
Moving from Relational to MarkLogic
This is the third in a series of blogs for people coming from a relational background, to help you understand the differences in how MarkLogic handles data integration and access.
TL/DR:
- Because MarkLogic easily manages complex, diverse and changing data structures, you can take an iterative, agile development approach versus a waterfall approach—modeling and harmonizing data as needed for each project, versus doing upfront data modeling and ETL. The typical shredding and normalizing work you need to do in SQL-based workflows disappears; instead, you will store data as-is and add metadata to harmonize and enrich the data and make it usable for your applications. This has an added benefit of improving data lineage.
- While MarkLogic can provide SQL views of data, SQL views are only one lens through which data in MarkLogic can be accessed and used.
- Unlike other NoSQL databases, MarkLogic is a true multi-model database—everything operates within a single executable. And, MarkLogic includes a number of features that ensure fast query performance.
- Deduping in the MarkLogic Data Hub Platform is a standard part of data ingestion, handled by the Smart Mastering feature.
My company bought Progress MarkLogic. What am I going to do at work next Monday?”
You’ve been a long-time SQL developer, expert at handling tables, rows, columns, foreign keys and SQL. You have hundreds of reports to create every month, and suddenly you are told that the company has bought MarkLogic.
MarkLogic’s marketing says don’t worry about modeling upfront, just “load as is!” and you’re thinking, “what is this, magic? How in the world can I generate reports and do analysis without typing select commands against tables in predefined and rigid schemas?”
When you go to work next Monday and start building out your new MarkLogic-based system, just what exactly will you be doing?
I know this feeling of uncertainty quite well. I spent two decades in the SQL world before I landed at MarkLogic. I think I had a week to get up to speed before they sent me out on the road. And it was a bit of a shock. I had to let go of many habits and develop new ones. Let me walk you through the differences and show you how it all becomes quite manageable.
Overview – MarkLogic vs. SQL
As you are well aware, SQL databases store data in tables made up of rows and columns that are accessed through SQL select, insert, update, delete and a few other related commands.
MarkLogic is a document database that supports text searches, semantic triples-based queries and geospatial queries, and can handle any form of hierarchical data, among other things.
The document-based structure of MarkLogic is richer and more powerful and expressive than an SQL-based approach. Complex, diverse and changing data structures are much easier to handle with a document-based hierarchical database than with a rigid set of columns and rows.
Design Differences
With SQL, development is forced into a waterfall approach. This is because before data can be accessed, it must be modeled, and ETL must be performed to make the data fit into the data model. As discussed in “Using a Metadata Repository to Improve MDM Success,” this often means that there is a long time (sometimes years) between when a project starts and when the first benefits of the project begin to appear.
MarkLogic suggests a highly iterative development approach instead. Because data can be loaded and accessed as is without any processing, deliverables can be defined and implemented with only the processing and data transform needed to implement that deliverable.
Another difference is that in large-scale relational systems, tasks like modeling, data ingestion and access, and master data management are often done by separate groups with different technologies and possibly having limited involvement with each other. MarkLogic’s richer and more flexible technology makes it desirable for all of these functions to be handled on the same platform in an integrated fashion.
Handling Source Data
With the above in mind, the first change in your workflow will be handling incoming data. Most of the data you get is more naturally hierarchical rather than relational. Instead, you may be getting complex XML in the form of FpML or FIX trades, JSON-based market data or object-based output from Java or .NET applications. In an SQL-based workflow, this complex data needs to be shredded through an ETL process so that each file or object can be stored in a normalized form in a number of separate tables.
With MarkLogic, much of this work will disappear. Instead, as will be discussed later, you store the data as-is with no or minimal changes and add metadata to make the data fully usable.
There are two main reasons for storing the data as is:
- Users can gain benefits from the data, such as full-text search, before any transformations or processing is done on the data, so waiting to build out an ETL process will delay the time before users gain benefit from the data.
- In an ever-increasing emphasis today on data lineage, storing the data as you receive it makes it much easier to understand how it is transformed before it gets to the ultimate end-user.
Entities and Relationships
Data is often related to other data, and indeed they can be related in a variety of ways. In relational terms, there may be a many-to-many relationship between records or a one-to-many relationship. One-to-many relationships may be parent-child relationships where the child must have exactly one parent, or they may be more general where a child may have no parent or a one-to-many relationship with several different parents for different relationships.
With relational systems, these different types of relationships are handled the same way: Normalize the data into tables, and use foreign keys to link the tables together. In some cases, this is a great approach. What it means, however, is a lot of work pulling together multiple tables to create a single representation of the data.
SQL – a Vanilla Finance Swap
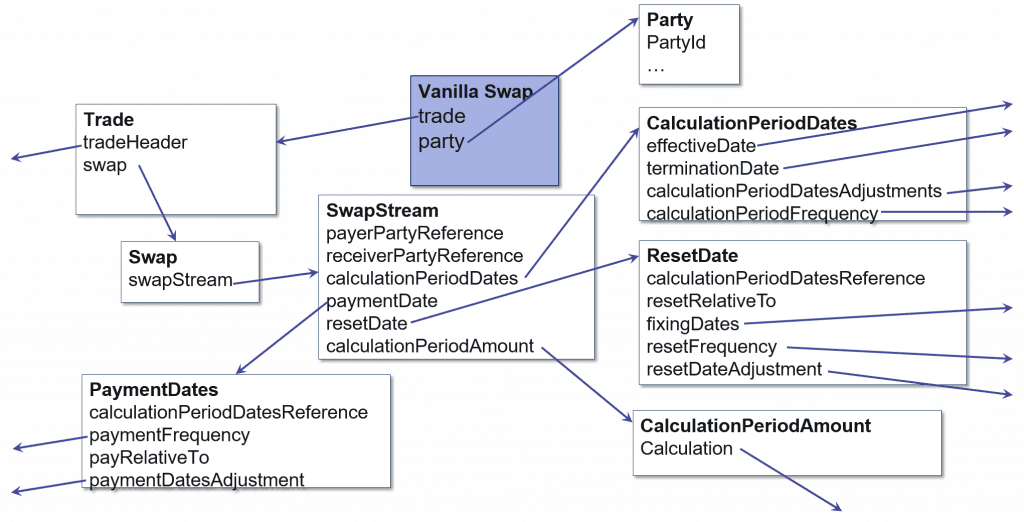
For example, the above swap might easily require a dozen tables in a relational system. Therefore, storing or pulling together a single swap can require a dozen disk IOs. If your application generally requires accessing swaps, as a whole, it would be much more efficient to store the swap as a single unit.
MarkLogic – a Vanilla Finance Swap

Going forward, less of your time will be spent doing low-level modeling of data structures. You will do the modeling needed to secure, query and allow your users to access the data, but it will not be necessary for the database engine to formally model every attribute of every data source.
Getting Going on MarkLogic
Now that we have set the background, let’s look at some of the MarkLogic functionality you will be using to build the reports and provide the other kinds of data access your end-users require. This list is not comprehensive, but it should provide an idea of the kinds of things you will be doing on a day-to-day basis. Specifically, we will look at:
- SQL
- Data Modeling
- Search and Query Languages
- Collections
- Directories
- Hierarchical Data Models
- Semantics/Triples
- Fields
- Deduping
SQL – MarkLogic can expose selected data attributes using SQL through its ODBC driver. The technology for doing this is called Template Driven Extraction (TDE). TDE is done by creating a template that describes regularities in the data and how they should be mapped to SQL views. Since it is likely that a large percentage of a firm’s users expect to receive data in a relational format, the ability to expose complex data as SQL views can be a critical component of a MarkLogic-based solution.
It is important to keep in mind that SQL is more limited than NoSQL/multi-model. MarkLogic’s support for more varied and complex data structures makes it possible to build data stores that are more performant and easier to maintain than is possible in a relational environment. SQL views of the richer data structures are one lens through which the data can be accessed and viewed.
Data Modeling – There are fundamental differences in data modeling in relational systems vs. MarkLogic. The most important is that data modeling in relational uses a waterfall approach where every column in a table must be defined before data can be loaded. In MarkLogic, data can be loaded and accessed without any modeling, and when modeling occurs, it is incremental with models built gradually according to business needs.
Another difference is that in relational, complex objects must be decomposed in a potentially large number of tables. In MarkLogic, complex, hierarchical data structures are supported allowing data to be stored in the way domain specialists think about it. For more information on this topic, see part 2 of this series (Data Modeling: From Relational to MarkLogic).
Search and Query Languages – With MarkLogic, data exposed as an SQL view can be queried with the SQL “Select” command. This is far from the only approach to data access. MarkLogic supports text-based searches as well as geospatial and structured queries along with SPARQL searches of semantic data. One of the great differentiators of MarkLogic is that text search, query and SPARQL searches can all be performed as a single integrated whole, and an individual data record can store the different types of data together. Unlike most NoSQL databases, MarkLogic is a true multi-model database. Everything operates within a single executable. Other products tend to be based on one model and then bolted-on separate products to handle other use cases. This approach limits how tightly different data access models can be integrated.
The thought of having to use non-SQL query languages to fully access the power of MarkLogic may be disconcerting. Before deciding on the exact approach(es) to follow in providing data to your users, it is important to understand that while your end-users expect data to be delivered to them in an SQL-friendly manner, for many of them, they receive data this way because that is the only way it has ever been offered.
In many cases, end-users actually need object-oriented or hierarchical data and need to perform transforms on the data from SQL-based systems to meet their requirements. This is often done through approaches like JPA that can require extensive effort and can be difficult to maintain. With MarkLogic, data can be stored in a way that is highly compatible with object-oriented languages like Java or .NET. In fact, environments like Java and .NET have the ability to serialize XML and JSON into objects (or deserialize objects into XML or JSON) with a single command that is much more lightweight and easier to maintain than JPA.
For users who really do want data in the form of rows and columns, the output of XQuery and JavaScript routines can be delivered in flat formats like csv and made accessible in ways that are highly compatible with their current workflows.
Going forward you will be spending time determining the optimal approach to providing data to your end-users and offering them a broader and more useful array of data delivery options than they currently have.
Collections – One of the reasons business intelligence (BI) tools are able to provide users with fast answers even when working with large data sets is that sometimes they pre-calculate answers to common queries. When BI tools do this it can have a negative side effect of slowing processing down so much that real-time access must be abandoned and data loaded in batches.
An important capability MarkLogic provides to speed many queries is “collections.” When a document is inserted – or at any time afterward – it can be associated with zero or more collections. The criteria for determining if a document belongs in a given collection can be as complex as needed. Assigning a document to a collection at ingest instead of at query time enables queries involving collections to run very fast – MarkLogic maintains a list of all the URIs (uniform resource identifiers) of the documents that belong to the collection and so queries of the form collection = ? are precomputed and take virtually no time to run.
MarkLogic can maintain as many collections as is helpful to your users. Although new collections can be defined at any time, using collections is a design-time capability in the sense that when a new collection is defined it is necessary to scan existing documents to determine if they should be added to it.
Determining what collections can improve your user’s query performance should be a part of your regular ongoing workflow and is a critical aspect of well-designed MarkLogic systems.
Directories – A benefit similar in some ways to collections is directories. With SQL databases, record IDs are usually integers that grow over time. The reason for this is, with a relational database, if you regularly insert records into the middle of a table, you will quickly run out of space, and block-splitting will occur, which is bad for performance. MarkLogic works quite a bit differently than traditional databases. Data is constantly moved between machines, and block sizes are larger. Therefore, block splitting is much less of an issue.
As a result, with MarkLogic, you are not limited to using meaningless integers as document identifiers and have the option to use identifiers that can make your users’ lives easier. Specifically, MarkLogic URIs can be based on directories similar to those found in file systems. In many cases, users can find the documents they are looking for without the need to evaluate all of the documents in the system. For example, if you are looking for an ‘FX Option’ trade done with ‘CounterPartyA’, you may have a naming convention. Therefore, the trade is stored as Trades/FXOption/CounterPartyA/Trade20160901.json.
If you know you are looking for ‘FX Option’ trades with ‘CounterPartyA’, with MarkLogic, you can just go to the appropriate directory and scan through the limited set of documents located there instead of searching through the entire database. Not all queries will be able to take advantage of a document’s directory structure, but those that do can be made to run many times faster.
Collections can often provide the kind of benefit provided by directories with potentially more flexibility (a document can belong to multiple collections but only one directory). Collections can also scale better than directories in some cases. You will want to analyze your access needs to determine if the benefits of directories make it worth implementing. This is one item you will want to work on before you begin doing your initial data loads into MarkLogic as file names cannot be changed after ingest.
Hierarchical Data Models/Denormalizing Data – A key aspect to MarkLogic is that it is, among other things, a hierarchical database that can handle complex data in a single document. When data is stored hierarchically, the need for SQL-style joins (a major performance killer) can be greatly reduced. As discussed above, much of the data coming into your organization already is hierarchical and your SQL-based approach shreds the data to force it into columns and rows. In many cases, you will just be able to take the incoming data as is and, initially at least, just store it.
In other cases, to make data easier to understand and improve query performance, you will want to “denormalize” the data. It is important to understand that in a MarkLogic context, “denormalize” means something very different than it does in the relational world. In the relational world, denormalizing data means duplicating data so that queries can be resolved more efficiently. In general, this is a negative because data integrity suffers when more than one data element is logically required to be the same.
With MarkLogic, denormalizing data means pulling child data into the parent’s document, which eliminates duplication of data and improves data integrity. Storing children with their parents not only makes the data easier to understand, it eliminates the possibility of “orphans” (children without parents), which should not occur in relational systems (however, it often does).
To optimize performance and make data easier to understand and maintain, you will be spending time determining which data should be stored in a hierarchical fashion and sometimes pulling this data together.
Deduping – Most MarkLogic projects involve bringing together independently created but often overlapping data sets. In this kind of situation, the same individuals or entities will often appear in different data sets with different identifiers in slightly different ways, such as names spelled differently, different addresses, etc. In relational systems, eliminating duplicate entries and determining the master view of a person’s or entity’s information is handled outside of the database by a different group. In the MarkLogic Data Hub platform, deduping is considered to be a standard part of data ingestion and can easily be included whenever data needs to be harmonized. The specific technology in the Data Hub that does deduping is called “Smart Mastering.”
Deduping needs vary from application to application. In some cases, only a best effort is required. In others, incorrectly linking two records can have a major cost. The amount of effort put into deduping needs to reflect this. Is human review of each potential match required? When it is not clear if there is a match, how much time should be spent on review? There is no one best answer to these and other questions.
Semantics / Triples – The closest direct replacement MarkLogic has for relational foreign keys is semantic triples. Triples are far more powerful than foreign keys but can provide foreign key-like functionality. Triples can be used to connect documents and apply meaning to relationships.
At a high level, triples are subject/predicate/object relations that can look like:
<Swap><isA><FinancialInstrument> .
<DerivativesSwap><isA><Derivative> .
<DerivativesSwap><isA><Swap> .
<Trade1><isA>< DerivativesSwap > .
<Trade1><hasACouponPayment><PaymentA> .
<PaymentA><hasAPaymentDate><2016-04-05> .
<Trade1><hasCounterParty><CompanyA> .
<CompanyA><hasARiskRating></risk/companyARating> .The subjects and objects in the triples can, but need not, refer to documents in the database, and when they do, they can act as a foreign key. With the SPARQL language, SQL Select-like functionality can be performed to join data in separate documents. Generating this kind of triples is generally not difficult as the information already resides in the foreign keys of the legacy data.
Going beyond simple foreign key replacement, for conducting relational style queries, triples and semantics are often used to build out synonym lists and hierarchies. For example, if different data sets refer to the same financial instrument with different identifiers, you can create triples to show that all of these variants actually refer to the same thing, and search on all the terms together. A key point of using triples for synonyms (unlike fields that are discussed below) is that the relationships are defined at run time and not design time, so relationships can continually evolve and be added.
With hierarchies, you can slice and dice information as you please. For example, if you define a hierarchy like the above with FinanicalInstrument->Swap->DerivativesSwap, you can index documents with the narrowest term (here ‘derivatives swap’) and query on any of its broader terms.
A key feature of MarkLogic is that semantic queries against triples can be integrated with searches and queries against other types of data. For example, the results of a SPARQL query can be filtered against a date range stored as XML in your underlying documents.
An important part of your job going forward will be to create triples to define relationships between data in your database. Much of this will be repurposing the information used in your legacy foreign keys. But to fully exploit MarkLogic’s capabilities, you will want to review your data to find more triples.
Fields – If the same attribute is defined differently in different data sources, say customer_id, in one document and custID in another, you can create fields to link the different attribute names into a single global identifier. It is common to also associate the field with an in-memory range index to make queries against the field run fast.
Unlike using triples to define synonyms, fields are a design-time tool, and their use should be limited to extremely important data attributes.
In the future, you will be spending some time analyzing your data to determine which data attributes should be treated as a single unit with either fields or triples.
Pulling It All Together
Now that you have a flavor of the low-level workflow you will be doing with MarkLogic, how do you pull it together? With MarkLogic, the general design approach is to load data close to as is and then use the envelope pattern to make the data generally accessible to users.
It is important to note that, unlike relational systems that can require extensive data modeling and ETL to be useful, as soon as data is loaded, a great deal of value can be gained from it. With Progress MarkLogic’s Universal Index, as soon as data is loaded, it immediately becomes available for search and query. Google-like searches can be conducted without the database administrators understanding what the data is. Any user who understands what’s in the data can query against descriptors in the data (XML and JSON attributes and csv field descriptors). A substantial percentage of use cases can be largely handled by this functionality alone.
To move beyond this base functionality and allow MarkLogic to fully exploit its capabilities, customers generally use the envelope pattern where data is stored as-is along with metadata to harmonize and enrich the original content. Primary drivers behind the load data as is framework are:
- Data can be used and accessed as discussed above while the metadata is built.
- The increasing requirement to provide data lineage.
In relational systems, data sometimes goes through multiple ETL steps before it is provided to end-users. If a question arises on the provenance of a given data value, it can be difficult to determine if that value was part of the original source data or if it came out of one of the ETL steps.
By loading data as is and then storing the transformed and enriched metadata with the original data, it becomes much easier to track data lineage.
Combining Multiple Data Sets into a Single, Consolidated Whole with the Envelope Pattern
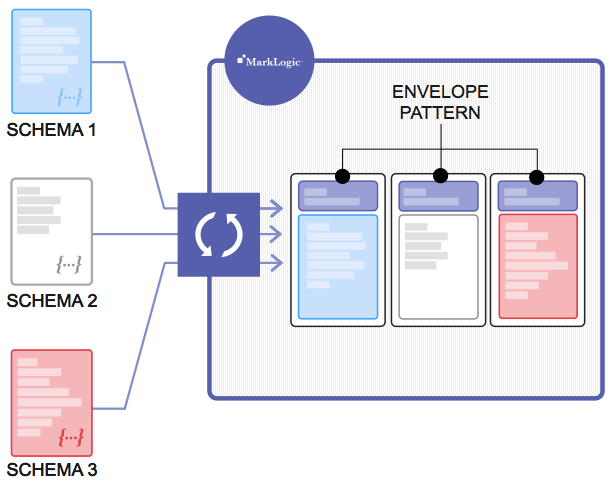
Data stored in the metadata portion of the envelope can include items like normalization of units (some original data comes in millions, others thousands) and identifiers as well as other transformations and enrichment to the data.
As metadata is defined, users can query on a combination of the original data and the canonical and enriched metadata to obtain a consistent and enhanced view of the data.
A Harmonized Record
<envelope xmlns="http://marklogic.com/entity-services">
<headers>
<sm:sources xmlns:sm="http://marklogic.com/smart-mastering"> … </sm:sources>
</headers>
<triples />
<instance>
<MDM xmlns="">
<Person>
<PersonType>
<PersonName> … </PersonName>
<id>208</id> <Address>
<AddressType>
<LocationState>MD</LocationState> …
</AddressType>
</Address>
<PersonSSNIdentification>
<PersonSSNIdentificationType>
<IdentificationID>73777777</IdentificationID>
</PersonSSNIdentificationType>
</PersonSSNIdentification>
</PersonType>
</Person>
</MDM>
</instance>
<attachments />
</envelope>As an example of the envelope pattern, suppose that the original data for a bond simply gave its full-text issue name and coupon. To make this more useful to your users, you might want to provide the normalized identifier of the bond issuer (AAPL) and enrich the data with the bond’s Moody’s Rating.
After this is done, the document for the bond is much more accessible and useful for your end-users.
Going back to the MarkLogic design philosophy, in general, you should focus your envelope pattern efforts in an iterative, deliverable-focused manner. It is not necessary to fully build out a document’s metadata for it to be useful. You should focus on the metadata needed for your next deliverable.
After you have your data loaded and have delivered your first deliverables, building out the metadata needed to make your documents uniformly accessible and as useful as possible will take a substantial amount of your time.
Summary
MarkLogic allows you to take diverse, complicated data silos and begin gaining value from them with minimal effort. Gaining more value does require work and effort, but this work can be done in an incremental effort with each development sprint focused on just the tasks needed to complete a limited set of deliverables. As each sprint is completed, its results can be made available to all users of the data, and the resulting database becomes the starting point for future development.
In some ways, the work is similar to what is done in relational-based systems, and in some ways, it is different. In general, projects can be delivered and maintained with significantly less overall effort than has been possible with yesterday’s technologies.
Learn More
- Read the other posts in this series:
- [Blog] What ‘Load As Is’ Really Means Explanation of the Load As Is pattern, how you can validate and transform JSON and XML, and how it works to speed up development.
- [eBook] Building on Multi-Model Databases (O’Reilly)
- Download MarkLogic software

