
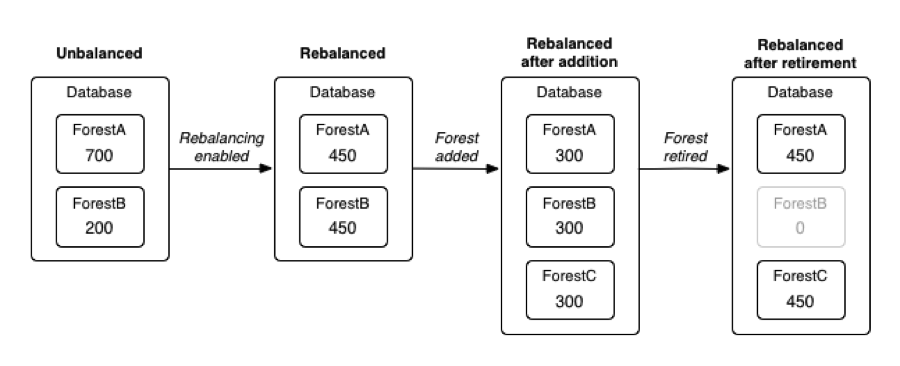
Rebalancing in MarkLogic redistributes content in a database so that the forests that make up the database each have a similar number of documents. Spreading documents evenly across forests lets you take better advantage of concurrency among hosts. A database with most of its documents in one forest will do most of the work on that forest’s host, whereas redistributing the documents will spread the work more evenly across all the hosts. In effect, rebalancing results in more efficient use of hardware and improved cluster performance. The rebalancing feature was introduced in MarkLogic version 7 and can be turned on and off via the APIs as well as through the Admin UI. You can control how aggressively rebalancing occurs by setting a throttle value. Before version 7, users adding or removing forests from a cluster had to rebalance a database by writing custom code in the application layer.
Rebalancing is triggered by any reconfiguration of a database, including the adding of new or retiring of existing forests. If you plan to detach and delete a forest, you’ll want to retire it first to ensure that any content in that forest first gets redistributed among the remaining forests. If you don’t retire a forest and just detach and delete it, any content on that deleted forest is lost.
Assignment Policies
Rebalancing works based on an assignment policy, which is a set of rules that determine what document goes to what forest. A database’s assignment policy applies to rebalancing as well as how documents are distributed to forests in the first place during ingest.
An assignment policy is a way to, in NoSQL parlance, shard a database. Sharding means distributing data horizontally across multiple hosts to achieve better performance. This is what MarkLogic is doing when it allocates documents in a database across multiple forests, and those forests exist on different hosts. But even if you’re running MarkLogic on a single host, spreading documents across more than one forest can improve performance by taking advantage of parallel processing on a host’s multiple cores. For more information about choosing the optimal number of forests, see Forest Sizes per Data Node Host.
There are four assignment policies: bucket, legacy, statistical, and range. The bucket policy (the default) uses an algorithm to map a document’s URI to one of 16K “buckets,” with each bucket being associated with a forest. (A table mapping buckets to forests is stored in memory for fast assignment.) Employing a large number of buckets—typically many more than the number of forests in a cluster—helps keep the amount of content transferred during redistribution to a minimum. [1]
The legacy policy also distributes documents based on their URIs and uses the same algorithm that older MarkLogic releases used when assigning documents during ingestion. The legacy policy is less efficient since it moves more content than the bucket policy, but it is included for backward compatibility. The bucket and legacy policies are deterministic, since a document will always end up in the same place given the same set of forests.
The statistical policy assigns documents to the forest that currently has the least number of documents of all the forests in the database. This strategy requires forests to know the number of documents in the other forests across the cluster. This information is included in the cluster heartbeat, which is the message that hosts in a cluster periodically send to one another. The statistical policy requires even less content to be moved compared with the bucket policy but at a cost of extra information in the heartbeat. The statistical policy is non-deterministic since where a document ends up will be based on the content distribution in the forests at a given time. For this reason, the statistical policy can only be used with strict locking.
The range policy is used in connection with Tiered Storage and assigns documents based on a range index. This means that documents in a database can be distributed based on their creation or update timestamp. This allows recent documents that are more frequently accessed to be stored on faster solid-state media and older documents to be stored on slower disk-based media. With the range policy, there will typically be multiple forests within each range; documents are assigned to forests within a range based on the algorithm that is used with the statistical policy (which makes the range policy non-deterministic).
| Policy | Strategy | Scaling Efficiency | Deterministic |
|---|---|---|---|
| Bucket | Map the document URI to a bucket and the bucket to a forest. | Good | Yes |
| Legacy | Map the document URI to a forest. | Fair | Yes |
| Statistical | Which forest has the fewest documents? Put the document there. | Very Good | No |
| Range | Map the document to a forest based on a range value in the document (e.g., a creation or last-updated date). | Good | No |
Moving the Data
Behind the scenes, rebalancing involves steps that are similar to how you move documents between forests programmatically. During a rebalancing event, documents are deleted from an existing forest and then inserted into a new forest, with both steps happening in a single transaction to maintain database consistency.
For greater efficiency, the documents are transferred not one at a time but in batches, with the sizes of the batches varying with the assignment policy (and how resource-intensive the policy’s operations are). Furthermore, for the statistical policy, a difference threshold needs to be reached among the forests to trigger rebalancing, which keeps rebalancing from occurring unnecessarily when there is a small difference in forest counts. [2]
Footnotes
[1] Suppose there are M buckets and M is sufficiently large. Also suppose a new forest is added into a database that already has N forests. To again get to a balanced state, the bucket policy requires the movement of N x (M/N – M/(N+1)) x 1/M = 1/(N+1) of the data. This is almost ideal. However, the larger the value of M is, the more costly the management of the mapping (from bucket to forest) is.
[2] Suppose the average fragment count of the forests is AVG and the number of forests is N. A threshold is calculated as max(AVG/(20*N), 10000). So, data is moved between forests A and B only when A’s fragment count is greater than AVG + threshold and B’s fragment count is smaller than AVG – threshold.
Thanks to Haitao Wu for his help with this article.

