees copies of documents that are valid at the time the query is run (also known as Multi-Version Concurrency Control)
- Journaling of updates before they are committed to ensure transactions can be replayed in the face of system failures
- A commit process to ensure changed data is changed all at once or not at all, even across multiple hosts
We’ll describe each feature and its relationship to the ACID properties. Our model will be a simple banking application built on MarkLogic, where bank accounts are represented by documents and each document holds a balance property.
Document Locks
Locks restrict what operations can be performed on a document by other transactions. By setting locks, MarkLogic helps ensure that transactions have a consistent (the “C” in ACID) view of the data they are working with and also run in isolation (the “I” in ACID) from one another.
There are two types of locks, read locks and write locks. When a transaction reads a document from the MarkLogic database, it obtains a read lock. Read locks don’t block other transactions from reading the same document, which is why read locks are also known as non-exclusive locks. However, read locks do block other transactions from writing a document. A transaction that wants to write a read-locked document has to wait for that read lock to be released.
Disallowing writes while a transaction is being read makes sense because we want consistency in our transactional reads. If we were to read a document a second time during a transaction, we wouldn’t expect that document to have been changed by other transactions—we would expect it to remain consistent.
A transaction obtains a write lock when it wants to update a document. Read locks held by other transactions block write locks, as do other write locks. Write locks are also known as exclusive locks because they block all other transactions from accessing a document. Only one transaction can hold a write lock on a document at a time.
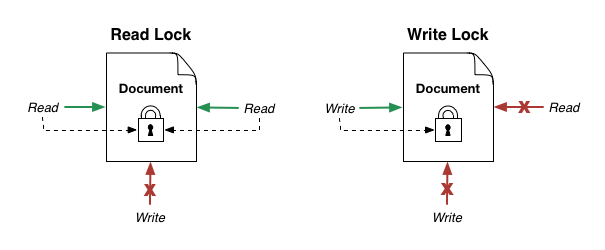
Figure 1: A read lock allows reads by other transactions but blocks other writes. A write lock blocks reads and writes by other transactions.
Consider our banking application. To update an account balance, we read the account document and obtain a read lock. When it is time to write the new balance in the transaction, the read lock is upgraded to a write lock. Until the transaction finishes, all other transactions are blocked from reading or writing the account document. Because of this exclusive nature, write locks enable transactions to run in isolation.
Lock-Free Queries
Locks are critical for MarkLogic transactions that perform updates to be ACID-compliant. But as it turns out, locks aren’t necessary for transactions that only perform queries (reads). This is possible because of how MarkLogic handles document updates.
MarkLogic associates each document in a database with creation and deletion timestamps. The creation timestamp is set when a document is first committed, and the deletion timestamp is set when a document is deleted. When MarkLogic performs a document update, it doesn’t update the current version of the document in place. Instead, it creates a new version of the document and gives this version a new creation timestamp. MarkLogic marks the existing version as no longer current by setting the deletion timestamp. Over time, multiple versions of a document can coexist in the database.
Queries can run without locks because each runs at a particular timestamp and only sees the documents that are valid at that point in time. Let’s consider a query that reads a bank account balance at timestamp 1000. Let’s imagine the balance takes a long time to retrieve. While the balance is being retrieved, another transaction changes that same bank account balance at timestamp 1001. (This can happen since queries do not acquire locks.) The query will not see that update because from its perspective this update hasn’t occurred yet.
This strategy of keeping multiple versions of documents to allow for reads without locks is called Multi-Version Concurrency Control (MVCC). It allows queries to run in isolation from updates that are happening at the same time and see a consistent view of the data that is valid at a particular point in time.
An MVCC setting lets you control how the system selects the timestamp for a query transaction. When set to contemporaneous (the default), MarkLogic selects the latest timestamp for which any transaction has been committed. At this timestamp, there may be other transactions still running, and your transaction will have to wait for them to finish to receive the query results. The contemporaneous setting gets the most up-to-date results but with a potentially slower response time. When set to nonblocking, MarkLogic selects the latest timestamp for which all transactions have been committed, meaning there are no uncommitted transactions at that point in time. The nonblocking setting gets results that could be out of date, but without having to wait for other transactions to complete.
On-Disk Journals
In MarkLogic, updated documents are initially saved to memory (in an in-memory stand). These in-memory documents will eventually be written to disk as more documents are inserted and the stand grows, but if there is a system crash, any documents that are currently in memory will be lost.
How do we make this in-memory information durable (the “D” in ACID)? MarkLogic (and most other database systems) solves this problem by writing information about updates to an on-disk journal before it writes the documents to memory. A journal is a way of keeping track of all the operations in a database that might need to be replayed in the case of a failure such as a system crash.
How is writing to a journal more efficient than just completing the entire transaction on disk? With journals, we’re only writing the data necessary to replay an operation. We’re not performing the indexing and other housekeeping tasks that go along with a real update.
Let’s imagine a balance transfer from one account to another in our banking application. We experience a system crash right after the account balance updates are committed to memory. Those in-memory changes are lost, but we get them back during a system reboot by using the journal to replay them. For efficiency, databases maintain a checkpoint value that points to the journal entry corresponding to the last update that was written to disk (i.e., the last durable update). During a recovery, the system only has to replay journal entries after the checkpoint to repopulate the in-memory stand.
What if a failure happens in the middle of a transaction? MarkLogic will know this during recovery because journals also keep track of transaction commit information. This allows the system to ignore any transactions that didn’t complete.
Committing Transactions
The commit step happens at the end of a transaction and is the key to achieving atomicity (the “A” in ACID) in a transaction. This step is where all the changes that occurred during the transaction are exposed to the rest of the world. If there is a failure at any part of the transaction, the transaction is aborted and any changes made so far are rolled back. It is as if the transaction never happened.
Let’s consider a balance transfer in our banking application, which involves reading and updating two account documents. As we described earlier, updating the bank accounts involves creating new versions of the account documents. During the transaction, MarkLogic inserts the new versions into memory (after first writing the insert information to the on-disk journal), but it doesn’t yet make the new versions available to other transactions. (The document timestamps are initially set to infinity, which hides the documents from the rest of the system.) At this point the documents are nascent, meaning they have been created but are not yet visible to the system.
During the commit step of the transaction, MarkLogic takes the current time and updates the creation timestamp of the nascent versions (and sets the deletion timestamps for the existing versions) all at once. (Timestamp information is stored in a separate Timestamps file, so the commit can happen in a single operation.) Updating the timestamps during the commit step, instead of as the files change during the transaction, means the transaction is atomic. All the changes happen at once.
Distributed Commits
What if we’re dealing with a distributed database, where documents updated in a transaction live on different hosts? In this case, the commit process gets more complicated. MarkLogic performs a two-phase commit, which allows the hosts participating in the transaction to communicate with each other to ensure all the changes are committed (or, in the case of a failure on any of the hosts, none are).
During a two-phase commit, one of the participating hosts assumes the role of transaction coordinator and writes a distributed begin entry to its on-disk journal. After that, it sends a message to the other hosts asking them to prepare to commit. This is the first phase of the two-phase commit.
During the prepare step, each host writes a prepare entry to its journal, syncs it to disk, and communicates its readiness to participate to the coordinator. If any of the hosts (including the coordinator) cannot participate, the transaction is aborted. Otherwise, it proceeds.
Once the hosts have signaled they are prepared, the coordinator writes a commit to the journal and syncs it to disk. Next, the coordinator communicates the commit to the other participants, who proceed to run their commits as well. This is the second phase of the two-phase commit. Timestamps are updated across all the hosts, similar to what happens in the nondistributed version on a single host.
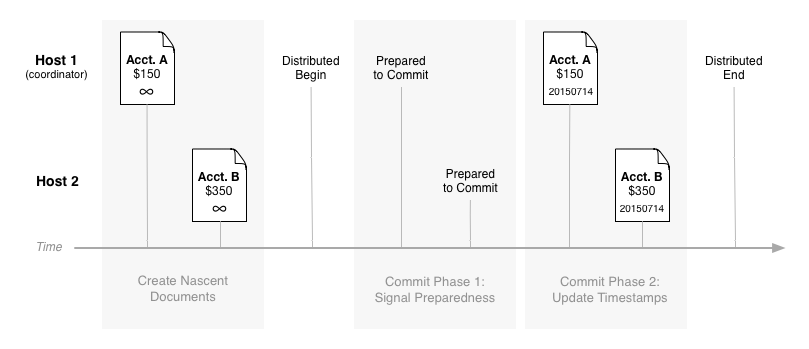
Figure 2: A two-phase commit for a balance transfer in a banking application.
Committing in two phases ensures that a distributed group of hosts only commits if all of the hosts are ready. Without the prepare phase, commits might only happen on a subset of the participating hosts. We’d end up with a transaction that was not atomic and data that was potentially inconsistent.
Conclusion
With these features working on concert, MarkLogic is able to delivery transactions that are atomic, consistent, isolated, and durable—i.e., ACID. MarkLogic applications can read and update data simultaneously (although they may have to wait at times for locks to be released). In-memory data can be recovered after system crashes by replaying on-disk journals. With two-phase commits, applications can perform reliably when accessing documents distributed across many hosts.
For more information about MarkLogic transactions and how they are managed in different languages (XQuery and JavaScript) and through different APIs, see the MarkLogic documentation.
Thanks to Wayne Feick for his help with this article.

