
【ご連絡】
既に「Data Hub QuickStart チュートリアル – ビジネス課題の解決から考えるデータ統合の進め方 <前編>」を実施されている方は、本チュートリアルを進める前に下記を実行して再度データの取り込みをお願いいたします。前回のサンプルデータに一部問題があったため修正しております。
※ 1. QuickStartメニューのDashboardをクリックし、Databasesの横のドクロマークをクリック。”Do you really want to remove all files from all of your Data Hub Databases?”と出てくるのでCLEAR!をクリックし、データを全部削除する
※ 2. inputに配置しているcsvファイルを新しい値で上書きする
※ 3. ingestステップを再度実行する
前回の記事に続き、本記事でもMarkLogicデータハブフレームワークを利用してどのようにしてデータ統合を素早く柔軟性を持って実施するかをご紹介します。
- データハブフレームワークの利用方法については必要に応じて下記ドキュメントもご参照ください。 *2020.3月日本語版5.1ページの公開・リンク差し替え
日本語版:https://developer.marklogic.com/learn/data-hub-quickstart-jp/
英語版:https://docs.marklogic.com/datahub/
前回の記事までで、異なる2つのデータソースからの顧客情報をAs-Isで取り込むことが出来たと思います。
今回の記事では、取り込んだデータをエンティティ(実際のビジネスで利用するデータモデル)にハーモナイズする方法と、同一顧客を特定するマスタリングについて説明をしていきます。
エンティティの作成
まずはじめに、アウトプットの形式(ビジネス・エンティティ)を定義します。
今回のビジネス課題としては、下記がありました。
・顧客情報を取得する際に2つのシステムを検索しなければならない
・顧客情報のフォーマットが異なるため、同一条件でのデータ検索が難しい(例:項目名が違う、データの書式(電話番号や日付など)が違うなど)
・検索して出てきた顧客が同一人物かどうかを手作業で判断しなければいけない
そのため、今回は顧客が同一人物かどうかを判断できることを目的にエンティティを検討します。今回は下記の項目から構成されるエンティティを定義しました。
・氏名(漢字)
・氏名(かな)
・住所
・電話番号
・誕生日
それではこのエンティティをDHF上で実装していきます。
- QuickStartメニューから”Entities”を選択し、左上のレンチアイコンをクリックするとメニューが開くので、”NEW ENTITY”をクリックします。
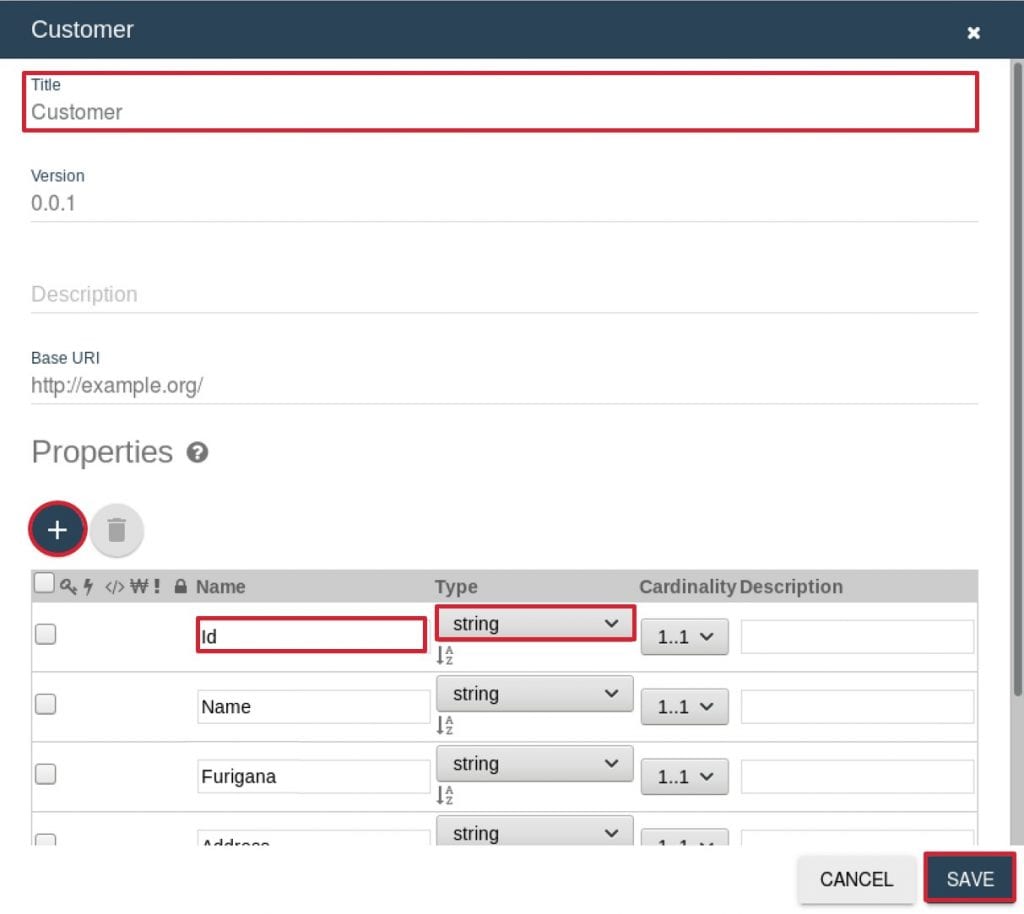
- エンティティの作成画面が出ますので、下記の通り入力し”SAVE”をクリックします。
Title: Customer
Properties: +アイコンをクリックするとプロパティを追加できるので、下記プロパティを作成するName Type Id string NameKanji string NameKana string Address string Telephone string DoB date
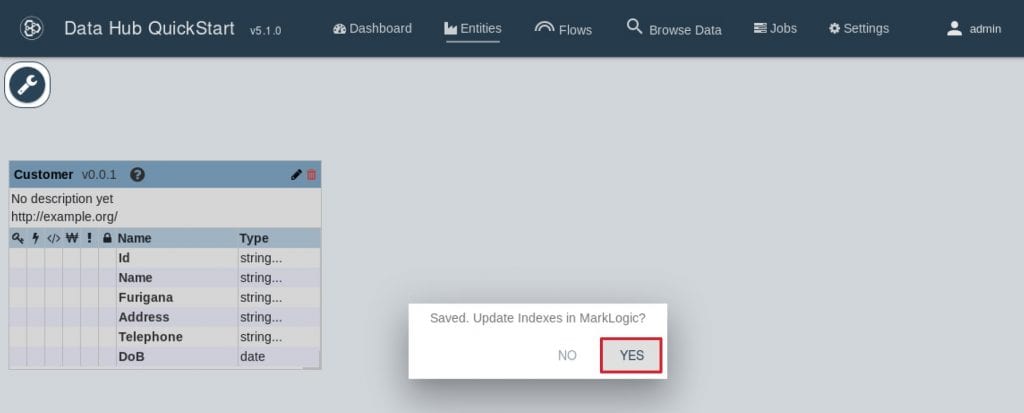
3. すると、MarkLogicのインデックスを更新するか聞かれますので、”Yes”をクリックします。
以上でCustomerエンティティが作成されました。次はAs-Isで取り込んだCustomer1とCustomer2のデータをこのエンティティにマッピングしていきます。
4. QuickStartメニューから”Flow”を選択し、先程作成したCustomer1フローを選択します。
 5. “NEW STEP” をクリックします。Stepの作成画面では下記の通り情報を入力し、”SAVE”をクリックします。
5. “NEW STEP” をクリックします。Stepの作成画面では下記の通り情報を入力し、”SAVE”をクリックします。
Step Type: Mapping
Name: MappingCustomer1
Source Type: Collection
Source Collection: IngestCustomer1
Target Entity: Customer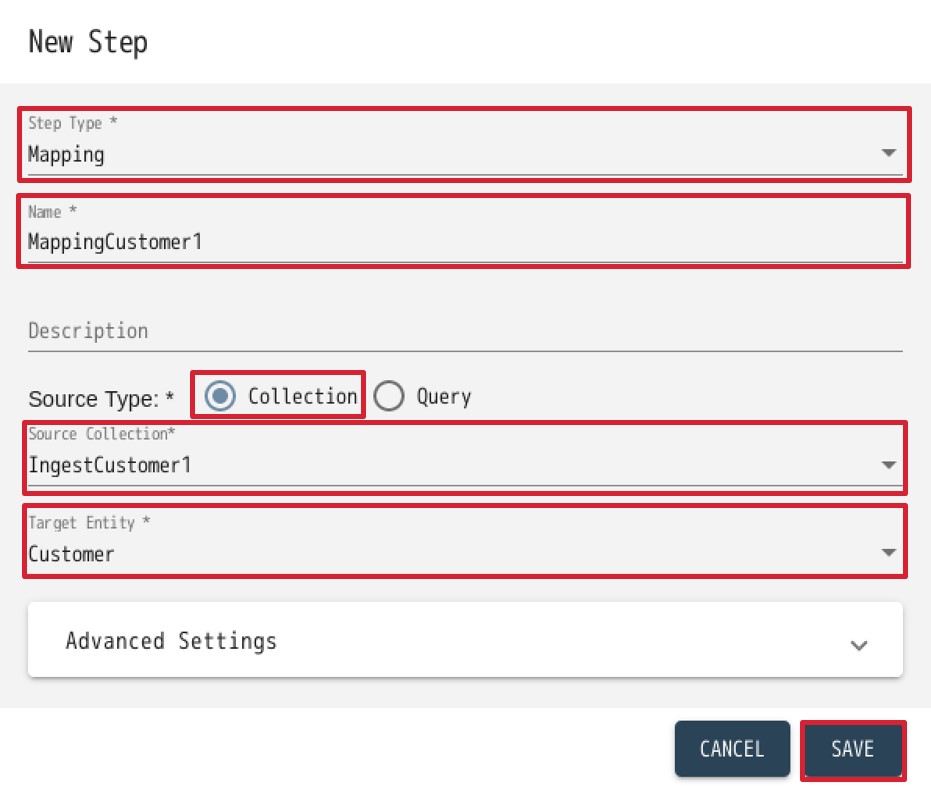 6. 新しく作成されたMappingCustomer1をクリックすると、下記のような画面が表示されます。ここで、取り込んだデータとエンティティのマッピングを定義していきます。
6. 新しく作成されたMappingCustomer1をクリックすると、下記のような画面が表示されます。ここで、取り込んだデータとエンティティのマッピングを定義していきます。
その際、標準で用意されている関数を利用してデータの変換を行うことが可能です。
(”f(x)”アイコンをクリックすることで、利用可能な関数の一覧を見ることが出来ますし、こちらのドキュメントにも記載があります。)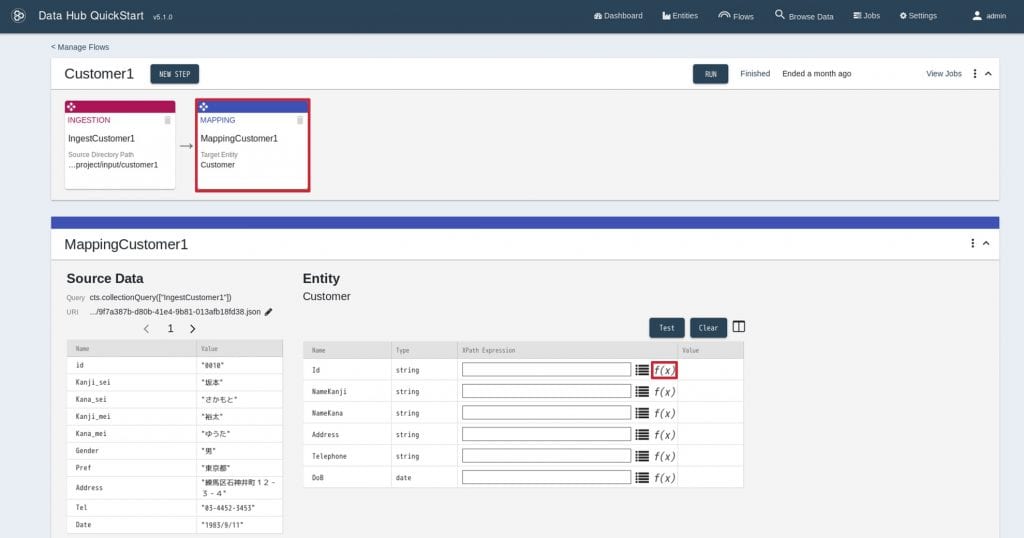 7. 標準で用意されている関数以外にも、自分でカスタム関数を定義することも可能です。
7. 標準で用意されている関数以外にも、自分でカスタム関数を定義することも可能です。
今回のチュートリアルでは下記2つのカスタム関数を作成します。
- カタカナをひらがなに変換する関数(読み仮名用)
- 日付の形式を変換する関数(誕生日用)
8. カスタム関数の定義はJavaScript script(.sjs)やmodule(.mjs)、XQuery scrupt(.xqy)などで定義されます。
またそれらのファイルは [project-root]/src/main/ml-modules/root/custom-modules/mapping-functions ディレクトリに格納されている必要があります。
今回は下記のようなsjsファイルを作成します。
ファイル名: [project-root]/src/main/ml-modules/root/custom-modules/mapping-functions/customFunctions.sjs
コード:
function katakanaToHiragana(text){
text = ”+ text
return text.replace(/[u30a1-u30f6]/g, function(match) {
var chr = match.charCodeAt(0) – 0x60;
return String.fromCharCode(chr);
});
}
function tutorialParseDate(val) {
val = ”+ val;
let dateArgs = val.split(/-|//);
let year = dateArgs[0];
let month = dateArgs[1].length == 1 ? “0” + dateArgs[1] : dateArgs[1];
let day = dateArgs[2].length == 1 ? “0” + dateArgs[2] : dateArgs[2];
return year + “-” + month + “-” + day;
}
module.exports = {
katakanaToHiragana,tutorialParseDate
}
9. 次にこのsjsファイルをデプロイします。Project Rootで ./gradlew mlLoadModules を実行します。(Windowsの場合はbat)
※もし下記のようなエラーが出る場合、プロジェクトディレクトリ直下のgradle.propertiesの16-18行目に記載されているmlUsername/mlPasswordに適切な値をセットしてください。
例)
16行目 # Your MarkLogic Username and Password
17行目 mlUsername=admin
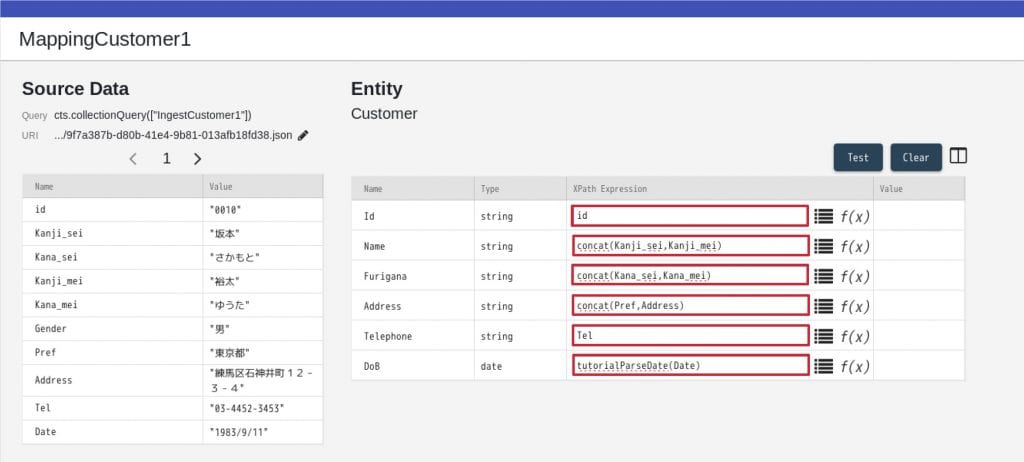
18行目 mlPassword=admin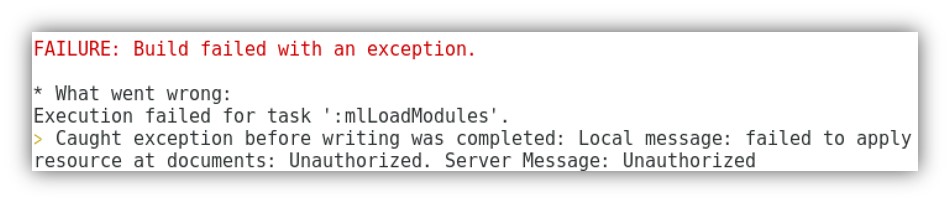 10. 以上でカスタム関数を利用できるようになりましたので、早速マッピングを行っていきます。下記のとおりに設定を行います。
10. 以上でカスタム関数を利用できるようになりましたので、早速マッピングを行っていきます。下記のとおりに設定を行います。
- Id: id
- Name: concat(Kanji_sei,Kanji_mei)
- Furigana: concat(Kana_sei,Kana_mei)
- Address: concat(Pref,Address)
- Telephone: Tel
- DoB: tutorialParseDate(Date)
11. Testボタンを押して、結果が想定どおりであることを確認します。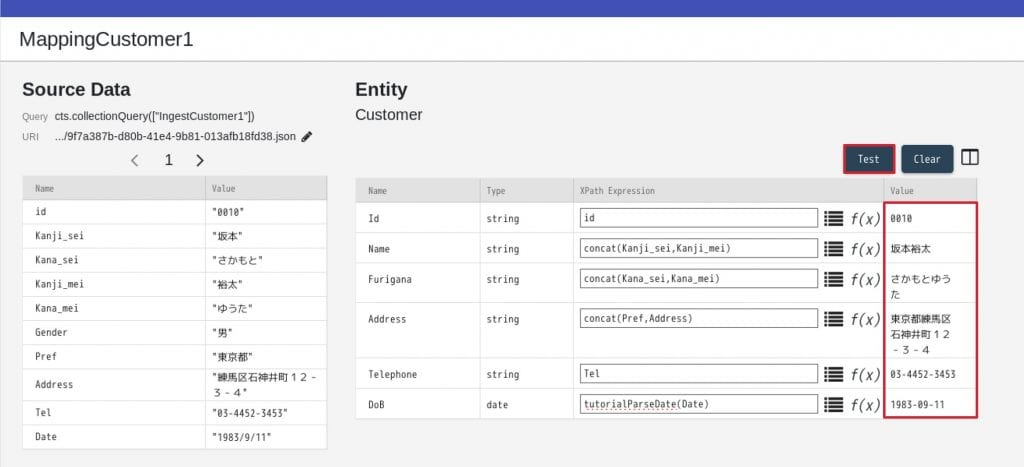 12. 問題なければ画面上部の”RUN”をクリックし、Run Flowを開きます。MappingCustomer1だけにチェックを入れ、”RUN”をクリックします。
12. 問題なければ画面上部の”RUN”をクリックし、Run Flowを開きます。MappingCustomer1だけにチェックを入れ、”RUN”をクリックします。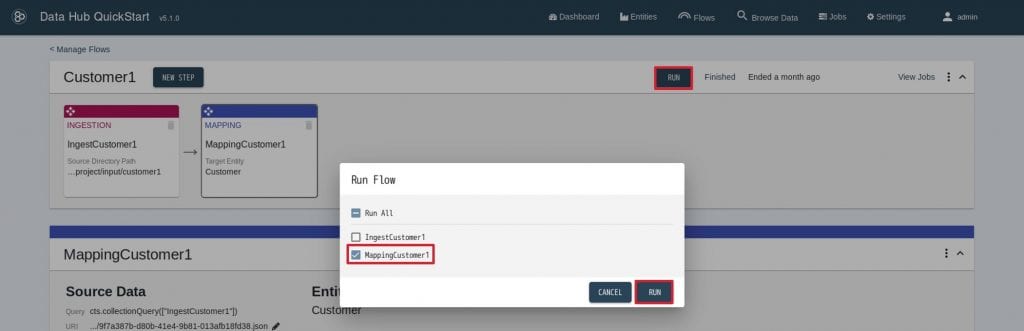 13.ステップの実行が終わったら、結果を確認します。QuickStartメニューから“Browse Data”をクリックします。
13.ステップの実行が終わったら、結果を確認します。QuickStartメニューから“Browse Data”をクリックします。
対象データベースをFINALにし、左のファセットで “Collection:MappingCustomer1”に絞ります。適当なドキュメントをクリックして詳細を確認します。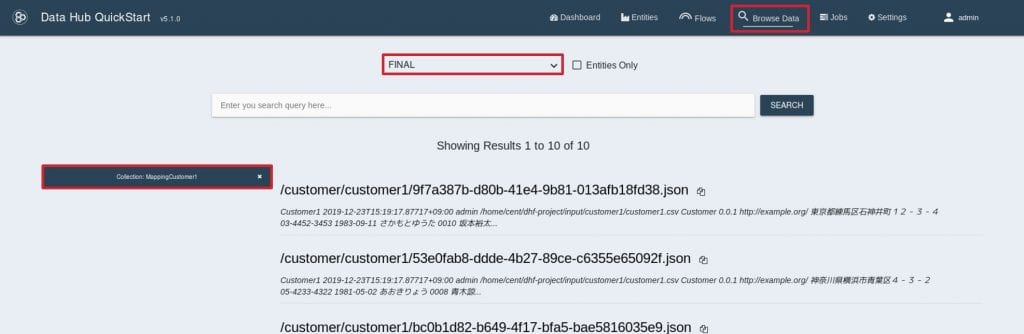 14. すると下記のようなドキュメントが表示されると思います。As-Isのデータからエンティティが生成されていることが確認できます。
14. すると下記のようなドキュメントが表示されると思います。As-Isのデータからエンティティが生成されていることが確認できます。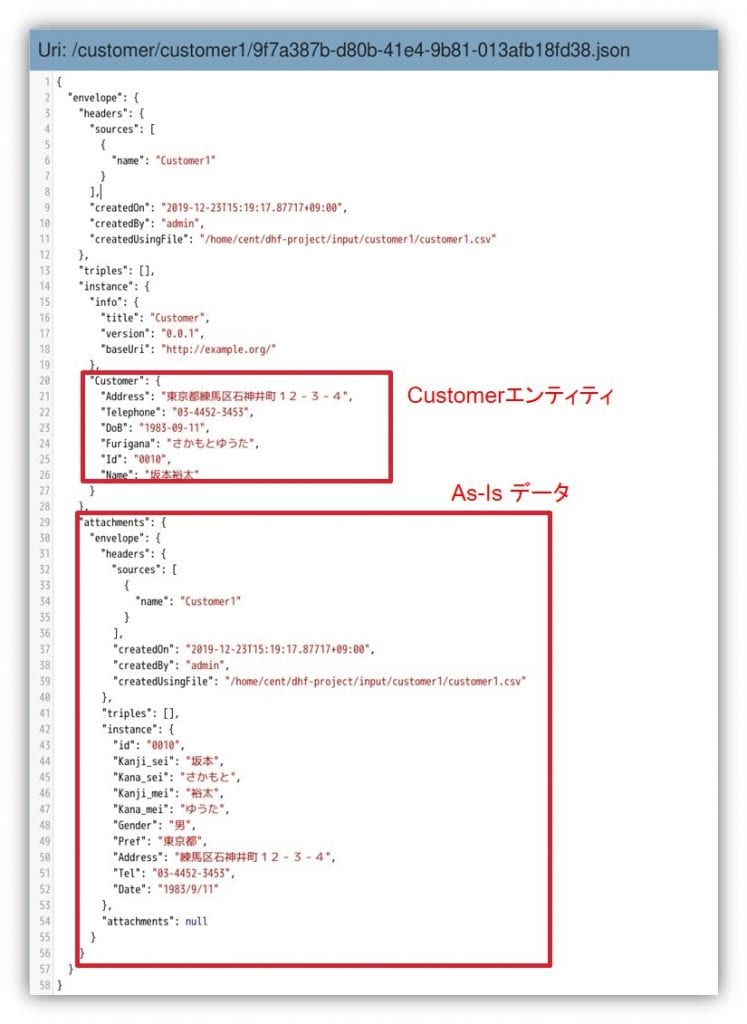 15. 同様にして、Customer2もマッピングを行います。先程と同様に、QuickStartメニューの”Flows”をクリックし、Customer2フローを選択します。
15. 同様にして、Customer2もマッピングを行います。先程と同様に、QuickStartメニューの”Flows”をクリックし、Customer2フローを選択します。
”NEW STEP”をクリックし、下記の通り設定を行い”SAVE”をクリックします。
- Step Type: Mapping
- Name: MappingCustomer2
- Source Type: Collection
- Source Collection: IngestCustomer2
- Target Entity: Customer
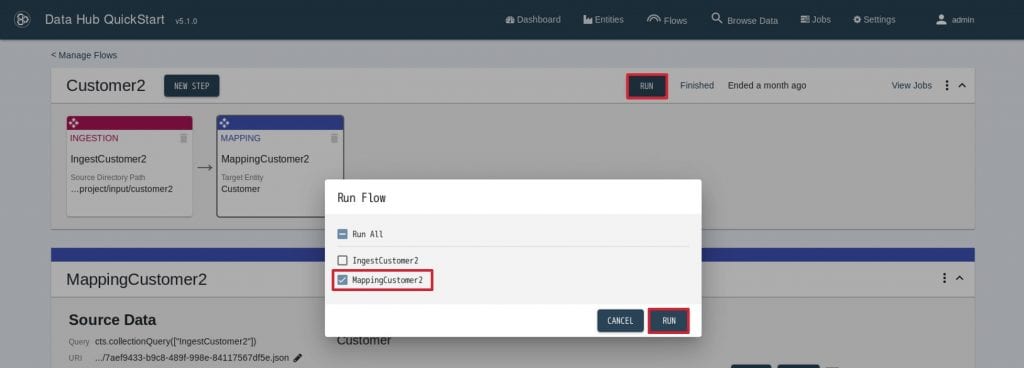
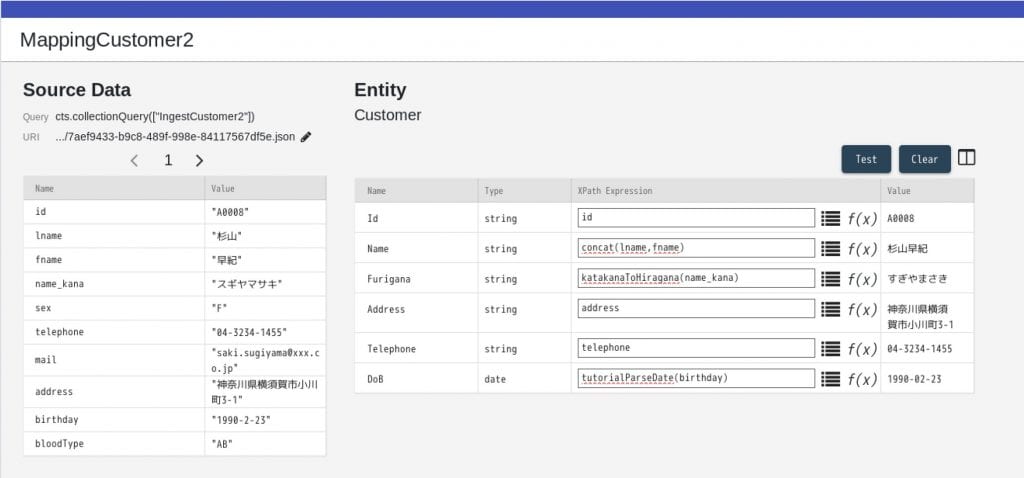
16. マッピング表を下記のとおりに定義します。
- Id: id
- Name: concat(lname,fname)
- Furigana: katakanaToHiragana(name_kana)
- Address: address
- Telephone: telephone
- DoB: tutorialParseDate(birthday)
17. MappingCustomer2だけ選択し、”RUN”をクリックします。18. マッピングの結果を確認します。
Customer2も正しくマッピングされており、Customerコレクションが20件に増えていることが確認できます。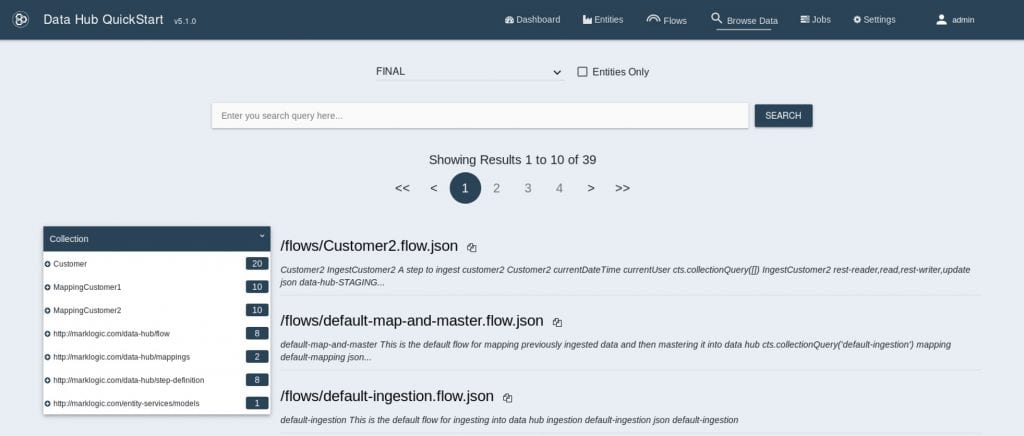
以上で、異なる2つのデータを一つの共通のエンティティにマッピング出来ました。
ただし、実際のアプリケーションで使うにはこれだけでは不十分です。
前提にあったとおり、現状では検索して出てきた顧客が同一人物かどうかを手作業で判断しなければいけないという課題がありました。
これを解決するために、Masteringの機能を利用して、同一人物かどうかの判定を自動的に行うようにします。
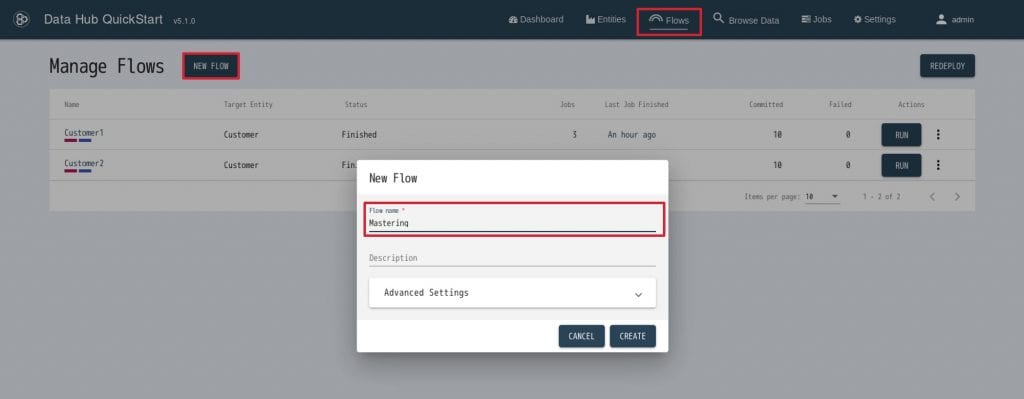
19. QuickStartメニューの”Flows”をクリックします。画面左上の”NEW FLOW”をクリックし、下記の通り設定を行ったら”CREATE”をクリックします。
- Flow name: Mastering
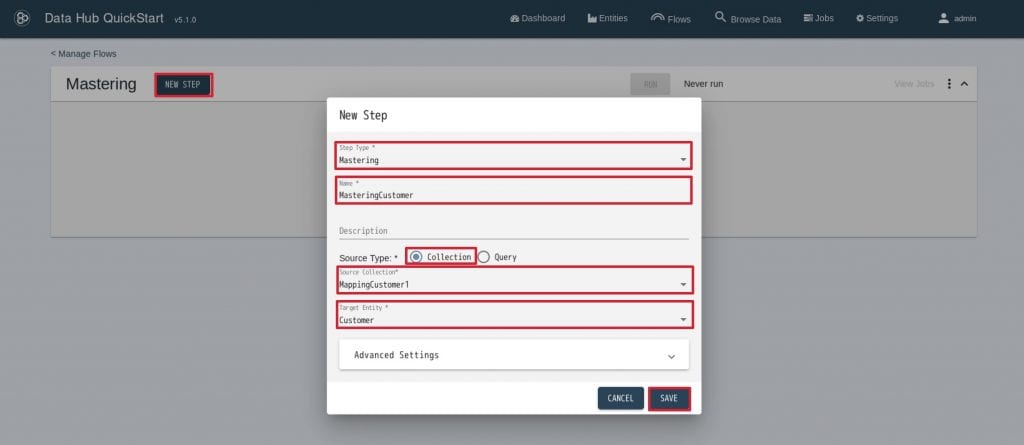
20. 作成したMasteringフローをクリックします。NEW STEPをクリックし、下記の通り設定を行い”SAVE”をクリックします。
- Step Type: Mastering
- Name: MasteringCustomer
- Source Type: Collection
- Source Collection: MappingCustomer1
- Target Entity: Customer
21. Mastering Stepが作成されます。Mastering Stepは「Matching」と「Merging」という2つの要素から構成されます。
Matchingは各ドキュメントを比較する際の条件を定義しており、Mergingは一致したドキュメントをどのようにマージするかを定義しています。
詳細についてはこちらのドキュメントを参照してください。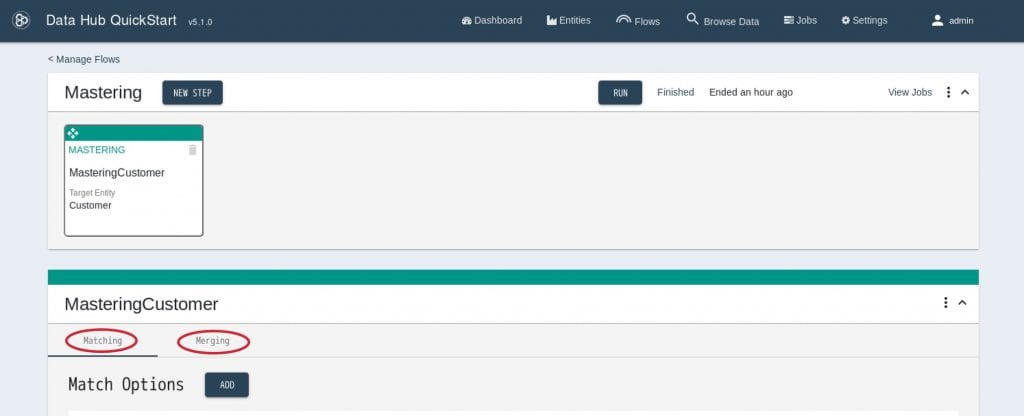 22. まずはMatchingから設定を行います。まずMatch Optionsを設定します。
22. まずはMatchingから設定を行います。まずMatch Optionsを設定します。
ここでは、エンティティがマッチしているかどうかを判断する条件を設定します。各設定の内容はざっくり下記のとおりとなります。
- Property to Match: マッチしているかどうかの判断に利用する項目
- Match Type: マッチの条件(完全一致か、シノニム(同義語)か、など)
- Weight: この項目がマッチしていた際の重み(スコア)
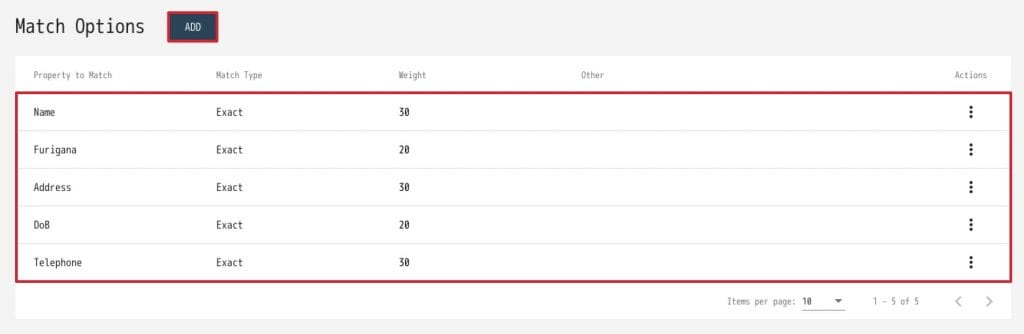
23. Match Optionsを下記の通り設定します。(ADDをクリックすることで、新規プロパティを追加できます)
| Property to Match | Match Type | Weight |
| Name | Exact | 30 |
| Furigana | Exact | 20 |
| Address | Exact | 30 |
| DoB | Exact | 20 |
| Telephone | Exact | 30 |
24. 次にMatch Thresholdsを設定します。ここでは、Match Optionsを適用した結果のスコアがいくつ以上だとどのようなアクションを行うか、といった設定をします。
今回はしきい値とアクションを下記の通りとします。
- スコアが130以上(つまり全項目が一致): 自動的にマージ
- スコアが100以上(一項目だけ異なっている):ユーザに通知を行う
下記の通り設定を行います。
| Threshold Name | Weight Threshold | Action |
| Complete | 130 | Merge |
| Partial | 100 | Notify |
25.次にMergingの設定を行います。Mergingでは、Match Thresholdで設定したMerge Actionの動作を設定します。
詳細についてはこちらのドキュメントを参照してください。
26. Merge Option では各項目をマージする際の方法を指定します。ここで指定されていない項目は、後述するDefault Strategyで定義されている方法でマージされます。
今回チュートリアルでは、Merge Optionは特に設定しません。 27. Merge Strategiesでは、マージ方法を定義します。(ここで設定したMerge StrategyはMerge Optionで呼び出されて利用されます。)
27. Merge Strategiesでは、マージ方法を定義します。(ここで設定したMerge StrategyはMerge Optionで呼び出されて利用されます。)
今回はデフォルトのMerge Strategyのみを定義します。
- Strategy: Default(Yes)
- Max Values: 2
- Max Sources: 2

28. Merge Collectionsでは、各アクションが実行されたドキュメントに付与されるコレクションを定義できます。今回はデフォルトのままにします。
29. 以上でマスタリングの設定は完了です。RUNをクリックして実際に実行してみます。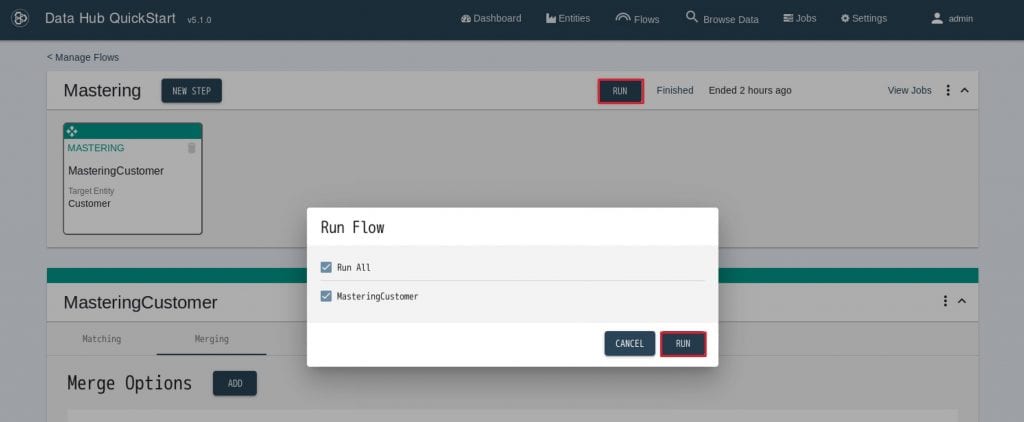 30. 完了したら、QuickStartメニューの”Brows Data”をクリックします。
30. 完了したら、QuickStartメニューの”Brows Data”をクリックします。
データベースをFINALにセットすると、Customer1のデータ10件に対して、マスタリングを実行し、そのうち1件がマージされ、1件が通知がされていることがわかります。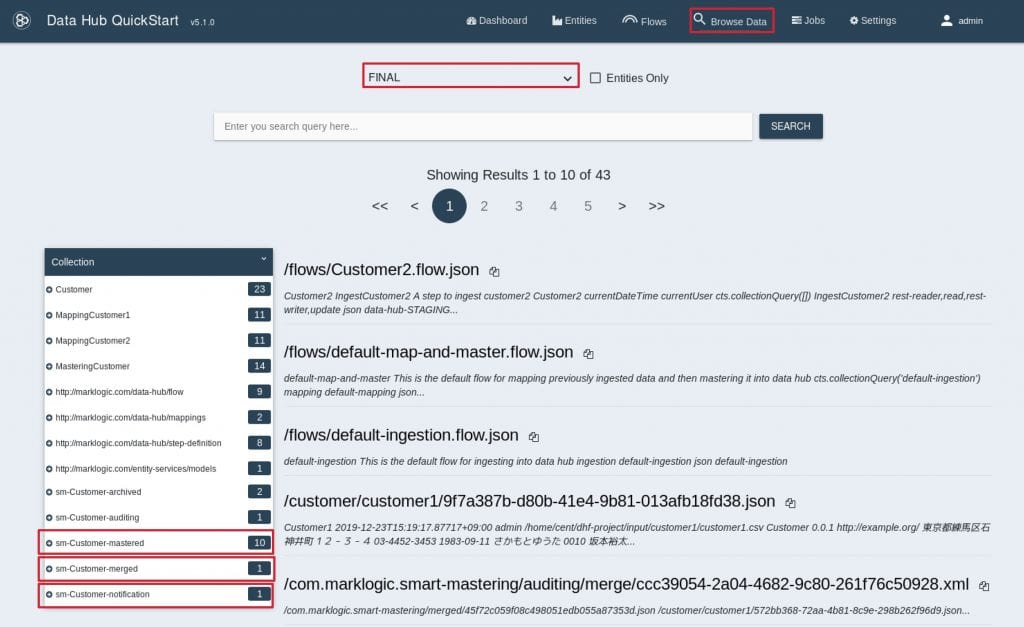 31. Collectionからsm-Customer-mergedをクリックして絞り込み、該当のドキュメントをクリックします。
31. Collectionからsm-Customer-mergedをクリックして絞り込み、該当のドキュメントをクリックします。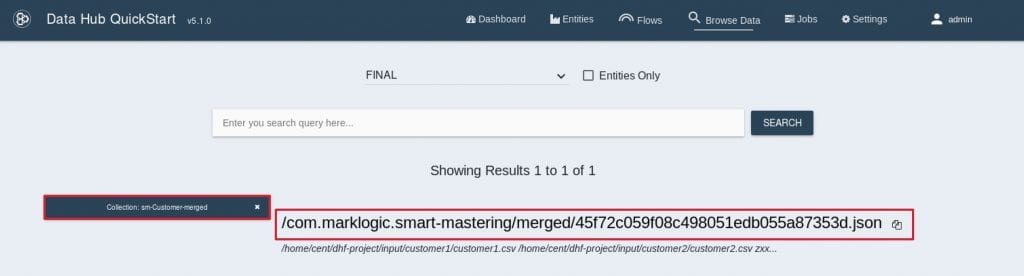 32. 全ての項目が完全一致していた佐藤美咲さんが自動的にマージされています。
32. 全ての項目が完全一致していた佐藤美咲さんが自動的にマージされています。
なお、デフォルトのMerge Strategyで設定した通り、異なる値を持っていたIDは2つの値を維持しています。
実際の運用では、エンドユーザーが必要に応じて適切なデータを選択することが可能になります。 33. 次に通知されたドキュメントを見てみます。
33. 次に通知されたドキュメントを見てみます。
QuickStartメニューの”Brows Data”をクリックし、データベースをFINALにセットし、Collectionを”sm-Customer-notification”で絞って該当データをクリックします。
すると、マッチしていると思われるドキュメントのURIが含まれていることがわかります。実際の運用では、この通知を元にユーザーが元データ同士を見比べ、手動でマージするかどうかを判断することになります。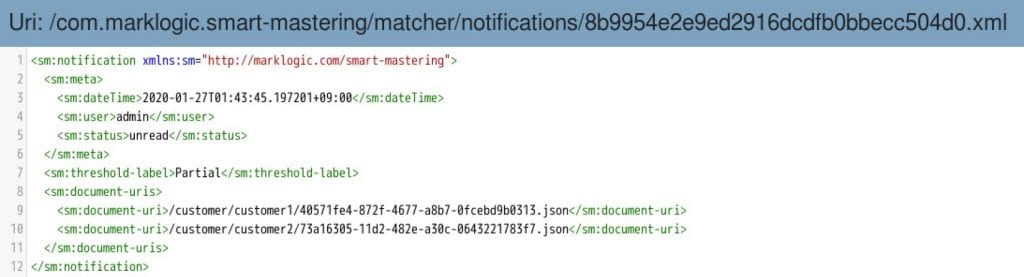
以上により、ビジネスに必要なデータを提供できるようになりました。
ここで冒頭にご説明した課題が達成できているか確認してみたいと思います。
- 顧客情報のフォーマットが異なるため、同一条件でのデータ検索が難しい
⇒共通のエンティティを定義し、マッピングを行うことで同一条件でのデータ検索が可能になりました。 - 検索して出てきた顧客が同一人物かどうかを手作業で判断しなければいけない
⇒マスタリングの機能を利用することで、同一人物を自動的にマッチングすることが可能になりました。
ここまで見てきたように、MarkLogicを利用することでデータをAs-Isで取り込める柔軟性だけではなく、データをしっかりと統合して欲しいデータを簡単に取り出すことが可能になります。
MarkLogic Data Hubを活用することで、データ取込からデータ提供までの全てのサイクルを効率的に管理することが可能になり、よりアジャイルなプロジェクトを推進することが可能になります。
是非皆様のプロジェクトでも、Data Hubを活用して頂ければと思います。
