
Today at MarkLogic World, we announced our latest releases: Data Hub 5.0 and MarkLogic 10. Together, they represent significant milestones in achieving our vision of simplifying complex data integration across the enterprise.
Our flagship product, the MarkLogic Data Hub Platform, is a full-stack offering that includes the MarkLogic Data Hub running on top of the MarkLogic® multi-model database. It is a unified platform to ingest data, curate it, apply security and governance and provide easy access to all that data for analytical and operational use cases. Our new product capabilities provide breakthrough improvements in ALL of these key areas, making the Data Hub smarter, simpler and more secure.
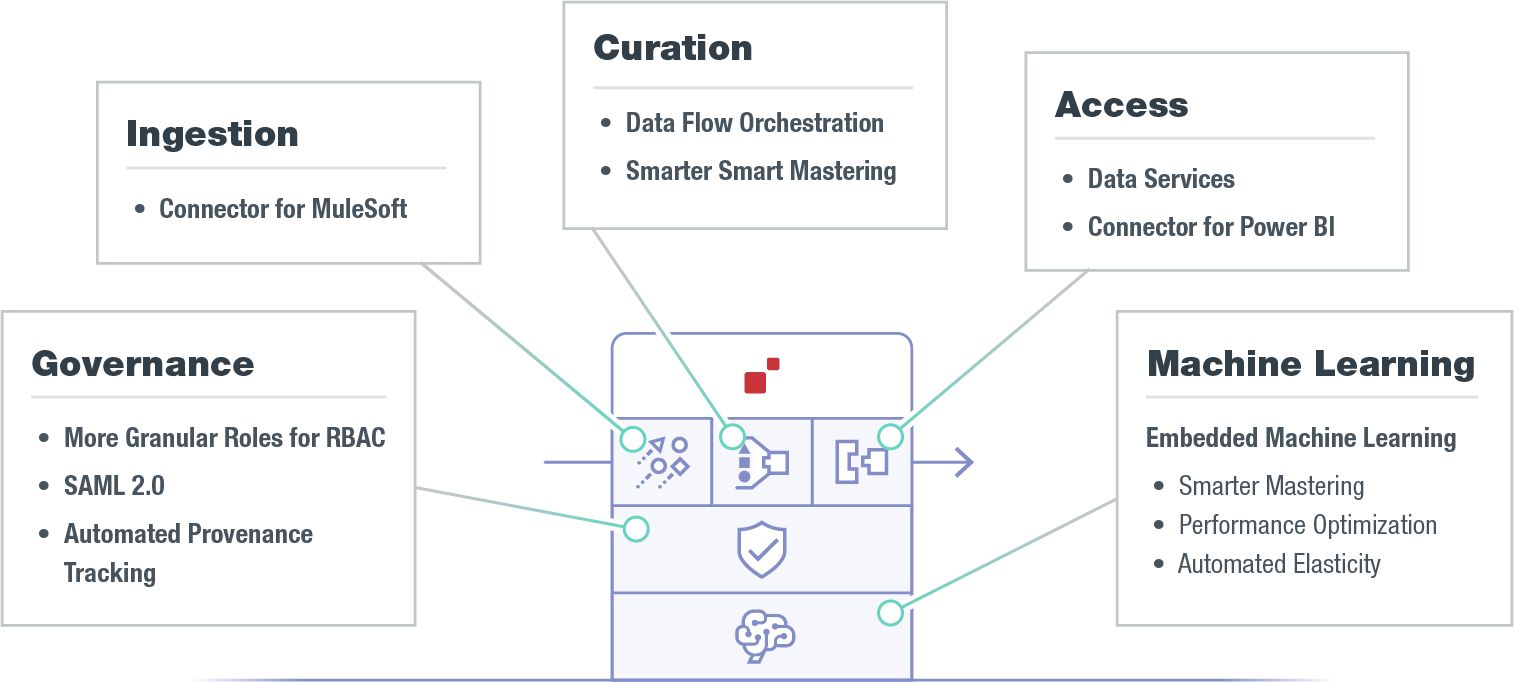
Figure 1: Key product announcements organized according to each functional area of the MarkLogic Data Hub Platform
There’s a ton of capabilities packed into our new releases, so I want to provide a summary that hits the highlights—similar to what was announced in the product keynote at MarkLogic World 19.
MarkLogic Machine Learning
Whether you want to do analytics, BI or machine learning, to get the best results, you need all of your data and you need it to be of high quality. Enabling the best results from machine learning is a big part of our motivation to make MarkLogic the best place to integrate and curate data. As you’ll see below, we are continuing our investments here, but we’re going well beyond that.
We are exploiting machine learning under the covers to make key functions smarter and more automatic. You’ll get the benefits from machine learning without having to be an expert on deep learning or neural networks.
But if you are an expert, we’re supporting you too. We’re exposing our new Embedded Machine Learning capability so that you can do your work (both training and executing models) right at the core of the database.
We will leverage Embedded Machine Learning to improve your data management and data-integration experience automatically on multiple fronts:
- How the database runs – With Embedded Machine Learning, MarkLogic will run queries more efficiently and scale autonomously based on workload patterns. With autonomous elasticity, for example, MarkLogic can use models of infrastructure workload patterns to automatically adjust the rules that govern data and index rebalancing.
- How you curate data – Embedded Machine Learning reduces complexity and increases automation of various steps in the data curation process. For example, with MarkLogic’s Smart Mastering feature, machine learning will augment the rules-based mastering process so that records are mastered with more accuracy, and models continue to improve as more data is processed—all with less human involvement. Another example is how Embedded Machine Learning will recommend mapping, mastering and security strategies that you can apply to your data. By assisting in the identification of PII or extracting entities from text, your model is improved and more secure.
Improving Speed and Security for Data Scientists
As a data scientist, you can use Embedded Machine Learning to run machine learning right inside the database. You can be directly part of the data curation process to build training data sets, evaluate and tune models and apply those modes to get results. Your organization will enjoy the added benefit of speed and security since it’s happening right inside the database—no forked copies of the data.
MarkLogic’s Embedded Machine Learning ships with MarkLogic 10 and provides a full set of built-in APIs for deep learning that runs securely and efficiently within the database kernel.
Still the Most Secure NoSQL Database
MarkLogic is the most secure NoSQL database. It is the only next-generation database with a Common Criteria Security certification and has the most granular security controls.
With the addition of automated provenance tracking, SAML 2.0 and continued enhancements to Role Based Access Control (RBAC), MarkLogic provides the security that enterprises need. While others move the responsibility for security up the stack, MarkLogic implements data security where it belongs—close to the data.
More Granular Roles
A user’s roles govern what they can see and do in a system, and it is critical that organizations be able to easily create and manage those roles. For that reason, Data Hub 5.0 leverages a rich set of granular controls that extend beyond what was already available through the underlying database. The new controls provide pre-configured roles and responsibilities that apply specifically to the Data Hub, enabling organizations to carefully manage users’ privileges and permissions. With these controls, development with the Data Hub is both easier to manage and safer. As you would expect, these controls are also leveraged by the MarkLogic Data Hub Service, enhancing cloud security even further.
Automatic Provenance Tracking
To answer a regulator’s questions about the validity of data, you have to know where it came from (provenance) and how it has been processed along the way (lineage). For simplicity, I’ll refer to all of this information as provenance metadata. The challenge is that with traditional tools, this metadata is often lost in complex ETL code, not tracked at all or is only accessible for advanced technical users.
MarkLogic is already known as an excellent platform for managing provenance metadata, relying on the flexibility of our multi-model approach. That is why so many banks use MarkLogic to track their trade data and why government agencies use MarkLogic to manage intelligence information.
Data Hub 5.0 makes an important step forward by automating provenance tracking. The Hub automatically tracks provenance information for ingestion, mapping and mastering operations. This improves data quality with no additional implementation effort. It also makes this information easily accessible for non-technical users who want to view governance information to answer business questions without requiring time from a developer.
Here are some examples of the provenance metadata tracked by the Data Hub:
- When was this data created? The Data Hub tracks transaction IDs and timestamps of all the data curated.
- Where did this data originate? The Data Hub tracks when harmonized entities are created in the orchestration flow.
- How did the source data change? The Data Hub tracks how source data changed through the process.
- Which user changed the data? The Data Hub tracks which user made the changes based on their roles and permissions.
Support for SAML 2.0
MarkLogic 10 now supports Security Assertion Markup Language 2.0 (SAML 2.0), which enables single sign-on (SSO). This provides many advantages over usernames and passwords. There is no need to type in credentials, remember and renew passwords or deal with weak passwords. It is built on the idea that because most organizations already know the identity of users through their Active Directory domain or intranet, the organization can securely reuse the login info for other applications. MarkLogic uses SAML 2.0 to interact with an identity provider such as Ping Identity or One Login.
To support SAML 2.0, MarkLogic relies on browser-based and pre-authenticated tokens that can be used via REST, the Java API and Node.js API.
Encryption Support for Entrust Hardware Security Appliances (HSMs)
Many large enterprises have already made an investment in key management technology and want to leverage that investment with MarkLogic. Starting in MarkLogic 9, we have provided the capability to deal with a number of key management systems, and with MarkLogic 10, we now support third party HSMs, which currently includes the Entrust nShield Connect HSMs (Hardware Security Appliances) for Encryption at Rest on both Windows and Linux platforms.
This new capability further expands the key management options we make available to customers. Of course, customers may also choose to use MarkLogic’s own internal keystore.
Our support for Entrust nShield Connect is of particular interest to government agencies that are moving to the cloud. Many of them require the use of PKCS #11, which the Thales HSM supports. PKCS #11 is one of the most widely implemented cryptography standards in the world. It specifies a platform-independent API for cryptographic tokens that store and control authentication information. Of course, other industries can also take advantage of PKCS #11 to get the very best security with MarkLogic.
Easier Curation with Data Flow Orchestration
As the name implies, Data Flow Orchestration is about creating a smooth, orchestrated flow of data through the system from ingestion to use. In Data Hub 5.0, we’ve added customizable low-code/no-code (LCNC) data orchestration flows that make it easier for end-users to map data sources and run matching and merging data flow processes.
With this new capability, using the Data Hub is much simpler because data architects and business analysts can run data flows based on pre-set configurations without writing a single line of code.
Figure 2: Snapshot of data flow orchestration in Data Hub 5.0
How does it work?
In the Data Hub user interface, you can configure a data flow as a series of steps. There are four types of steps:
- Ingestion: You can wrap your data with additional metadata. MarkLogic automatically captures important governance data, but let’s say you want to also add some additional metadata related to business descriptions, semantic linkages or other data-quality or source system information. That happens in this step.
- Mapping: You can associate fields in your source data to the fields in your harmonized entity model. For example, if your source data uses the field “fname” but your entity model uses “first name,” you can map the two and then run the harmonization flow.
- Mastering: You can run this step to check for possible matches across your records and merge them based on specified criteria that you set. With Data Hub 5.0, Smart Mastering is now fully integrated and configurable within the user interface, and does not require any custom coding.
- Custom: If you are an advanced user and want full control over your data flow, you can always run a fully configurable custom code module.
Once your flows are configured and run, you can view the status of each job, when it was run and how many records were committed to the database.
Smart Mastering – A Modern Approach to MDM
The Data Hub’s Smart Mastering feature is a particularly powerful step, making it possible to do MDM right in the Data Hub.
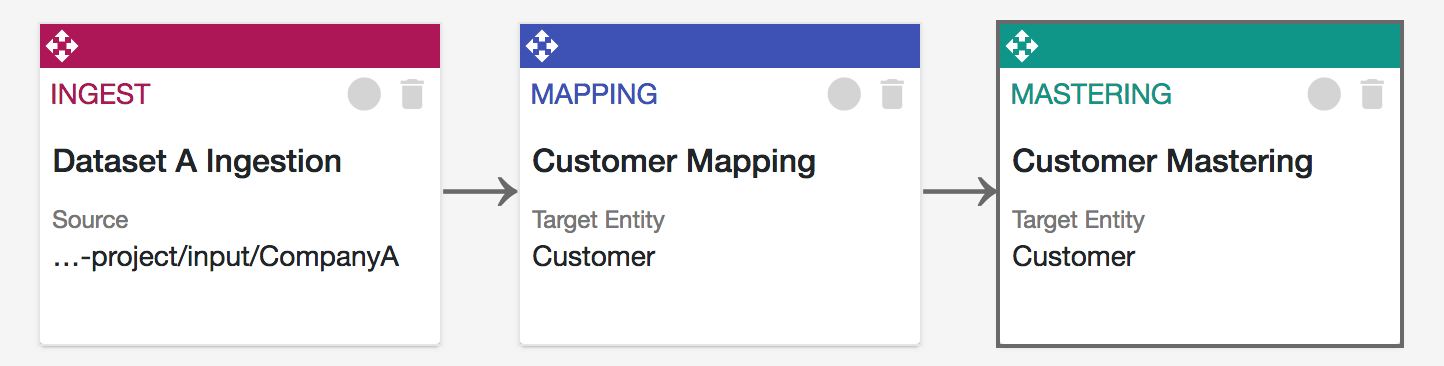
Figure 3: Smart Mastering is another step in the data flow orchestration process
The first step in creating a mastering flow is to configure the match options and thresholds.
Match options are rules that determine if two or more records match. Match thresholds specify what to do when there is a possible match. For example, exceeding a threshold could trigger an automatic merge or send a notification.
Figure 4: Match options and thresholds are easy to add and manage right within the UI
After configuring match options, the next step is to configure the merge options that define how two or more matched records are merged together.
When a merge happens, the Data Hub creates a new record. But, the process is non-destructive (unlike other MDM systems). In the Data Hub, the old records are only archived, and it is just as easy to un-merge records if you learn new information. It’s a unique feature that sets MarkLogic apart.
If you want to learn more about Smart Mastering, you can read more in this announcement from when we first launched the feature.
Improved Access with Data Services
MarkLogic’s Data Services provides a new, convenient way to integrate MarkLogic into an existing enterprise environment. A Data Service is a high-performance, secure, fixed interface over the data managed in MarkLogic, and it is expressed in terms of the consuming application.
The benefit of Data Services is to speed up development. To do this, Data Services encapsulates the details about how the data is stored and then provides access in the language of the business. In other words, Data Services separates implementation concerns from business value.
In addition to the process improvements, Data Services dramatically improves performance over traditional interfaces like REST or ODBC by minimizing communication traffic. Data Services can also be monitored and managed through the new Request Monitoring feature, giving you more control over performance and stability.
Request Monitoring Feature
Our new Request Monitoring feature enables you to configure the logging of information related to requests, including metrics collected during request execution. Developers can enable monitoring at the server, endpoint or Data Service level with granular control of what events or metrics are logged. This fine-grained control means better visibility into the working of your application without the danger of “signal overload” that is common when logging is overused. In addition to monitoring and capturing metrics, developers can also cancel requests that could be impacting the user experience or your SLAs.
More Connectors – MuleSoft and Power BI
Of course when you build a data hub, you need to get data into and out of it. In addition to the capabilities I’ve already mentioned, we also announced both the MarkLogic Connector for MuleSoft (for data ingestion) and the MarkLogic Connector for Power BI (for data access and analytics).
As the name “Data Hub” implies, it’s a “Hub” that is usually at the center of larger enterprise architecture that includes specialized tools. For that reason, we built the Hub to seamlessly integrate into larger architectures by relying on industry standards and building connectors to popular industry tools.
MarkLogic Connector for MuleSoft
We recently announced our technology partnership with MuleSoft. The first step in this partnership is the MarkLogic Connector for MuleSoft, certified by MuleSoft.
MuleSoft’s Anypoint Platform is a leading solution for API-led connectivity that creates an application network of apps, data and devices, both on-premises and in the cloud. Our connector allows MarkLogic customers to leverage the rich ecosystem of Anypoint connectors for ingesting data from many sources into a MarkLogic Data Hub.
If you’re a developer and want to try out the MarkLogic Connector for MuleSoft, it’s open source and available on GitHub.
MarkLogic Connector for Power BI
Power BI is Microsoft’s leading business intelligence tool and has been recognized as a leader in the Gartner Magic Quadrant for Analytics and Business Intelligence for 12 consecutive years.
We’re proud to announce the upcoming availability of a new MarkLogic Connector for Power BI. By leveraging Power BI’s DirectQuery capability, our connector will provide a live connection to access, analyze and even update data managed in a MarkLogic Data Hub by pushing SQL queries right to the database. MarkLogic will be the first of any multi-model or document database to use DirectQuery.
The MarkLogic Connector for Power BI highlights our partnership with Microsoft, our commitment to supporting the community of enterprise developers and business analysts that love SQL and Power BI and our commitment to innovations that help solve complex data challenges.
What’s Next
As you can see, we’ve launched a ton of new capabilities in every area of the MarkLogic Data Hub Platform:
- Embedded machine learning
- Improved security:
- More granular roles
- Automatic provenance tracking
- SAML 2.0
- New option for third-party KMS
- Easier curation
- More connections:
- Connector for MuleSoft
- Connector for Power BI
And, those are just the highlights.
Head to our newly relaunched developer site where you can sign up for our newsletter to get the latest from MarkLogic for the upcoming availability of all these features. Or, go directly to our Data Hub release notes for more technical details.

