
We are excited to announce support for using Apache NiFi to ingest data into MarkLogic. Apache NiFi is an open source tool for distributing and processing data. When used alongside MarkLogic, it’s a great tool for building ingestion pipelines. NiFi has an intuitive drag-and-drop UI and over a decade of development behind it, with a big focus on security and governance.
Ingesting Relational Data to NoSQL with NiFi
One of the historical challenges to adopting new NoSQL databases is getting legacy relational data migrated over. Relational databases store data in rows and columns in a highly normalized form. MarkLogic, a multi-model NoSQL database, stores data as JSON and XML documents and RDF triples. Typically, you group data into natural “entities” that are modeled as documents, and you add RDF triples to capture meaningful relationships among the entities.
NiFi helps to naturally group your data by either converting relational rows to small documents or joining groups of rows together into hierarchical structures using primary/foreign key relationships. With new MarkLogic processors, this data then moves quickly into MarkLogic with minimal configuration and high performance.
The NiFi approach uses the data model that already exists in the relational database to the extent possible, avoiding costly, fragile and slow ETL jobs. Existing approaches such as MarkLogic Content Pump (mlcp) still work well for getting data into MarkLogic. But, NiFi makes the whole process of ingesting relational data to MarkLogic faster and easier. And, you don’t need to buy a separate ETL tool.
If you are interested and want to become an expert, read the white paper that discusses why you should Rethink Data Modeling, or watch the presentation on Becoming a Document Modeling Guru.
Here is an example:
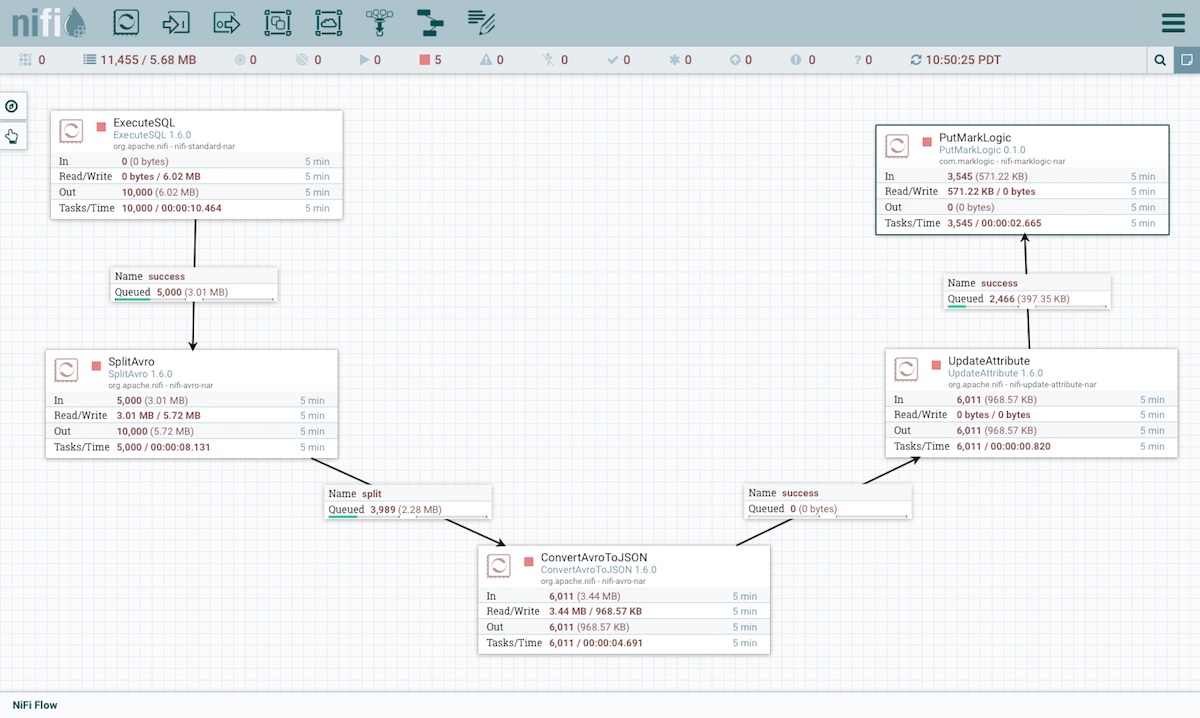
The above screenshot shows a simple process for getting relational data into MarkLogic. An SQL query is executed to get data out of a relational system. Then, a NiFi processor converts the resulting Avro serialized data to JSON, and the JSON data is put into MarkLogic. Watch this five-minute demo that shows how to get relational data ingested into MarkLogic using NiFi.
Main Benefits of Using Apache NiFi
NiFi is designed and built to handle real-time data flows at scale. But, NiFi is not advertised as an ETL tool, and we don’t think it should be used for traditional ETL. The sweet spot for NiFi is handling the “E” in ETL. It extracts data easily and efficiently. If necessary, it can do some minimal transformation work along the way. We think it’s better to let the database (i.e., MarkLogic) take care of the data transformation and harmonization.
The main benefits of NiFi include the following:
- NiFi is proven in the enterprise – NiFi has 10 years of development behind it, with a focus on data security and ease of use. After being initially released in 2007, NiFi was donated by the NSA to the Apache Foundation in 2014 and has since been supported by an active community, including Hortonworks.
- NiFi security and governance is a great fit for MarkLogic – NiFi does a great job tracking data provenance for every job it executes. Also, NiFi encrypts each step in the data flow, uses authentication and provides pluggable role-based authorization. We consider these features a natural fit with MarkLogic’s focus on security and data governance.
- NiFi is designed for scale – NiFi is designed to scale-out in clusters and provides guaranteed delivery of data. It is asynchronous, which allows for very high throughput and natural buffering even as flow rates fluctuate. It also has data buffering and pressure management as queues reach limits and customizable prioritization schemes for retrieving data from queues.
- NiFi connects to almost anything – NiFi is highly extensible and has over 50 processors that enable you to connect to almost any data source: AWS, MySQL, Hadoop, other NoSQL databases, web services, RabbitMQ, Kafka and much more. We built processors specifically to use with MarkLogic, but if a certain processor does not exist, NiFi makes it easy to build your own—it is designed from the start to be highly extensible and limit the amount of custom code that ever needs to be written.
- NiFi’s drag-and-drop UI is easy to use – People have been using boxes and arrows to describe data movement since the advent of dataflow programming in the 1960s, and NiFi provides a very easy-to-use implementation of dataflow programming. And, with templates, you can reuse a dataflow that someone else already created. As changes are made to flows, they occur in real time.
Key Concepts with Apache NiFi
The main concepts to understand when using NiFi are dataflows, processors and connections. You create a dataflow by wiring together processors with connections. A dataflow can be saved as a template, and these templates can be combined into more complex flows and reused or replicated across servers.
The following table from Hortonworks provides a very nice summary of the individual components and how they map to dataflow programming:
| NiFi Term | FBP Term | Description |
| FlowFile | Information Packet | A FlowFile represents each object moving through the system, and for each one, NiFi keeps track of a map of key/value pair attribute strings and its associated content of zero or more bytes. |
| FlowFile Processor | Black Box | Processors actually perform the work. In Enterprise Integration Terms, a processor is doing some combination of data routing, transformation or mediation between systems. Processors have access to attributes of a given FlowFile and its content stream. Processors can operate on zero or more FlowFiles in a given unit of work and either commit that work or rollback. |
| Connection | Bounded Buffer | Connections provide the actual linkage between processors. These act as queues and allow various processes to interact at differing rates. These queues then can be prioritized dynamically and can have upper bounds on load, which enable back pressure. |
| Flow Controller | Scheduler | The Flow Controller maintains the knowledge of how processes actually connect and manage the threads and allocations that all processes use. The Flow Controller acts as the broker facilitating the exchange of FlowFiles between processors. |
| Process Group | Subnet | A Process Group is a specific set of processes and their connections, which can receive data via input ports and send data out via output ports. In this manner, process groups allow for the creation of entirely new components through the composition of other components. |
Source: Hortonworks
How NiFi Works with MarkLogic
Using NiFi with MarkLogic is similar to using NiFi with any other database—you just need to use the processors specifically built for getting data in and out of MarkLogic.
There are currently two processors built for MarkLogic: the PutMarkLogic processor for ingesting data into MarkLogic and the QueryMarkLogic processor for querying documents in MarkLogic. Both of these processors are built on top of MarkLogic’s Data Movement SDK.
The below list of capabilities provides a general idea of what each processor is capable of.
Capabilities of the PutMarkLogic Processor
- Can set the batch size of the batches for sending documents to MarkLogic
- Can set the threadcount used to process the batches to be written to MarkLogic
- Can set the job ID or job name, which translates to WriteBatcher’s job ID and job name
- Can set the collections and permissions on the documents being ingested
- Can apply transforms on the documents being written to MarkLogic
- Can apply user-defined properties for transforms
- Can apply expression language on the Collections field, enabling you to supply flow file attributes rather than just strings
- Can set URI prefix and suffix to the URIs
Capabilities of the QueryMarkLogic Processor
- Can query MarkLogic based on collections. For example, take a comma-separated list of collections and export all of the documents in those collections.
- Can set the batch size of the batches for sending documents to MarkLogic
- Can set threadcount used to process the batches to be written to MarkLogic
- Can export all of the documents matched by the collections in a consistent snapshot (i.e., all of the documents are exported as they were in the database when the processor is triggered)
Getting Started with NiFi and MarkLogic
The steps below illustrate how fast and easy it is to get started using NiFi with MarkLogic.
Download NiFi
Download the NiFi binaries from http://nifi.apache.org/download.html. Make sure you’re on the latest release of NiFi (1.7). Unpack (i.e., unzip) the tar or zip files in a directory of your choice (for example: /abc).
Download Processors
Clone the MarkLogic/nifi-nars repository to get the MarkLogic-specific processors located in the GitHub repository.
Organize Files
Place the MarkLogic-specific processor files in the correct directory. To do this, copy the two .nar files provided by MarkLogic in the zip folder into the lib folder (nifi-1.7.0/lib) of the unpacked NiFi distribution.
Start NiFi
Go to the Apache NiFi Development Quickstart and follow the commands in the Decompress and Launch sections. Note that you do not need to follow the decompress instructions. Also, make sure that you are in the directory of your NiFi installation. If not, change your directory using a command (e.g., “cd /abc/nifi-1.7.0”). Now, you are ready to follow the launch instructions provided in the Apache NiFi Development Quickstart for your particular environment.
Run NiFi
Now, you’re ready to run NiFi using your browser. You can point to a web browser at http://localhost:8080/nifi/ to run NiFi. Make sure you are running MarkLogic version 9.0+.
MarkLogic Resources
- MarkLogic University Training – http://mlu.marklogic.com/ondemand/226eec61
- MarkLogic NiFi Connectors on GitHub – https://github.com/marklogic/nifi/releases
- Detailed tutorial for ingesting relational data with NiFi – https://www.marklogic.com/blog/apache-nifi-quickstart
Apache NiFi Resources
- Apache NiFi Development Quickstart – http://nifi.apache.org/quickstart.html
- Official Apache NiFi documentation – https://nifi.apache.org/

