
The recent Whole Foods acquisition by Amazon got me thinking about culture and how people store their data. If you equate bits of data to jars of spaghetti sauce, most people store their data like a grocery store; in long rows and columns. But Amazon uses a much more efficient method, called “chaotic storage,” that allows them to shake up the classic warehouse paradigm (both the physical warehouse and data warehouse), making the old “rows and columns” warehouse model a target for disruption.
The thought behind the layout of the grocery store is that consumers need a friendly interface to find what they need. That is the way most data warehouses are laid out as well. Think about the Oracle “scott/tiger” schema model we all studied:
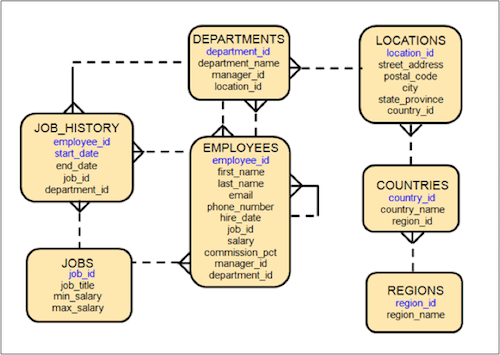
This view looks fairly straightforward. Employees are connected to departments, departments to locations, and so on. But the problem comes when you try to assemble an output that the designers did not predict. You end up making expensive joins all over the database to try to get the right result. Similar to our grocery store example, if you want to make spaghetti, the sauce is typically stored in the same aisle as the pasta. But if you want to add fresh veggies and Italian sausage, then suddenly your quick stop at the market becomes a 5k race because those products are kept at the other end of the store.
Load As Is Throws Out the Rows and Columns Approach to Data Storage
The downfall of the traditional, normalized relational structure is that the designers and the users must know the layout of the data long before the first bit of data is loaded. If the requirements of the project change then users are left joining data from one side of the database to the other.
Amazon decided long ago that its business moved too fast to go with a rows and columns approach for storing either data or physical goods. They receive goods as is and they store them as they come in so they know where things are stored and can position fast-moving products closer to the door. If the product mix changes later they can reconfigure how they store product on the fly, maximizing flexibility and driving down cost.
This is similar to the way that we build Entities in MarkLogic. We take all the information regarding an entity (customer, patient, asset) and turn it into an XML or JSON document. As the information changes (new demographics, notes, specifications), we can change the structure of that one document to reflect the new information. We can even include links to other documents and data using semantic relationships embedded in the documents. Applications that read that document can either be configured to use or ignore the new information.
NoSQL Fixes Old Way of Thinking About Relational Data
The brick and mortar store and the relational data warehouse both suffer from the old way of thinking: that the end customer is going to want to find the product themselves. Amazon has proved that the way customers discover and acquire products (either data or physical goods) and the way that products are stored do not have to be directly related. Amazon uses a sophisticated index to manage the relationship between the customer and fulfillment.
The same thing is going on with how companies store their data. Relational data warehouses are beginning to be pushed aside in favor of more flexible NoSQL solutions. There are several variants of NoSQL (document, key-value, graph, columnar, multi-model) and they all have strengths and weaknesses when it comes to storing data. Some of the variants (key-value, graph) are better at analytics than transactions. Many of the products are open source and lack the enterprise features that businesses require.
Flexible Data Leads to Better Customer Experience
MarkLogic combines the power of a multi-model, NoSQL database (XML or JSON documents, text, binaries, meta-data from binaries, RDF, geo-spatial, structured values/columns) with enterprise search and security, allowing end-users to find exactly what they need without having to understand how the data is stored. Likewise, MarkLogic allows data warehouse designers the flexibility to change the model at-will, without impacting the customer experience.
The secret is that every record in the database can have its own schema. The records are formed into documents that can contain disparate data, RDF triples, and other elements to reflect the nature of how the data is going to be used.
Think of a simple transaction, buying the ingredients for spaghetti:

In a relational schema this data would be split into four or more tables and reconstructing it would take expensive joins. But in MarkLogic, all of the data for this transaction could be stored in a single document:

To extend our spaghetti metaphor, this gives us the ability to store all of the ingredients for the recipe in one place, even if those ingredients are combined differently in another recipe. The way the data is stored is not dependent on the way the data is used. The user can decide later how they want to consume the data and MarkLogic can react quickly to fulfill the need.
Improving the Way Companies Handle Data
There are costs to this approach. For example, in order to find anything, the data must be indexed. But MarkLogic includes an “ask anything” Universal Index and search engine so finding the data is quick and easy. This index drives up storage and compute requirements, but sophisticated compression and the efficiency of low-cost, commodity, scale-out hardware help level the field.
For years, conventional wisdom told us the only way to store product was in long rows like a brick and mortar store. But Amazon showed us that we can divorce how the products are stored and employ a much more efficient, low cost, scalable solution for storing product (either physical or digital), enhancing the customer experience with powerful search and fulfillment. MarkLogic is also changing the way that companies store and retrieve data like Amazon is upending the traditional brick and mortar way of storage and retrieval.
There are going to be those who disagree and refuse to shift from the standard “row and column” way of thinking. But the latest example of brick and mortar giving way to a more flexible, scalable solution is not the last time we will hear about this kind of change. Change is coming.
Let MarkLogic help you understand how to future proof your data warehouse and why we are the leader at offering flexible, powerful data solutions.
For More Information
Building on Multi-Model Database 110-page definitive book on multi-model databases, when they should be used and how they can benefit enterprises.
Introduction to MarkLogic 24-min free course on MarkLogic.

