
Bitemporal, which was released in MarkLogic Server version 8, allows you to track database documents along two time axes simultaneously. It lets you keep track of when an event occurred (the valid time), as well as when the data was entered into the database (the system time). Let’s say I write a blog article describing something that happened on Tuesday and I don’t upload it to my database until Wednesday. This would be an example of bitemporal data, with the valid and system times being a day apart.
In some industries— financial services, insurance, healthcare, intelligence, law enforcement— keeping track of these different times is extremely important. Understanding when information was known, and being able to recreate that historical record in the case of an audit or to perform analytics after the fact, is critical.
However, keeping bitemporal data consistent and searchable as documents are added to a database is a complicated process. Analyzing bitemporal documents involves going back in time, with two measures of time changing in different ways. Our brains aren’t used to thinking this way. As complicated as it might seem, MarkLogic didn’t need to invent a lot of new technology to support bitemporal; it was more about taking features and concepts that were already in place in MarkLogic and combining them to support a powerful new way of tracking data.
Under the hood, bitemporal involves the following:
- Managing document versions with timestamps (in the case of bitemporal, two for valid time and two for system time)
- Organizing documents into collections so that they can be effectively sliced and diced
- Indexing time information with range indexes for fast, composed document lookups
We’ll examine how these features apply to bitemporal in the context of an example.
A Bitemporal Example
Imagine we’re an intelligence agency tracking the location of a person of interest. We can store this information as a MarkLogic bitemporal document [1]. As the person’s location changes, the document is updated, and MarkLogic keeps all versions of the document over time so we always know where we thought the person was located.
Let’s say the person moved to the city of Alameda on January 1 and we add the data to our database on January 5. A bitemporal document includes four time values: valid start, valid end, system start, and system end. For the first version of our document, the start values tell us when the person was in Alameda (valid start) and when we knew it (system start). The end values are set to infinity:
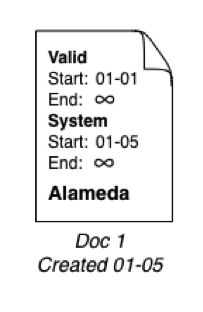
Figure 1: Document that shows where the person was in Alameda and when this data was recorded.
On January 12, we learn that the person moved to Berkeley on January 10, so we submit a new document. To go with this new Berkeley document, MarkLogic creates a document to reflect the person’s time in Alameda as we know it now. MarkLogic also updates our first Alameda document to give it a system end date. That first document is now a historical record of what we knew about the person prior to January 12:
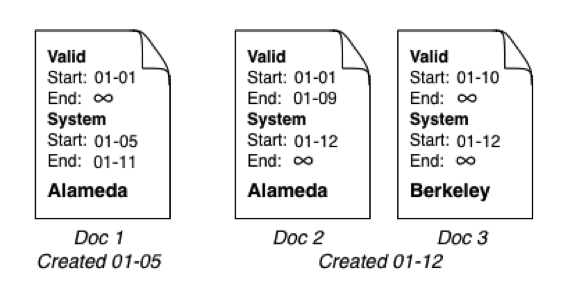
Figure 2: Historical record, new Berkeley document, and a document that reflects person’s time in Alameda known now.
On January 15, we discover a mistake: the person actually moved to Berkeley on January 8. Not a problem— all we need to do is insert a revised document for Berkeley and MarkLogic creates a new one for Alameda, with the valid time range adjusted. It also sets the system end times for the previous set:
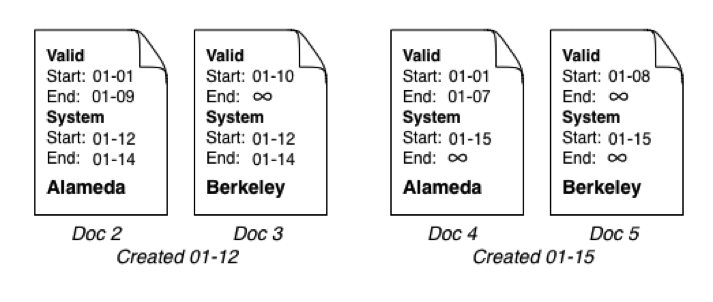
Figure 3: Original Berkeley document, document that reflects person’s time in Alameda incorrectly recorded, revised document for Berkley, new document for Alameda with time range adjusted.
On January 18, we find out the person we are tracking isn’t who we thought they were. The previous information is now invalid, so we perform a bitemporal delete. Behind the scenes, MarkLogic updates the end values in the latest set of documents (rather than actually deleting documents from the file system):
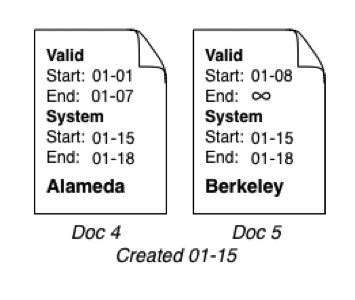
Figure 4: Following bitemporal delete, MarkLogic updates end values of latest set of documents.
Version Tracking with Timestamps
As we saw in the example above, timestamps are the key to bitemporal. As bitemporal documents are added to a database, MarkLogic keeps the timestamps for the document versions consistent. Thanks to MarkLogic’s temporal functions, all a bitemporal application needs to do to update a document is insert it with a new set of valid times. MarkLogic takes care of the rest, including:
- setting system timestamps in the new document
- updating the system end times for existing documents [2]
- storing any additional documents versions to fill in the historical record
Each update results in a new current version of the document with a new system start time. Other versions representing the document’s history may be associated with the same system time range, but their valid time ranges will never overlap. We can visualize all this as a two-dimensional chart. Below, the system time is on the horizontal axis and the valid time is on the vertical axis. The shaded boxes represent the five document versions in the example.
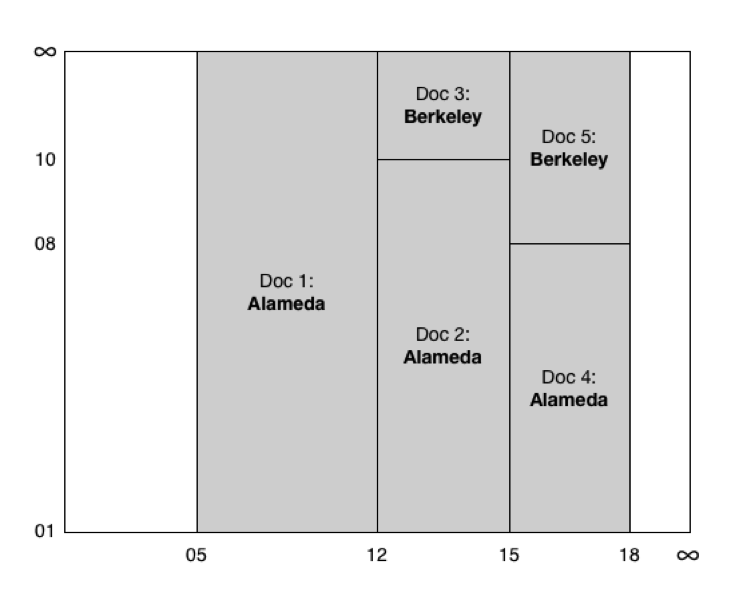
Figure 5: Versions of a bitemporal document visualized as a two-dimensional chart. The horizontal axis shows the system time and the vertical axis shows the valid time. Shaded boxes represent different versions of the same document.
Viewing the data this way is so helpful that there’s a Bitemporal Explorer application that lets you search your bitemporal data by dragging the axes of a chart.
Other Timestamps in MarkLogic
Managing bitemporal data with timestamps is an extension of how MarkLogic manages all the documents in a database. Setting aside for a moment the bitemporal-specific timestamps, each MarkLogic document also has hidden creation and deletion timestamps. When a document is inserted, the creation timestamp is set to the current time and the deletion timestamp is set to infinity.
When a document is updated, instead of updating the existing version, MarkLogic creates a new version and gives it a new creation timestamp. To mark the old version as no longer current, it sets that document’s deletion timestamp (this is also how documents are deleted).
Search queries can now ignore the old versions of the documents based on the timestamp information, and all versions can peacefully coexist. Older versions of documents are eventually deleted from the file system during a separate merge process. This data management strategy, which again, is separate from bitemporal and at a lower level, is known as Multi-Version Concurrency Control (MVCC).
Bitemporal documents are just like all other MarkLogic documents in that MarkLogic gives them hidden creation and deletion timestamps at ingest and uses this information when performing document updates.
Remember that the creation and deletion timestamps are internal to the MarkLogic system and are used for document housekeeping to support MVCC. The valid and system timestamps in bitemporal are actual properties of the documents and can be read by applications just like the rest of the document content.
Categorizing with Collections
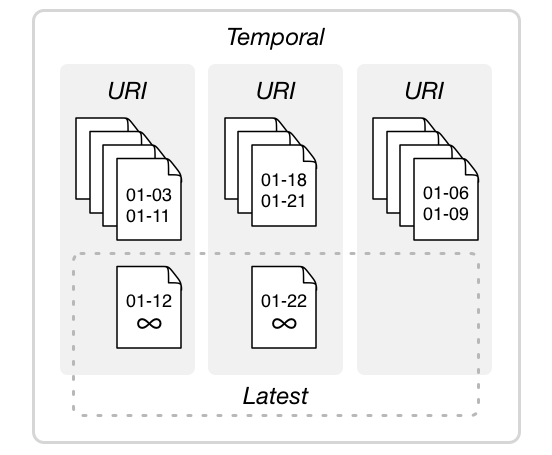
Figure 6: Bitemporal documents in a MarkLogic database are organized into three collection types: temporal, URI, and latest. Collections enable MarkLogic to retrieve sets of documents quickly.
Another aspect of bitemporal is how it uses collections, which are a way to categorize documents in MarkLogic. Think of them as tags— you can create a collection (e.g., “customers” or “products”) and then tag documents with that collection as they are ingested. Each collection is indexed, which enables MarkLogic to retrieve all the documents in a collection quickly from memory.
As you store bitemporal documents, MarkLogic automatically groups them using three collection types. First, all of the bitemporal documents go into a temporal collection. This lets you distinguish them from non-temporal documents that may also reside in your database. You set up the name of this collection when you configure your database for bitemporal.
The temporal collection is actually a special type of collection since the only way to add to it or delete from it is through the temporal functions– that way, the history of your bitemporal documents stays untainted [3].
Secondly, all the versions of a document that get created over time are assigned to a URI collection. In our location-tracking example, if our original document had the URI “person.json,” each version of that document would be assigned to a “person.json” collection. If we inserted a second document with the URI “person2.json,” that document would be assigned to the “person2.json” collection. URI collections let us retrieve all the versions of a single document in a bitemporal database.
The third type of collection that is created for bitemporal documents is a latest collection, which consists of the most recent, active versions of the documents— that is, documents with system end times set to infinity. When a new version of a document is inserted, it is put into the latest collection and the document it is updating is removed. Documents that have been deleted in a bitemporal collection will not have a latest version.
Range Indexes for Search
The other key to bitemporal is the range index. All four of the timestamps in a bitemporal document are associated with range indexes. This is required for making bitemporal data searchable and making those searches fast.
How does a range index work? It takes all the values for an element in all the documents in a database, orders those values, and maps each value to the documents in which it appears. This makes solving inequality queries for that element straightforward. All MarkLogic has to do is look up the bounds associated with the inequality query in the range index and return the document IDs for that range. Because range indexes are memory mapped, this process is extremely fast.
Consider the following query on our example bitemporal data set: what were the locations of our person of interest between January 8 and January 9 as we knew them between January 13 and January 14?
This involves querying all four of our range indexes. We know that for every range that goes into our database, the end date will be after the start date. So we can break this query into the following inequalities:
Valid Start <= 01-09 Valid End >= 01-08 System Start <= 01-14 System End >= 01-13
Consulting the range indexes gives us the following:
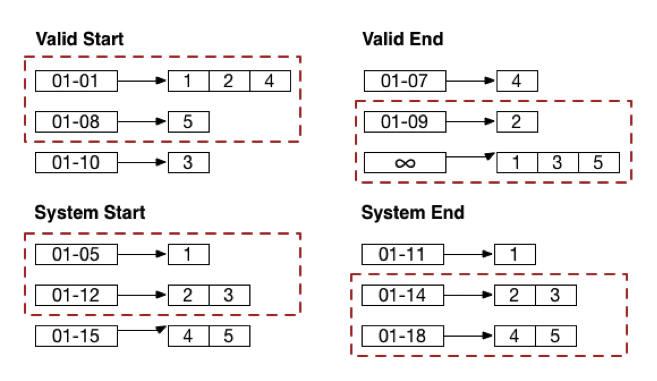
Figure 7: Result of querying four range indexes. Following consulting range indexes on our documents, which takes all the values for an element in all the documents in a database, orders those values, and maps each value to the documents in which it appears, as seen above.
Performing an intersection on the four result sets gives us a single document — in this case, #2. This tells us the person was in Alameda during our resulting time ranges. We can confirm that this is indeed the answer using our two-dimensional chart:
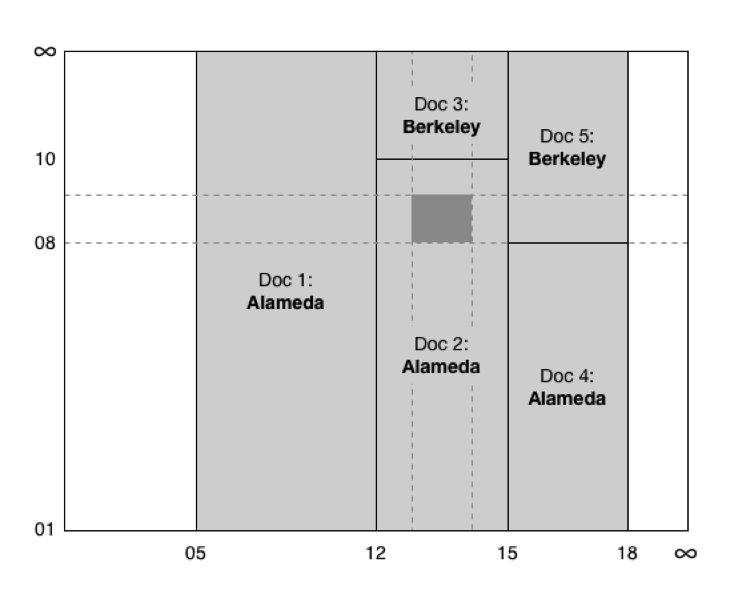
Figure 8: Confirming the results of the queries on the range indexes using a two-dimensional chart.
Let’s say our data set was much more complicated, with millions of documents representing other people. We could isolate the results to just our person of interest by including a URI collection constraint in our query. (Similarly, we could return only the latest information by including a latest collection constraint.)
You can imagine many other types of comparisons. For example, what if we wanted to find out if our person’s time in Berkeley overlapped with another person’s time in the same city? Or if one person started living in Alameda just as another person left Alameda?
Formulating range queries across two bitemporal axes and four range elements is complicated, so MarkLogic offers shortcuts for creating temporal queries by using the relations defined by Allen’s Interval Algebra. These relations define all the possible relationships between two time intervals (e.g., preceding, overlapping, containing, meeting, finishing, etc.). MarkLogic also provides API functions for defining time ranges.
With these tools, applications can define a time period (for the system or valid time ranges) and combine those with Allen’s Interval Algebra operators to formulate any possible relationship among the time ranges in the bitemporal data. Under the covers, MarkLogic converts these queries to range index queries similar to what we described above.
For example, the previous search example could be written in XQuery using the contained-by operator for defining the system and valid parts:
cts:search(fn:doc(), cts:and-query((
cts:period-range-query(
"valid",
"ALN_CONTAINED_BY",
cts:period(xs:dateTime("2015-01-08T00:00:00"),
xs:dateTime("2015-01-09T23:59:59.99Z"))),
cts:period-range-query(
"system",
"ALN_CONTAINED_BY",
cts:period(xs:dateTime("2015-01-13T13:00:00"),
xs:dateTime("2015-01-14T23:59:59.99Z"))))))To see the contribution of the range queries, you can wrap the query above in xdmp:plan. MarkLogic also lets you define time relations using a set of SQL 2011 operators, which are similar to Allen’s operators but less restrictive.
Conclusion
Through leveraging central features such as timestamps, collections, and range indexes, MarkLogic has created a powerful way for users to maintain a historical record of documents as they change over time. You can learn more about setting up and using bitemporal data in your applications with this white paper on Bitemporal in MarkLogic.
Thanks to Fei Xue and Chris Lindblad for their help with this article.
Footnotes:
[1] Bitemporal involves storing and managing lots of versions of time-stamped data. Modeling such data as self-contained documents in MarkLogic means that versions of data can be easily copied, updated, or deleted as time goes on. This is easier than with a relational database, where data is typically broken up, normalized, and stored across many tables.
[2] You can manually adjust the system times if you need to with the Last Stable Query Time feature.
[3] You can allow administrators to update documents in a temporal collection using non-temporal functions with the temporal:collection-set-options function.

