From Unstructured Data to Connected Knowledge

Previously published on Nuclia.com. Nuclia is now Progress Agentic RAG.
Often, questions over a knowledge base require more information than that explicitly present in the documents. For instance, a complex question like
Which lawyers have worked on a case with a senior partner and also specialize in contract law?
Answering this question would require extracting information from multiple sources and reasoning over it. To tackle such challenges, the first step is to structure the data in a way that allows efficient traversal and inference. One effective method to achieve this is by creating a knowledge graph.
A knowledge graph is a set of entities (nodes) connected by relationships (edges) defined over factual information present in a knowledge base. Having this graph enables visualizing and leveraging the connections between the entities present in our information.
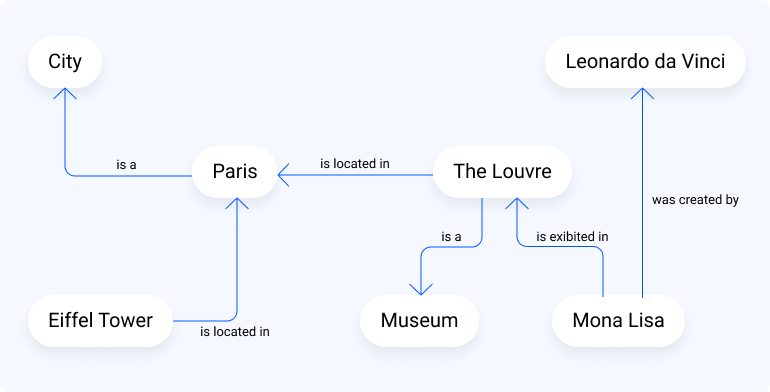
Knowledge Graphs and Data Augmentation Agents
At Progress, we recognize that there is no one-size-fits-all solution to knowledge graphs and that much of their power resides in domain specific entity and relation detection. That is why we have been working on providing a tool to our clients to automate building a knowledge graph tailored to their use case and domain.
We have implemented this feature through our “Data Augmentation Agents”, a framework in which we provide several tasks that run on top of our standard processing and that can also be retroactively applied to existing resources. Clients can enable agents which perform specific tasks that will add additional processing steps to extract the most out of their information.
To define the graph generation task, we require the following information:
- List of desired types of entities to extract, with optional descriptions
- Descriptions are recommended for the entity types that might be ambiguous or might benefit from clarification.
- Only relationships between entity types mentioned here will be extracted
- Specific examples of entity types
- Triplets of text, entity type and text snippet where the entity appears
- At least a couple examples are recommended and do not need to be exhaustive regarding the defined entity types
- Examples of relationships between entities in a text
- Elements with source entity text, target entity text, relationship label and a text snippet where the relationship appears
- At least three examples are recommended, they will help guide the extraction of relationships, so pay special attention to the styling of the relationship label you provide
A Practical Example
To showcase how one would configure the Data Augmentation Agent for graph extraction, we will assume that our knowledge base contains documents from the legal domain.
Using the Nuclia.py Library
To install the nuclia.py library, follow the instructions here: https://docs.rag.progress.cloud/docs/develop/python-sdk/README
Then you must be logged in, you can do that with the CLI command below (more information here https://docs.rag.progress.cloud/docs/develop/python-sdk/auth) :
nuclia auth loginThen, we start by importing the required libraries and accessing our default knowledge base.
from nuclia import sdk
from nuclia_models.worker.tasks import TaskName, ApplyOptions, DataAugmentation
from nuclia_models.worker.proto import (
GraphOperation,
EntityDefinition,
EntityExample,
RelationExample,
LLMConfig,
Filter,
ApplyTo,
Operation,
)
kb = sdk.NucliaKB()Now, we define the required data for this task.
- List of entities: entity_defs
entity_defs = [ EntityDefinition( label="PLAINTIFF", description="The person or entity that initiates a lawsuit", ), EntityDefinition( label="DEFENDANT", description="The person or entity against whom a lawsuit is filed", ), EntityDefinition( label="CONTRACT", description="A legally binding agreement between two or more parties", ), EntityDefinition( label="CLAUSE", description="A specific provision or section of a contract" ), EntityDefinition(label="STATUTE"), EntityDefinition(label="DATE"), EntityDefinition( label="DEFENSE ATTORNEY", description="The lawyer who represents the defendant in a lawsuit", ), EntityDefinition( label="JUDGE", description="The presiding officer in a court of law" ), EntityDefinition( label="PLAINTIFF ATTORNEY", description="The lawyer who represents the plaintiff in a lawsuit", ), EntityDefinition(label="COURT"), ]Here we included the desired entity types with descriptions for some of them. We also included the entity type “DATE” even though it is already extracted by the default processing because we want to capture relationships between our new entity types and DATE.
- Entity examples: entity_examples
entity_examples = [ EntityExample( name="John Doe", label="PLAINTIFF", example="John Doe has filed a lawsuit against ABC Corporation for breach of contract.", ), EntityExample( name="ABC Corporation", label="DEFENDANT", example="John Doe has filed a lawsuit against ABC Corporation for breach of contract.", ), EntityExample( name="Service Agreement", label="CONTRACT", example="The Service Agreement contains a termination clause which allows either party to end the contract with 30 days notice.", ), ]For our entity examples we provide three examples, in two of them we reuse the same text, but with a different extracted entity in each.
- Relationship examples: relation_examples
relation_examples = [ RelationExample( source="John Doe", target="ABC Corporation", label="Plaintiff sues Defendant", example="John Doe has filed a lawsuit against ABC Corporation for breach of contract.", ), RelationExample( source="Service Agreement", target="termination clause", label="Contract contains Clause", example="The Service Agreement contains a termination clause which allows either party to end the contract with 30 days notice.", ), RelationExample( source="Consumer Protection Act 2022", target="Consumer Rights Act 2015", label="Statute amends Previous Statute", example="The Consumer Protection Act 2022 amends the Consumer Rights Act 2015, especially regarding digital goods.", ), ]Lastly, we use our relationship examples to define how we want to structure the relationship labels. Here we are providing examples with a “noun verb noun” pattern, so the extraction will be guided towards that style of relationship labeling.
With these definitions done, we can move forward and start the task, we will enable the task for both existing resources and for any resources we upload from this point onwards with ApplyOptions.ALL, we will select ChatGPT 4o Mini from Open AI as the LLM to perform the task:
graph = GraphOperation( ident="legal-graph-operation", entity_defs=entity_defs, entity_examples=entity_examples, relation_examples=relation_examples, )response = kb.task.start( task_name=TaskName.LLM_GRAPH, apply=ApplyOptions.ALL, parameters=DataAugmentation( name="Generate Legal Graph", on=ApplyTo.FIELD, operations=[Operation(graph=graph)], filter=Filter(contains=[], resource_type=[]), llm=LLMConfig( model="chatgpt4o-mini", provider="openai", ), ), ) print(response)With this, our data augmentation agent will now be active, you can access the task status, stop, resume and delete it with the following commands:
task_id = response.id # Get all tasks task_list = kb.task.list() # Get tasks that are running on existing data running_tasks = kb.task.list().running # Get tasks that are configured to run on uploaded data config_tasks = kb.task.list().configs # Get tasks that are done running on existing data finished_tasks = kb.task.list().done # Check task status response = kb.task.get(task_id=task_id) # Stop a task response = kb.task.stop(task_id=task_id) # Resume a task response = kb.task.restart(task_id=task_id) # Delete a task response = kb.task.delete(task_id=task_id)
For more information on how to use the Nuclia SDK to manage data augmentation agent tasks, please check the Nuclia Python CLI/SDK documentation: https://github.com/nuclia/nuclia.py/blob/main/docs/11-agents.md
Through the Nuclia Dashboard
To create the Graph Extraction Agent, we go to the tab “Agents” on the sidebar and then click on “New Task” in the “Graph Extraction Section.”
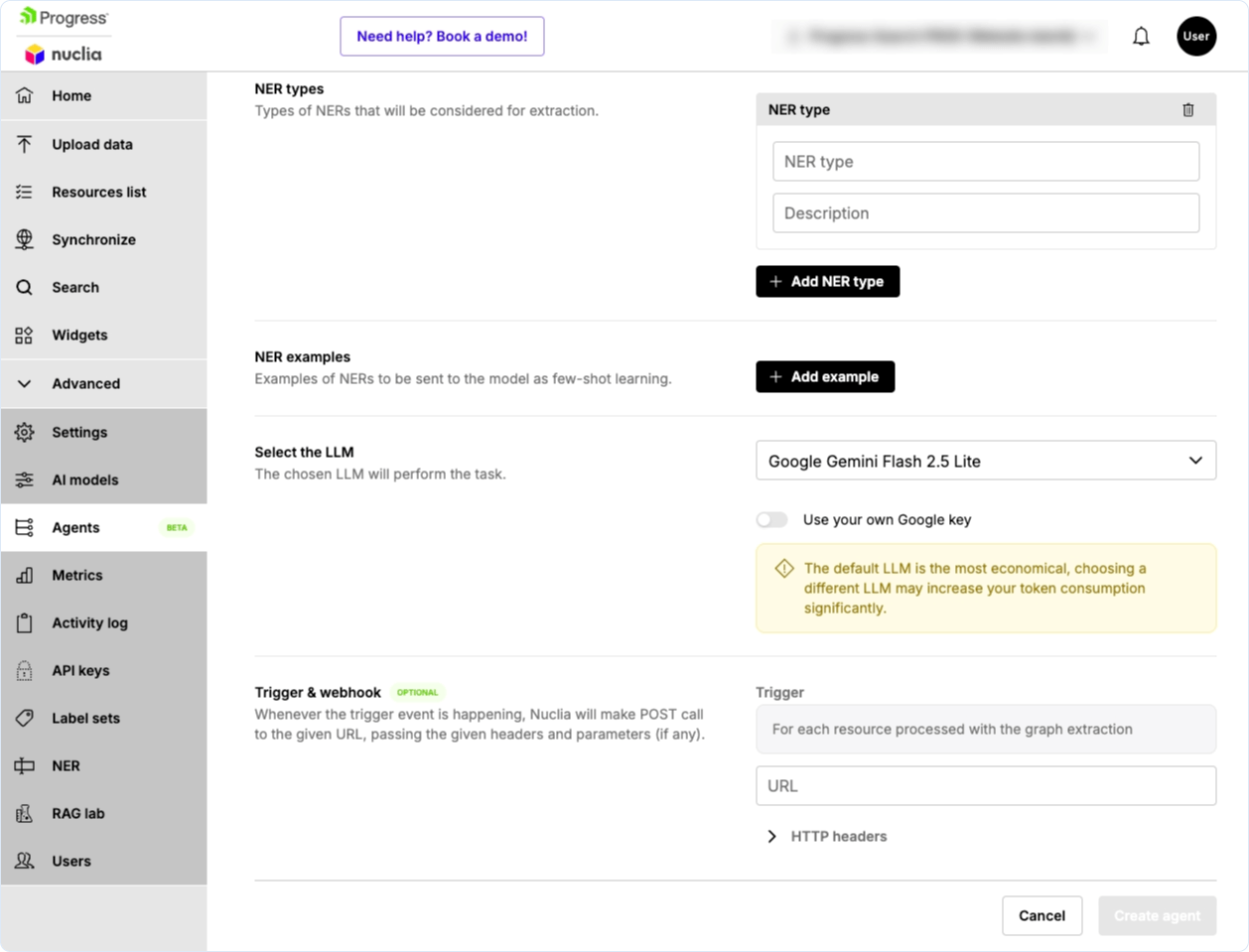
Afterward we fill out the required fields following our desired extraction in the legal domain. We use the same entity definition and examples as in the previous example (not all are shown in the screenshots).
Finally, we select our model, in this case we selected “OpenAI ChatGPT-4o-mini” and click on activate extraction. When our task is created it will appear in the Agents tab.
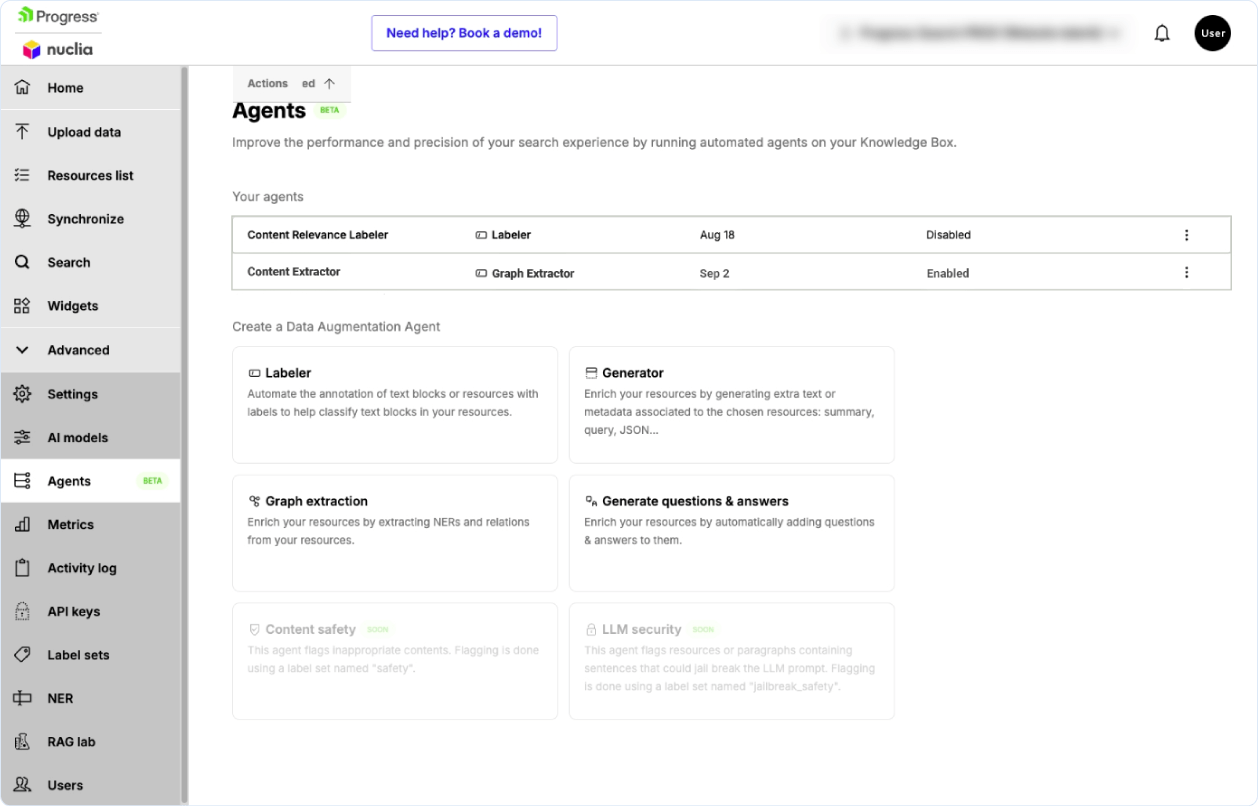
Since we selected the task to be applied on both existing resources and new resources, we have the two tasks listed. The task applied on existing resources will change its status to “Completed” once the existing documents are processed. The task on new resources will show up as “Watching for updates” until we cancel it. To stop or delete a task, we can click the three dots under “Actions” for that specific task.
1 Bourli, S., & Pitoura, E. (2020, December). Bias in knowledge graph embeddings. In 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM) (pp. 6-10). IEEE.
