
Can applying semantics make BCBS 239 reporting consistent and comparable across all financial services’ regulatory bodies? Let’s explore.
When “Best Practice” isn’t good enough… The regulatory vagueries and the punitive fines are making for a tense summer for bank risk officers. On the one hand, regulators are demanding asking for a whole lot of architectural work be done including using standard LEIs, but haven’t been too specific on what all the tasks should be. Lots of hoops – all in motion.
In my previous blog posting I discussed how to go about constructing a risk data architecture that would meet the specifications set by BCBS — now let’s look in detail at how to report on a Risk Data Architecture in a financial services institute so that it can be objectively measured against a peer organization.
Let’s remind ourselves what the BCBS “asks” are:
- A bank should have in place a strong governance framework, risk data architecture and IT infrastructure.
- A bank should establish integrated data taxonomies and architecture across the banking group, which includes information on the characteristics of the data (metadata), as well as use of single identifiers and/or unified naming conventions for data including legal entities, counterparties, customers and accounts.
- A bank’s risk data aggregation capabilities and risk reporting practices should be:-Fully documented and subject to high standards of validation. This validation should be independent and review the bank’s compliance with the Principles in this document. The primary purpose of the independent validation is to ensure that a bank’s risk data aggregation and reporting processes are functioning as intended and are appropriate for the bank’s risk profile. Independent validation activities should be aligned and integrated with the other independent review activities within the bank’s risk management program, and encompass all components of the bank’s risk data aggregation and reporting processes. Common practices suggest that the independent validation of risk data aggregation and risk reporting practices should be conducted using staff with specific IT, data and reporting expertise.Hmm note the use of the term Independent Validation… What is actually happening in practice is that each major institution’s regional banks are lobbying/negotiating with their local/regional regulators to agree on an initial form of compliance – typically as some form of MS Word or PowerPoint presentation to prove that that they have an understanding of their risk data architecture. One organization might write up 100 page tome to show its understanding – and another might write up 10. The “ask” is vague and the interpretation is subjective. Just what is adequate?
Stack the Compliance Odds in Your Favor
XBRL has become the dominant standard for most of the major Regulatory Reporting initiatives – behind each of the dialects is what is known as a “data point model,” i.e. all the key risk and other financial values that comprise the report. What if we could extend XBRL to report BCBS 239 compliance and be able then to compare each of the submissions produced by the banks?
Some ground rules
There are no right answers as to what a risk data architecture should look like – the key thing is to find a way of being able to systematically compare different architectures to find inconsistencies and outliers – this is what the regulators do with the financial content so why not do it with the system architectures?
NOTE: We need to build a model, which of course needs to be anonymous. For public reporting purposes we don’t put any system names in the model, e.g. Murex, Calypso, etc, would be meaningless – nor do we put any technology types in for the interchanges or schedulers e.g. MQ, EMS, Autosys, ControlM, etc.
The Parts: Data Points, Paths, Applications, Interchanges & Schedulers
Instead of a massive PowerPoint or Word document, I propose a comparative logical model that is comprised of 5 key components:
1 | Data Points – A Data Point is what is actually reported as a number based on the intersections/dimensions of an XBRL report, i.e., effectively a cell in a spreadsheet. |
2 | Paths – Each Data Point is created from a Path, i.e., the flow of data via a group of Applications and Interchanges. NOTE: Many Data Points will be generated from a single path – although given the number of data points in a regulatory report we can expect that many different paths will exist across the application estate. |
3 | Applications – An Application is a collection of computers (physical or virtual) that run a group of operational functions in a bank. In reality applications are really financial entities of a set of hardware and software costs grouped together – this is one reason why this model is defined at the logical level, as the groupings are arbitrary within and across banks. NOTE: The same Application and an Interchange may appear in multiple data point paths. |
4 | Interchanges – Multiple data interchanges will exist between applications (even within a path) to produce a data point – these will be message – or batch-based and be related to different topics and formats. As a rule of thumb each data entity/format being moved, any distinct topics used to segregate it, and each transport used to move it, results in a separate interchange being defined. When you start to think about the complexity that this rule of thumb implies you get to the heart of why BCBS 239’s requirement for accurately describing Data Architectures is needed and why moving to a logical approach levels the playing field. |
5 | Schedulers – Applications and Interchanges are both controlled by schedulers. In an ideal world there should be a single master scheduler but in reality multiple schedulers abound in large complex organisations. Identifying the number of places where temporal events are triggered is a major measure of technical + configuration risk and variability in a bank’s risk architecture. As I stated, a single controlling scheduler should be the right thing to do in an ideal world but the lessons of the RBS batch failure are a textbook case of concentration risk in a system design. |
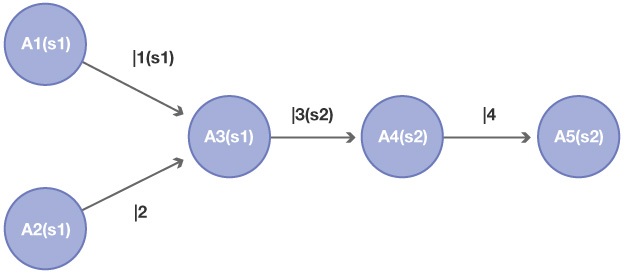
An Example Path: So putting it all together we get a picture like this: (I.E. the path above comprises) 5 Applications, 4 Interchanges – 2 of which are message based, 2 of which are scheduled (FTP etc), 2 Controlling Schedulers
So what does this abstract model achieve?
The abstract model allows us to look objectively at the variability of each bank’s data architecture without getting lost in the often emotive technical weeds of “My approach is better than yours.”
NOTE: There are no “right” answers but there may be some interesting “features” that could occur.
What if some banks reported path lengths of 20 systems to compute a particular Data Point when the average might be say 12. If they had say 20 different scheduling mechanisms for triggering data movements and calculations this should also be a significant concern.
Banks that report say short path lengths of 2 or 3 also would raise concerns. Are they really much more efficient or have they accurately mapped out their data flows/formats/interchange technologies?
Potential extensions to the abstract model
It would be instructive to extend the attributes of Applications, Interchanges and Schedulers to include measures of the rate of change – i.e. both Functional changes and Platform changes – given the need now to support both stress testing and back testing of risk calculations means that regulators need to know that systems are being remediated.
So for each reporting period the dates of the last functional change and platform change should also be reported and the number of functional and platform changes in the reporting period.
Adding Bitemporality to the mix
The need to determine how bitemporally aware each of the systems and interchanges are in a path is also a significant attribute that can be added to this mix. Without this capability backtesting can only be done by building copies of system environments and setting the content and clocks back to the required period.
Normalizing the architecture – adding Dimensionality
If you’ve got this far you now understand that we’ve managed to define a set of abstract logical architectures across the banks that means we can compare scale, complexity and volatility as well as potentially driving statistical convergence to a consistent level of detail.
To the untrained eye the picture above looks like some sort of abstract Maths PhD thesis. There is no easy way for any Banking/Technology subject matter expert to intuitively interpret the results and compare banks objectively in terms of their functional approach/evolution to Risk Data Management/Delivery.
So we need to add some sort of consistent functional classification to the Application list described in the Path specifications.
Any functional model will do – my starter proposal would be BIAN (www.bian.org) as it seems to have some traction in the FS Architecture community. This massive PDF gives a standard set of names for bank services – albeit it’s not an ontology, just a spreadsheet – BIAN really needs to amend this.) So build your abstract model for each Application A1 through “An” and then map each of your applications to BIAN’s services. Currently each bank has its own service model – and can’t be compared. So this is your normalization that adds a form of “geospatial,” if you will.
Footnote: Today each major bank defines its own private Enterprise functional model with the content often mastered in PowerPoint – my previous 2 employers both did this and then transcribed the contents into Planning IT for various technology/systems portfolio reports.
This classification was then used to produced functional system estate maps – aka McKinsey charts that are used by IT management to try and spot duplicative functionality across the application portfolio, however because the charts do not contain the data interchanges between the systems the approach is fundamentally flawed as the true complexity is never shown.
Almost there …
By applying a BIAN (or similar) mapping to the abstract Applications + Interchanges graph we now have a comparable set of functional and data flow based topologies across the set of reporting banks described in Banking “language” rather than abstract algebra. We can now ask questions as to why Bank A has 6 reference data systems vs Bank B who may have 2, or why the number of interchanges between 2 functional domains ranges from 20 in Bank A to 120 in Bank B.
As with the abstract model, adding this form of consistent dimensionality drives reporting convergence; if data lies outside statistical norms then it will naturally provoke curiosity and scrutiny.
Using FIBO as a dimension for Interchanges
FIBO (http://www.omg.org/spec/EDMC-FIBO/) can be applied in similar fashion to BIAN to the set of Interchanges. At the moment however FIBO is incomplete so comparisons will be limited to the foundational entities rather than the high level asset classes. Initially this does not matter as the initial focus of any analysis will be on scale and macro level variability but over time this will need to be completed to allow full data entity flow analysis of a risk system topology.
Using FIBO should also have an interesting side effect – it can be assumed that each standard output Data Point will be comprised of the same FIBO entities for each bank so any discrepancies will be very easy to spot.
So how do I actually add this data to my XBRL-based Regulatory COREP/FINREP etc Submissions?
So this is where the “Semantics” part of the title comes in. We could use triples to visualize this – but it would not be a pretty picture (literally not pretty). Instead I am using triples to compute the associations. We can describe the graph-based path model, the scheduling and temporal attributes of the system as well as the BIAN and FIBO classifications as a set of semantic triples, e.g., A1 has a “ServiceType” of Instrument Reference Data. (for more information on triples)
Conveniently, XBRL is an XML-based reporting syntax so we can just extend the XBRL report content using the industry RDF specifications of triples see :-http://en.wikipedia.org/wiki/Resource_Description_Framework for full details of the syntax and plenty of examples.
Is There Really an Alternative?
Without triples, the agreed “Essay” format of BCBS 239 exam submission (the 100 pages or so) seems to be the norm in the industry. As a taxpayer and shareholder in a number of banks it seems only logical to question how that approach will:
- Build confidence that our political and regulatory masters are being systematic and consistent in their reporting content and metrics?
- Reduce the likelihood of future banking IT failures since it does not deliver continuously improving comparative measurement and analysis?
- Improve the ROI to bank shareholders of their holdings and dividend payouts as it does not provide means to target efficiency improvements in IT systems and supporting institutional knowledge?
It won’t. We are paying people to draw pictures, and we have no idea if it is correct. We have to move into a more grown up world — and take the human element out – we can actually create a comparative scale.
Let’s recap, Summarize … and Comply
Today BCBS 239 is a set of qualitative concepts that the FS Industry is trying to achieve with no comparable, objective measures of success. As a result an inordinate amount of professional services fees are being spent by the major banks to try and achieve compliance coupled with a series of negotiations with regulatory bodies that themselves are not deeply IT literate to agree an initial level of completeness and correctness.
The semantic approach proposed above has the following benefits:
- An extension of existing agreed industry standard reporting formats/syntax
- An objective way of assessing different FS risk management architectures and processes
- Application of standardized terminology to any logical Risk Data architecture Topologies
- A range of statistical measures to benchmark FS Data Architectures and drive convergence/remediations
- Architectural Risk and Volatility measures independent of specific application and technical platform “religious/political” factions
- The reporting process is repeatable with evolutionary measures of volatility, convergence and improvement
- Actually embedding standards such as BIAN and FIBO to solve real world industry problems and drive consistent adoption

