Bulk Loading Oracle without SQL*Loader | Part 1 – Extracting the data from DB2

In this post, we’ll focus on the extraction of the data from the DB2 system. You’ll learn how to configure your machine to easily extract data from DB2 on z/OS in preparation for a bulk load without running any command-line utilities or writing any SQL!
Requirements: A current Windows machine, either 32-bit or 64-bit. I’ll actually be using a Windows 7, 64-bit Ultimate configuration, running under VMWare Fusion on my Macbook Pro. (Instructions for configuring VMWare Fusion and Windows 7 are available at the VMWare Fusion Blog. Runs VERY well, by the way!)
Go to http://www.datadirect.com/products/odbc/index.ssp to download and install the appropriate version of Connect for ODBC.
Here’s what your ODBC Administrator Control Panel should look like after the installation. If you already had drivers installed, you may see additional entries. Not a problem.
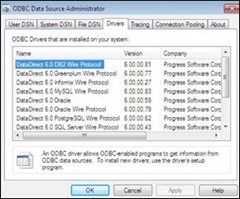
Not a Microsoft Windows fan? You can also do this via our ODBC drivers for Red Hat or SUSE Linux, available from the same web address. We provide an optional GUI administrator on those platforms that allows the exact same operations as shown here on Windows.
Your source is your operational data in DB2 on the mainframe. Note that the Progress DataDirect DB2 drivers connect to DB2 on the mainframe WITHOUT any intermediate tier, such as DB2 Connect or any client libraries. It’s very similar to a Type 4 JDBC driver. A self-contained driver that connects to the server by IBM’s DRDA protocol. So a connection will be established directly from the Windows machine to the mainframe.
Back to the setup – Select the DB2 driver to configure a new data source.
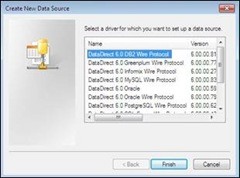
Someone knowledgeable about ODBC may recognize that this is not your father’s ODBC driver for DB2! Many more options and choices. But the fundamentals should be familiar. The IP address, the port that the database is listening on, etc. You must specify the info that is needed to adequately identity the DB2 system that you want to connect to and subsequently extract the data from.
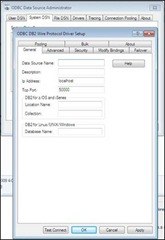
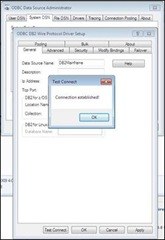
Fill in the relevant info, and hit the “Test Connect” button (not a real requirement, but it provides immediate feedback that our configuration is correct). This will bring up a login panel that will attempt to connect to the database as defined, with your User ID and Password.
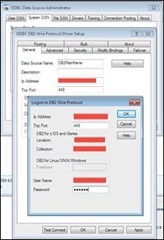
Success! If all of the configuration info and credentials were in order, you should see the following. So you know that you can successfully sign into your source database.
You’ve probably noticed that there are a variety of tabs in the setup pane. These aid in the configuration of the various features available with the driver. You want to configure the “Bulk” feature.
Clicking on the “Bulk” tab changes the Setup pane to configure one of our newest enhancements. Bulk support is a feature newly implemented in this most recent release.
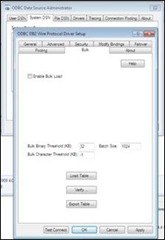
The “Enable Bulk Load” checkbox is prominent in this pane. What does it do? It allows an ODBC application that is coded using parameter array batch inserts to use the database’s bulk protocol WITHOUT RECODING. But that’s not what this problem calls for. The checkbox has no effect in this particular problem.
To transfer data from one database to another via the ODBC driver, you are more interested in the three buttons in the lower half of the pane – “Load Table…”, “Verify…”, and “Export Table…”
Specify the table where your data resides by using the “Export Table…” button. (You would repeat this operation for each DB2 table with data you need to move into Oracle.)
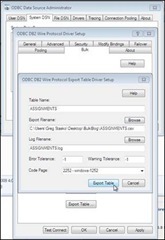
You want to copy data from the ASSIGNMENTS table in DB2 over to Oracle. The table name needs to be directly entered; there is currently no way from this dialog to browse the database to determine the desired table. Sounds like a good enhancement for a future update!
You are going to specify the location of a file to store the DB2 data in a .csv format. A .xml file will also be created, describing the data types present in the table. The driver will also create a .log file, detailing the results of the operation.
Now, “Export Table”! You are prompted for your DB2 login credentials.
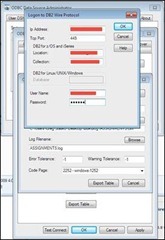
If there are no hiccups, you should see that the export was successful!
Visit the file system location (in my case, the BulkBlog folder) that you specified earlier in the “Export Table…” pane, and you’ll see the three files. The .csv file which contains the data, a .xml file which contains the metadata about the data types in the .csv file, and the .log file, which details what happened during the export.
The ASSIGNMENTS.csv file is just a .csv file, nothing unique. It can be opened in any application that supports .csv file formats. Here, it’s viewed with the Windows 7 version of WordPad. No surprises.
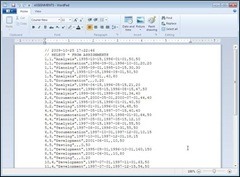
Similarly, the ASSIGNMENTS.xml file can be viewed by any application that can open well-formed XML. Internet Explorer 8 will serve in this case! The different column names and their associated data types are detailed here.
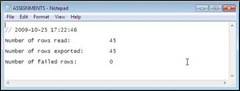
Lastly, the ASSIGMENTS.log file. Notepad works fine! This was a rather simple operation, not really a large amount of data, by any means. The most important things to note – The number of rows read matches the number exported. No errors, so no failed rows!
SUMMARY ======= Your DB2 data is ready to be loaded into Oracle. Note that the extraction process is entirely independent of the target. What you’ve done so far has involved NOTHING specific to the target database. This data could just as easily be destined for SQL Server or Sybase or even another DB2 system. The extraction phase is completely distinct from the load phase.
In part 2, you’ll learn how to load this data into Oracle in a few simple steps, with nothing more than an ODBC driver!
