
MuleSoft provides a leading Integration Platform as a Service (iPaaS) to manage APIs. MarkLogic provides a leading Data Hub Platform to integrate and manage data. With MuleSoft and MarkLogic together, organizations get more value out of their data quicker than ever with a unified 360 view of their APIs and their data.
In this Part 1 of a 2-part blog series, we provide an overview of MarkLogic and MuleSoft, the benefits of using both together, and a walkthrough using a shopping application to illustrate how they work together.
Overview
MuleSoft and MarkLogic work together to bring customers unique integration capabilities not available anywhere else.
MuleSoft is a leader in ESB-driven data integration and API-led connectivity. They have connectors available so that practically any set of systems can be stitched into a data movement workflow.
As an API management tool, MuleSoft offers a multitude of tools to define, secure, manage, and deploy REST-driven applications. As an integration tool, MuleSoft offers a standard message-oriented approach to data movement and is designed to work with data where it resides.
MarkLogic Data Hub is a leading multi-model data platform used for enterprise data integration and management. MarkLogic Data Hub integrates, curates, and stores enterprise data and powers both transactional and analytical applications. MarkLogic Data Hub is powered by MarkLogic Server, providing multi-model data management, ACID transactions, and enterprise data security.
By integrating both platforms together, you’re able to connect all of your applications with MuleSoft and also move your data into a single integration point in MarkLogic that is scalable, transactional, and secure.
The MuleSoft Way
Let’s start by discussing the value that MuleSoft brings. In a pre-MuleSoft scenario we have multiple point-to-point integrations to get data from the various source systems. This results in spaghetti code as seen in Figure 1. MuleSoft uses API-led connectivity and its ESB message model to standardize and enable re-use, minimizing the need for point-to-point integrations. With MuleSoft, as seen in Figure 2, we now have orderly, re-usable APIs that can be leveraged for accessing many systems, and the message inputs and outputs on system-specific operations are standardized.
Source data in the systems of record stay in place and requests to the API calls utilize transformations to the source systems to pull together the data needed. The expectation is that both the data structures and security models are heterogeneous across the various platforms.
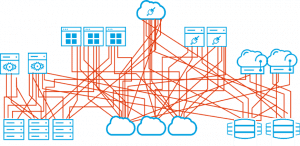
Figure 1: Point-to-point integration “spaghetti” coding. Source:https://blogs.mulesoft.com/dev/api-dev/what-is-api-led-connectivity/
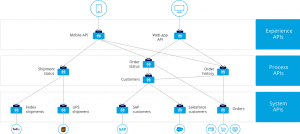
Figure 2: API-led connectivity, showing key API layers. Source: ibid.
The MuleSoft API-led connectivity approach allows users to create, secure, manage, and deploy APIs that invoke and interact with Mule application workflows.
MuleSoft places distinctions on both “experience” and “process” REST APIs. Experience APIs represent the end-user API layer, which interfaces with process APIs. Process APIs interoperate with source systems via “system” APIs, which are usually out-of-the-box, source system-specific APIs. These REST API layers form a network that can be designed right inside of MuleSoft, using open API definition standards like OpenAPI Specification and RAML. The REST API layer also represents where security (authentication and authorization) will be applied and evaluated for data operations throughout the stack. MuleSoft offers a vast array of tools and protocol support for protecting APIs and access to data in motion between these layers.
End users typically interact with the experience APIs. Depending on the task users are performing (or the data view they are requesting), one or more underlying process APIs may be invoked. These APIs are backed by Mule flows, which layout a workflow of operations, comprising a number of processes and/or transformations. Such processes commonly leverage system APIs via workflow operations to work directly against the source systems.
Example MuleSoft Implementation
Imagine business analysts that need to analyze customer order data.
The analyst will first hit the MuleSoft experience API, which consumes from various process APIs. Those process APIs are backed by flows whose operations retrieve data from the SAP, Salesforce, and Orders source system APIs. As the raw data is pulled from these three source systems, operations within the flow can transform heterogeneous data into one or more serializations necessary for satisfying the response format of the REST request.
This flow of data retrievals will repeat itself over and over, for each request, by each user. From the REST API perspective, it’s important to note that the source system of record security and data models are left in situ. In other words, transformed data does not get further persisted.
The REST API security layer defines access controls for downstream consumption from the various source systems, as its flows are transforming and munging data for API responses.
MuleSoft’s approach allows businesses to remain flexible with the number and types of transactional systems of record they maintain. It also promotes a sense of data model flexibility, preventing the need for developing monolithic relational data models. In order to reach a unified view of data across systems, developers can create various extraction and transformation routines designed to continuously pull and process data from within a layer above source systems.
The MarkLogic Way
Now let’s switch over to discussing MarkLogic’s approach to integration. Rather than focusing on the application layer and middle-tier, MarkLogic focuses on the data layer.
With a MarkLogic Data Hub, users can begin by defining the entities that describe and represent their business concepts. From there, businesses can easily “stage” (import) data from numerous, siloed source systems, even though they come from heterogeneous data and security models.
Once the data is staged, the Data Hub progressively harmonizes (“canonicalizes”) the entities from various staged source systems into documents (JSON or XML) that provide a single view of business data. This is key for downstream analytics, as well as providing a simple point of access for other systems.
Progressive harmonization is a cyclical process, which commonly entails data element mapping, data governance, data lineage, provenance, enrichment, application of graphs and relationships, smart mastering, etc. Once completed, the documents are persisted, and secured with MarkLogic’s built-in, enterprise grade customizable security model.
The MarkLogic Data Hub then allows for simplified access to the data, via built-in and customizable REST APIs, SQL, SPARQL, and built-in search. MarkLogic’s security model is applied to any access endpoints, working in tandem with the persisted data security and making sure that all sensitive data remains safe. A goal of data hubs at large is to produce unified data, simplifying downstream consumption by other systems and users while simultaneously reducing the load on original source systems. A MarkLogic Data Hub achieves that goal.

Figure 3: With the MarkLogic Data Hub, you bring the data in as is, curate it, apply security and governance, and make it accessible. And, it’s flexible so you can avoid having to model everything at once, and you don’t have to change it every time the data or business needs change instead of manually doing ETL.
Why Use MarkLogic and MuleSoft?
MuleSoft provides agility for in-flight data at the API layer. MarkLogic provides agility and data persistence at the data layer.
By integrating data and creating durable data assets, MarkLogic makes it simpler to get a unified view of data that MuleSoft can then interface with. Rather than interfacing with many systems and facing challenges with siloed data (see examples below), MarkLogic provides a curated, consistent, high performant backend system.
Solving Some Common MuleSoft Challenges
Getting more specific, there are some common challenges some users may run into when developing a network of services with MuleSoft that MarkLogic can help solve:
1. Data re-processing on each request – Data returned from the source system API calls may have to be continuously re-processed upon each request. Applying this logic over and over in order to formulate a response may slow down processing when using MuleSoft.
How MarkLogic Helps – MarkLogic provides a fast, scalable query engine for handling requests from a centralized source.
2. Complexity with duplicates – Oftentimes there are duplicate records in different source systems. The logic to match and merge those records should not be managed through APIs and executed for each request.
How MarkLogic Helps – MarkLogic’s Smart Mastering capability makes it easy to match and merge duplicate data using AI, persisting the data and making it widely accessible.
3. Data proliferation – Many users want to generate aggregations or other analytics about data over time and across source systems. Typically this would mean deploying a separate data warehousing solution alongside MuleSoft.
How MarkLogic Helps – There’s no need to deploy another warehouse. MarkLogic can handle data aggregations and advanced analytics. MarkLogic can serve up SQL views for BI tools and other use cases, and also has leading semantic graph capabilities.
4. Governance tracking – When persisting to intermediate data stores, it is critical that the data is stored securely. This is especially true as data from different sources is combined in ways that the source system security models do not account for.
How MarkLogic Helps – MarkLogic takes the burden off of developers by centralizing data security and governance and providing end-to-end data tracking as the data changes.
How It Works
In a nutshell, MuleSoft and the MarkLogic Data Hub work together to move data from the source systems (capturing the delta), process the raw data via MuleSoft flows, and write that data to MarkLogic using the MarkLogic Connector for MuleSoft.
The data is persisted and protected inside the MarkLogic Data Hub using a robust, customizable role-based security model. MuleSoft flows can then be used to orchestrate processing of the data within the MarkLogic Data Hub (running data mapping, matching, merges processes for example). Lastly, MuleSoft APIs can access data via the MarkLogic Connector for MuleSoft or via data services that are exposed from the data hub.
It is important to note that the source systems remain the system of record. The role of the MarkLogic Data Hub in this architecture is the system of insight and engagement. That is, MarkLogic provides a single point of integration to get a business-critical, canonical view of data across systems and minimize the pattern of transformations happening upon each API request.
The strength of the MarkLogic Data Hub lies in easing access and retrieval for analytics, reporting, and mastering data from different sources. The canonicalized, mastered view of data across business entities for insights is what drives that engagement downstream.
While MuleSoft and the MarkLogic Data Hub can handle a wide variety or use cases, they also interact well with other modern data management technologies. If you already have a data warehouse or data lake, that’s okay.
For example, you could use MuleSoft to integrate source systems to a data lake, and then orchestrate data movement and harmonization in MarkLogic to feed both external service consumers and analytical structures to data warehouses.
Shopping Application Example with MuleSoft and MarkLogic
Let’s revisit the original API-led connectivity diagram (Figure 3) to help illustrate an example shopping application.
In the shopping application architecture, there are multiple systems with customer records and there may be overlap. So, it is beneficial to add a MarkLogic Data Hub to deduplicate (master) those customers and track analytics about their orders and order histories.
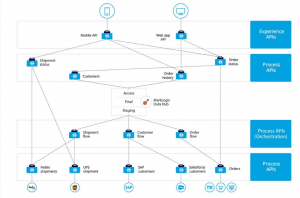
Figure 4: Logical view showing the role of Data Hub as a layer between source APIs and systems, and process APIs. Source system data goes into Data Hub, gets harmonized and secured, and made available for downstream access. System APIs still remain available in the service network as there may be certain use cases that require synchronous access from the client through to the source systems.
By also including the shipment information in MarkLogic, we can provide customers with alerts about shipment status changes as well as order and shipment analytics over time to get a true 360 degree view of the customer data.
The Data Hub enables the implementation of MuleSoft process APIs that may have been complex or even impossible to implement in the past. But, in cases where process APIs need to connect directly to the system APIs, the addition of the Data Hub does not prevent that from happening.
Synchronous vs asynchronous data operations
Looking again at Figure 4, it is also important to note that the existence of a Data Hub and APIs does not in any way preclude usage of existing process or experience APIs (including their security mechanisms) that existed in the MuleSoft application network. In fact, the seasoned MuleSoft user may be asking: “when do I use a Process API, and when do I use an API exposed by the MarkLogic Data Hub Final database?” The existing MuleSoft APIs – especially those used for synchronous data operations – do not have to change. They can be invoked the same as always, without involving the Data Hub. Because the usage of a Data Hub is more about asynchronous data operations, like supporting analytics and mastering across business entities, the APIs and security associated with the Hub pertain more commonly to these business functions.
At this point, seasoned MarkLogic and MuleSoft users might also ask: “for which component(s) should I apply security?” This is an important question, because both have robust security offerings, either of which could individually be used to protect sensitive data in any scenario. As previously mentioned, the main distinction between the two is that MuleSoft applies security on data in-flight, and MarkLogic primarily protects data at-rest with role-based access control. Our recommendation is to protect both data in-flight and at-rest. The approaches are complementary and further bolster overall application security. The only use case to not implement any MuleSoft APIs and security in front of MarkLogic are when accessing MarkLogic directly over protocols such as ODBC or XDBC.
Enhanced Security
MuleSoft’s security offerings provide the means to front-end MarkLogic applications with mechanisms such as OAuth 2.0 via OpenID, attribute-based access control, request throttling, and IP whitelisting. MarkLogic’s security model enhances MuleSoft’s capabilities via use of role-based access controls on persisted documents, with compartment security, encryption-at-rest, and element-level security. Both technologies readily support redaction.
As illustrated in Figure 5, when applying authentication and authorization on both components with HTTPS on every REST API, there is a MuleSoft Experience API and application workflow for Orders, which sits atop the MarkLogic Data Hub. MarkLogic has an identity and access management provider that is used by both components for verifying and validating user credentials via certificates. The MarkLogic Connector for MuleSoft works well with certificate-based authentication, using a two-way TLS handshake.

Figure 5: Certificate-based authentication and application security at both MuleSoft and MarkLogic components, via an external identity provider platform. Derived from “MuleSoft’s API Security Best Practices” whitepaper at:https://www.mulesoft.com/lp/whitepaper/api/protect-apis.
In the example scenario, let’s consider a user, Janet, who is part of the Orders team and wants to access orders analytics data that has been harmonized in the Data Hub. Janet first accesses the Mule application over HTTPS. MuleSoft Security will then interact with the identity provider platform to authenticate Janet and get her certificate. This certificate is then part of the request to MarkLogic to access the orders. MarkLogic security then determines if the Orders API in Data Hub is using internal or external security. If the former, and Janet exists as a user in MarkLogic, she is authenticated and authorized to access the data. If the latter, then MarkLogic works with the identity provider to determine the validity of Janet’s certificate, and to optionally determine her authorization based on the Subject DN of her certificate, corresponding to defined roles in the MarkLogic security model. Those roles then work with application server, document- and element-level security controls, compartment security, and redaction to determine what Janet can see.
Conclusion
A MarkLogic Data Hub enhances what you can do with MuleSoft by providing curated, governed, secure, durable data assets for agile, API-led environments. MuleSoft enhances what you can do with a MarkLogic Data Hub by providing connectivity to source systems and robust API management for accessing integrated data.The end result? You get full operational use of your data faster than ever.
Stay tuned for Part 2 where we’ll dive into a specific implementation and go into additional detail to show how MarkLogic and MuleSoft work together.
