
There are many corporate drivers for the adoption of Master Data Management (MDM). Each business is going to have some mix of the following, with different weighting depending on your needs:
- Revenue increase (CRM effectiveness)
- Cost decrease (process efficiency)
- Regulatory compliance
- Better decision-making
- Improved agility
But the technical challenges — attributable in some part to legacy technologies — make achieving these business goals just out of reach. Many early digital transformation projects failed to deliver some or all of the key features that make an MDM system fit for business innovation and transformation. Features such as:
- How to fit existing data sets in an MDM model
- Agility to evolve data model (golden records)
- Process efficiency in mastering (deduplication) large amount of scattered data
- Handling “large” (millions) amounts of records to master daily… or even in real-time/streamed
- Handling reference data with complex, evolving model
- Data audit, lineage, and provenance at scale
- Operationalize MDM data, make it accessible securely, at speed and scale for all enterprise uses cases
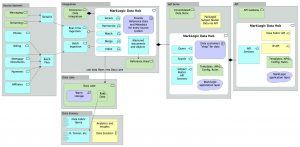
With relational-based MDM, the early phases of a project typically involve modeling the underlying data sources and then creating a single data model which the incoming data sources need to fit into. To make this work, extensive ETL is required to transform data to make it compatible with the central data model. While this is going on, the world is of course changing and the data schemas in the primary systems are evolving – with every change requiring further analysis and work.
There is typically no agreement on how common data items should be stored — so when we try and combine disparate records for the same business entity, we often have to make arduous decisions on which source to select as the most trusted and accurate.
Globalization has led to a variety of additional problems and complications from the data management perspective. This includes multi-lingual and multi-character set issues, and 24×7 data availability needs for global operations.
With so much complexity in a project, any potential system’s interactions with other platforms, the mismatch of data, and the ever-changing needs of the business — it is difficult to know where to start and how to ensure success.
MarkLogic has been solving these problems for our customers for years. Our platform allows organizations to extract value from complex data while ensuring key MDM requirements are met.
The key to the success of these platforms? Start small, stay agile, deliver value, and iterate.
Why MarkLogic?
- Agility is the key to success
- Data is getting more complex, the amount of data is growing, the shapes of that data keeps changing, and the inter-relationship between that data is ever more critical
- The most flexible way to store the inter-relationship between data (how it’s been sourced, modified, the relationship between data) is to use semantics
- Triples provide an incredibly powerful way to flexibly describe the relationship in your data
- MarkLogic has been creating and indexing complex knowledge graphs for businesses and governments for many years
- Data is changing all the time, facts change as new data comes to light. In typical MDM solutions, it’s very hard to unpick the provenance of data if you need to take new actions on it.
- MarkLogic provides full provenance tracking for any changes to the data, even allowing you to unmerge harmonized records if required
- MarkLogic provides ‘lossless’ data management; you can keep the full data record and provenance and action on it as required
- The need for a relational database to pre-define your model (so you can create appropriate columns and tables) means a lot of upfront modeling and difficulty adapting to change.
- MarkLogic’s multi-model document-based approach means you can be incredibly flexible with the data you ingest, how you manage and maintain it, and the way you expose it to other systems
- Increasing amounts of critical data is unstructured, held in systems like emails, chat history, forms, etc.
- MarkLogic ingests, indexes, categorizes, and provides search for hundreds of TBs of unstructured data every day
- Data is nothing without the ability to access it, yet many existing MDM systems focus on the data at the expense of the access
- MarkLogic has a search engine at the heart of our technology. We understand how to index, categorize, and surface the right data at the right time
- With our industry-leading security controls, we also can ensure only the right people see that data at the right time!
- To have a truly accurate 360 view of your entities you may need to include reference data, such as controlled taxonomies, third-party data, etc.
- MarkLogic’s ability to ingest and manage RDF data provides a simple way to ingest, manage, and link to reference data
If you have any questions, please email us at CSM-MarkLogic@progress.com

