
MarkLogic Data Hubを利用してどのようにしてデータ統合を素早く柔軟性を持って実施するかを、本記事と次回の二回に分けご紹介します。
* MarkLogic Data Hubの利用方法については必要に応じて下記ドキュメントもご参照ください。
*2020.3月日本語版5.1ページの公開・リンク差し替え及びQuick Start起動時の解説でのコマンド不具合を修正しました。
日本語版:https://developer.marklogic.com/learn/data-hub-quickstart-jp/
英語版:https://docs.marklogic.com/datahub/
チュートリアルを開始する前に、まずはData Hubを利用する際に推奨されるプロジェクトの進め方「データサービス・ファースト」について説明します。
データサービス・ファースト
「データサービス・ファースト」アプローチはMarkLogic データハブプロジェクトのデザインや構築を行う上で推奨される手法です。
データサービス・ファーストでは、まず解決したいビジネス上の課題を明らかにした上で、それを解決するためにプロジェクトを進めていくという方法を取ります。
下記の図で表現されるデータハブプラットフォームを例にして説明していきたいと思います。
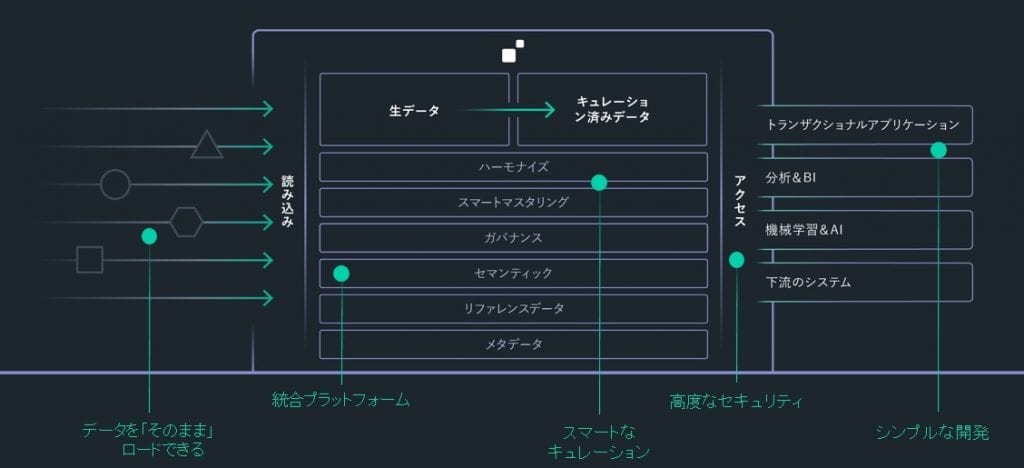
一般のデータ統合といわれるプロジェクトでは左から右にプロジェクトを進めていくと考えがちです。
データサービス・ファーストの場合は下記の様に右から検討していく必要があります。
- 解決したいビジネス課題はなにか?何がビジネスに価値をもたらすか?
- それらの課題を解決するにはどのようなデータ(ビジネス・エンティティ)が必要か?
- それらのビジネス・エンティティを作成するにはどのようなデータが必要か?
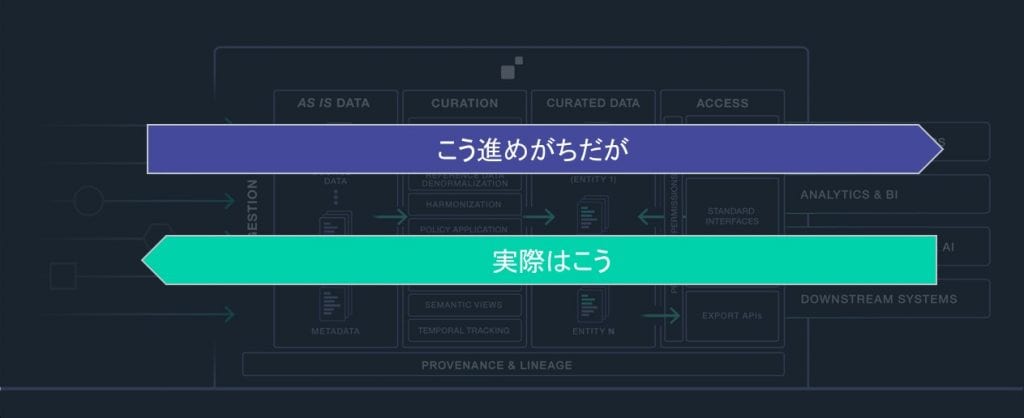
このようなアプローチを取ることで、プロジェクトがもたらすビジネス価値を必要最低限の作業工数で証明することが可能になります。
これはアジャイル開発を行う上で重要なポイントです。
それでは、この流れに沿ってまずは我々の顧客と解決するべき課題について考えていきましょう。
課題の理解
プロジェクトを効率的に進めるため、データサービス・ファーストのアプローチでは現在抱えている課題をしっかりと理解する必要があります。
また、課題が複数ある場合には、より優先度の高い課題から取り掛かります。
今回のチュートリアルでは、社内で異なる2つの顧客管理システムが運用されており、下記のような課題を抱えていると仮定します。
・顧客情報を取得する際に2つのシステムを検索しなければならない
・顧客情報のフォーマットが異なるため、同一条件でのデータ検索が難しい
(例:項目名が違う、データの書式(電話番号や日付など)が違うなど)
・検索して出てきた顧客が同一人物かどうかを手作業で判断しなければいけない
今回のチュートリアルでは、この課題をデータハブフレームワークで解決することを目指します。
MarkLogic Data Hubの概要
Data Hubは、MarkLogicサーバー上でオペレーショナル・データハブを高速に構築するためのツールやライブラリなどをセットにしたものです。
MarkLogicを利用したプロジェクトでは、このData Hubのフレームワークを利用していただくことを推奨しております。
チュートリアルの前提条件
MarkLogic Data Hub の動作要件
- Java 9 JDK (or later).
– MarkLogic Data HubはJava上で動作します - Gradle 4.6 (or later).
– MarkLogic Data Hub のデプロイタスクはGradleにより自動化されています - Chrome or Firefox.
– MarkLogic Data HubにはブラウザベースのQuickStartと呼ばれるツールがあり、今回のチュートリアルではそちらを利用します
MarkLogic関連
- MarkLogic Server 9.0-10.3 (or later).
– MarkLogic Data HubプラットフォームはMarkLogicデータベース上で動作します
– Installationガイドを参考にしてインストールを実施します - MarkLogic Data Hub 5.1 QuickStart *.war ファイル
– https://github.com/marklogic/marklogic-data-hub/releases/ から最新の*.warファイルをダウンロードします
Data Hubプロジェクトの作成
今回はQuickStartを利用して、新しいData Hubプロジェクトを作成していきます。
- まず、今回のプロジェクト用のディレクトリ “dhf-project” を作成します。
cd /home/cent
mkdir dhf-project - QuickStartを起動します。
java -jar marklogic-datahub-5.1.0.war
※ もし権限エラーなどが出るようでしたら実行ユーザーを変更してみてください - QuickStartが立ち上がると、下記のような画面が表示されます。

- ブラウザを起動し、http://localhost:8080にアクセスします。
- 最初に、プロジェクトのディレクトリを選択します。
今回は、先程作成した“dhf-project”を選択し、”NEXT”をクリックします。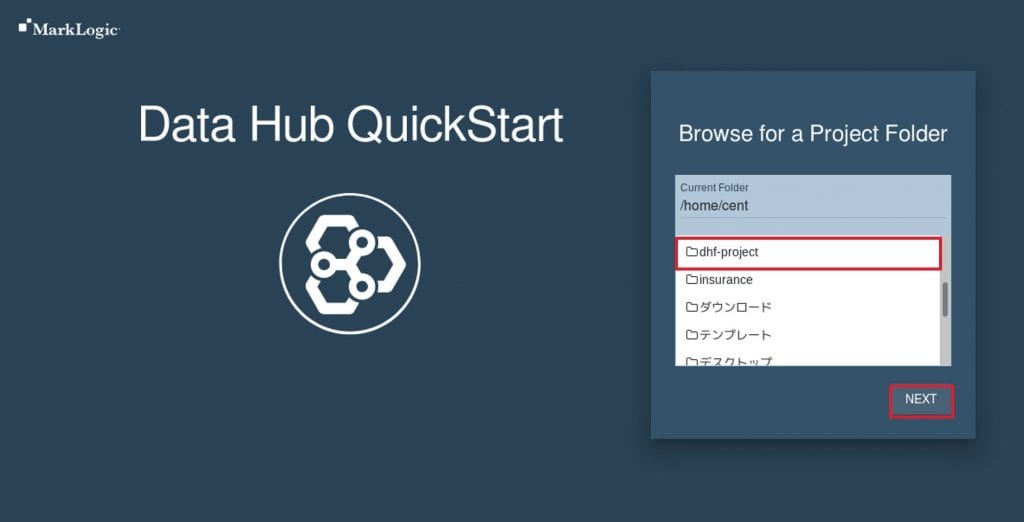
- 次にプロジェクトの初期化を行います。ここでは、デフォルトの設定で初期化を行います(ADVANCED SETTINGSを展開することで、各種設定を変更できます)。
INITIALIZEボタンをクリックし、プロジェクトの初期化を行います。 - プロジェクトの初期化では、プロジェクトに必要な設定ファイル類がファイルシステム上に作成されます。
※プロジェクトディレクトリ内に必要なファイルが生成されている

- “Next”をクリックします。

- プロジェクトの環境を選択するように求められますが、今回のチュートリアルではLocal のまま”NEXT”をクリックします。

- 適切な権限を持つユーザでログインします。
今回のチュートリアルでは管理者(admin)でログインします。
- INSTALLをクリックします。

- インストレーションではMarkLogic Data Hubに必要なリソース(HTTPサーバやデータベースなど)が作成されます。
裏ではml-gradleを利用してデプロイが自動的に行われています。
インストールが完了すると、下記のような画面が表示されます。
- FINISHEDをクリックします。
すると、下記のようなData Hub QuickStartの初期画面が表示されます。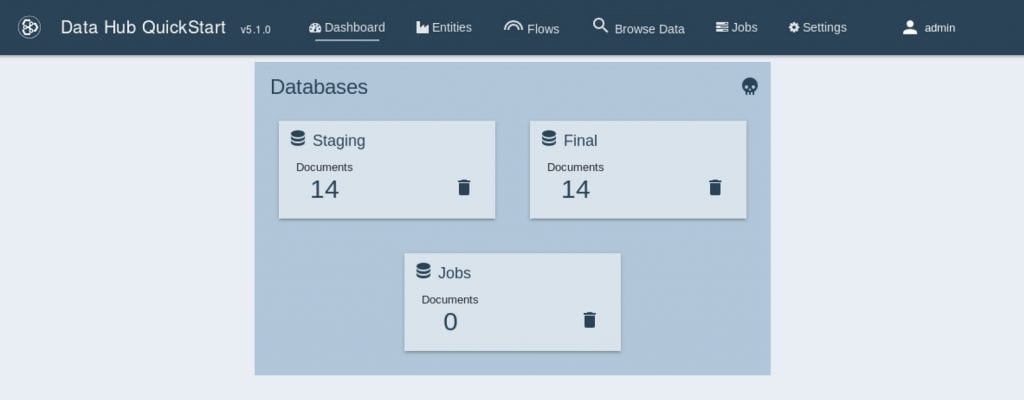
以上で、QuickStartが利用できる準備ができました。
ここで、ここまでの作業の結果を簡単に確認したいと思います。
まずは作成されたリソースを確認するため、Admin Console (http://localhost:8001)にアクセスします。
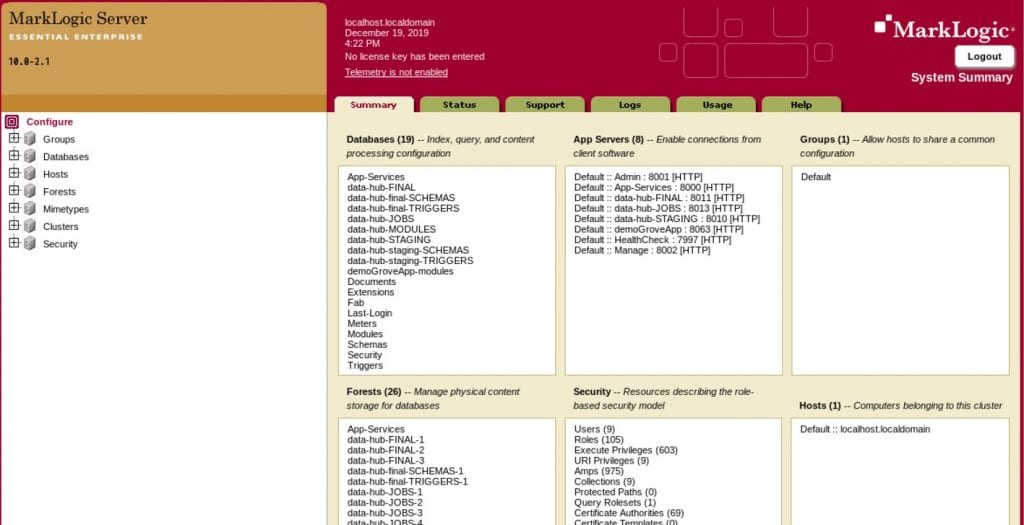 すると、data-hub-STAGINGとdata-hub-FINALという2つのデータベースと関連するデータベースが作成されていることがわかります。
すると、data-hub-STAGINGとdata-hub-FINALという2つのデータベースと関連するデータベースが作成されていることがわかります。
Data Hubでは、As-Isで取り込んだデータがステージングDBに格納され、キュレートされたデータがファイナルDBに格納されます。
それでは、早速実際にデータを取り込んでいきます。
データのインジェスト
MarkLogic Data Hubを利用することでデータの取り込みに柔軟性を持たせることができます。
RDBMSのようにデータを取り込む前のスキーマの定義やデータ加工処理などは必要ありません。
※ただし、データモデリングそのものは必要です。データモデリングについてはキュレーションの項目で詳しく説明します。
それでは早速データの取り込みを行っていきます。
まずは今回のチュートリアルで利用するサンプルデータを作成します。
Data Hubのプロジェクトディレクトリ内にディレクトリを作成します。
| cd /home/cent/dhf-project mkdir -p input/customer1 input/customer2 |
次に、下記をそれぞれ “customer1.csv” “customer2.csv”というファイル名でそれぞれ
input/customer1, input/customer2の下に保存してください。
その際、文字コードはUTF-8を指定してください。
例)Windows標準のメモ帳を利用する場合、「名前をつけて保存」→文字コードとしてUTF-8を選択し、「保存」をクリックします。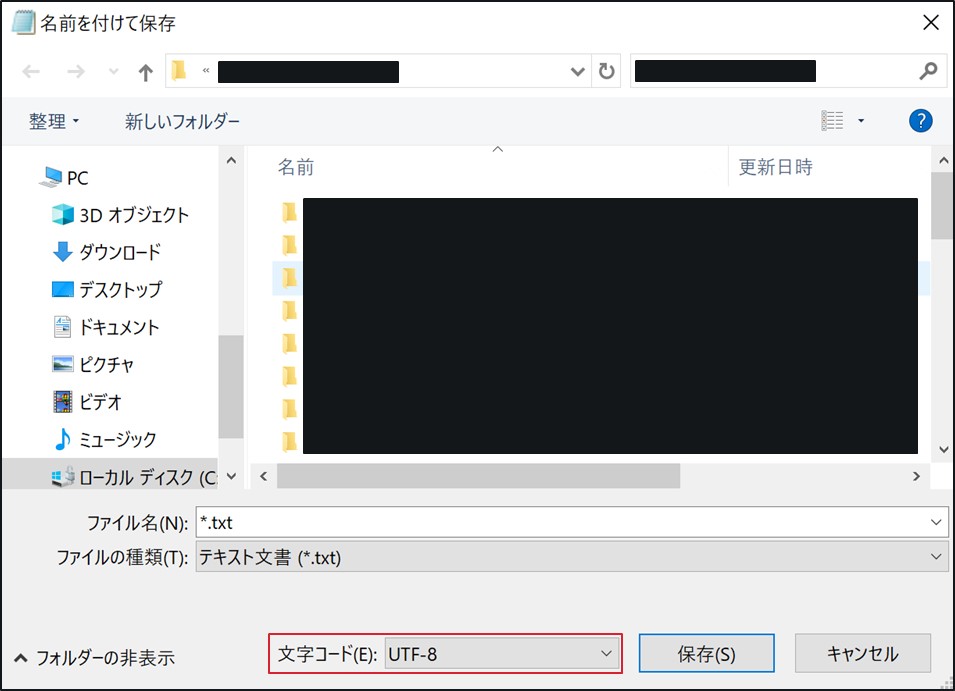 customer1.csv
customer1.csv
id,Kanji_sei,Kana_sei,Kanji_mei,Kana_mei,Gender,Pref,Address,Tel,Date
0001,田中,たなか,一郎,いちろう,男,東京都,中野区中野1ー1−1,03-1274-7834,1990/3/31
0002,鈴木,すずき,大輝 ,だいき,男,千葉県,野田市清水33-1,03-2421-3416,1995/1/20
0003,佐藤,さとう,美咲,みさき,女,東京都,世田谷区北沢3-2-4,03-5621-3663,1997/6/5
0004,伊藤,いとう,健太,けんた,男,神奈川県,川崎市高津区5-3-2,07-3421-3456,1969/6/27
0005,吉田,よしだ,遥,はるか,女,東京都,渋谷区神宮前6-12-9,03-4563-2345,1964/4/14
0006,松本,まつもと,杏奈,あんな,女,東京都,千代田区丸の内3-2-1,03-5675-3466,1995/7/22
0007,清水,しみず,彩香,あやか,女,千葉県,柏市柏43-3-1,07-2324-5621,1974/7/2
0008,青木,あおき,諒,りょう,男,神奈川県,横浜市青葉区4-3-2,05-4233-4322,1981/5/2
0009,中野,なかの,達也,たつや,男,東京都,足立区千住12-4-3,03-5343-4356,1982/8/25
0010,坂本,さかもと,裕太,ゆうた,男,東京都,練馬区石神井町12-3-4,03-4452-3453,1983/9/11
customer2.csv
id,lname,fname,name_kana,sex,telephone,mail,address,birthday,bloodType
A0001,岡島,直人,オカジマナオト,M,03-9912-4519,naoto.okajima@xxx.co.jp,東京都八王子市大塚359,1973-10-8,A
A0002,下山,拓哉,シモヤマタクヤ,M,03-4566-4221,takuya.shimoyama@xxx.co.jp,東京都千代田区大手町2-6-7,1999-4-23,B
A0003,佐藤,美咲,サトウミサキ,F,03-5621-3663,misaki.sato@xxx.co.jp,東京都世田谷区北沢3-2-4,1997-6-5,AB
A0004,村上,愛,ムラカミアイ,F,03-1231-6532,ai.murakami@xxx.co.jp,神奈川県横浜市磯子区磯子3-5-1,1996-9-26,O
A0005,上田,大輝,ウエダダイキ,M,05-2356-6254,daiki.ueda@xxx.co.jp,千葉県中央区中央2-1-3,1979-5-21,B
A0006,森,萌,モリモエ,F,03-5662-1473,moe.mori@xxx.co.jp,東京都青梅市今井3-2-2,2000-11-3,A
A0007,新井,千尋,アライチヒロ,F,03-1454-7754,chihiro.arai@xxx.co.jp,東京都文京区小石川2-1-33,1980-9-2,B
A0008,杉山,早紀,スギヤマサキ,F,04-3234-1455,saki.sugiyama@xxx.co.jp,神奈川県横須賀市小川町3-1,1990-2-23,AB
A0009,中野,達也,ナカノタツヤ,M,03-5343-4356,tatsuya.nakano@xxx.co.jp,東京都練馬区石神井町12-3-4,1982-8-25,A
A0010,梅津,彩花,ウメヅアヤカ,F,03-2166-4455,ayaka.umedu@xxx.co.jp,千葉県我孫子市日の出11,1993-10-2,O
これで取り込むサンプルデータの準備ができましたので、次にデータの取り込みを定義していきます。
Data Hubでは、データの取り込みを行うためにFlowとStepというものを設定します。
Stepが一つの処理を表す単位(例:データ取り込み、など)で、複数のStepからFlowが構成されます。
- Data Hub QuickStartから”Flows”を選択します。
 2. 次に”NEW FLOW”をクリックします。
2. 次に”NEW FLOW”をクリックします。 3. Flowの作成画面が出てきますので、下記の通り設定し、”CREATE”をクリックします。
3. Flowの作成画面が出てきますので、下記の通り設定し、”CREATE”をクリックします。
・ Flow name: Customer1
・ Description: A flow to ingest and map Customer1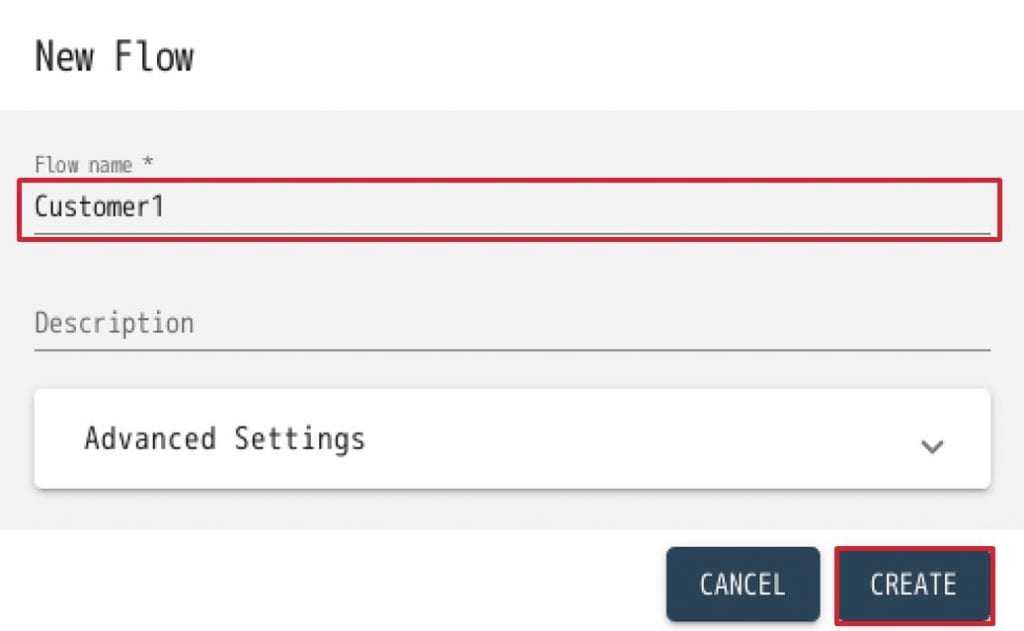 4. すると、Customer1というフローができます。
4. すると、Customer1というフローができます。
次に、新しく作成したCustomer1の名前をクリックします。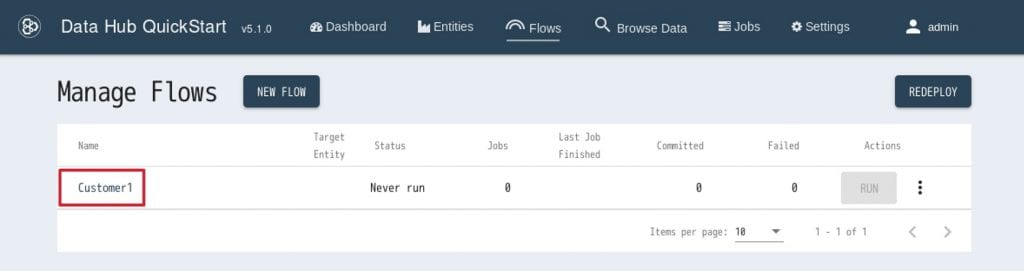 5. そうすると、Customer1フローが開きます新しいStepを作成するため、”NEW STEP”というボタンをクリックします。
5. そうすると、Customer1フローが開きます新しいStepを作成するため、”NEW STEP”というボタンをクリックします。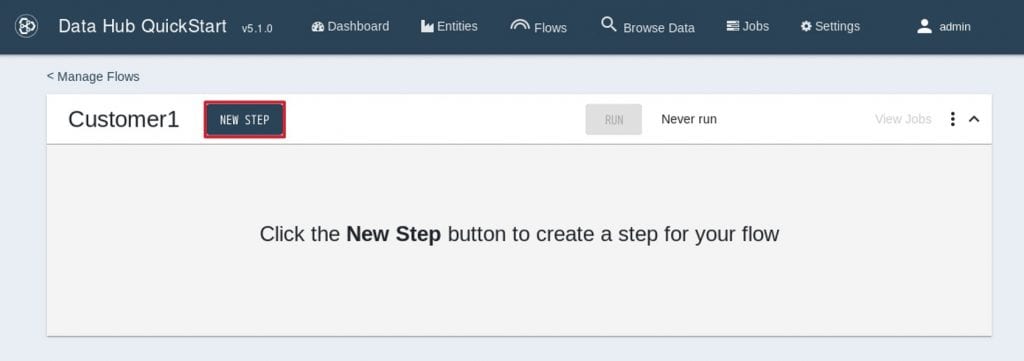 6. Stepの作成画面が出てきますので、下記の通り設定して”SAVE”をクリックします。
6. Stepの作成画面が出てきますので、下記の通り設定して”SAVE”をクリックします。
- Step Type: Ingestion
- Name: IngestCustomer1
- Description: A step to ingest Customer1
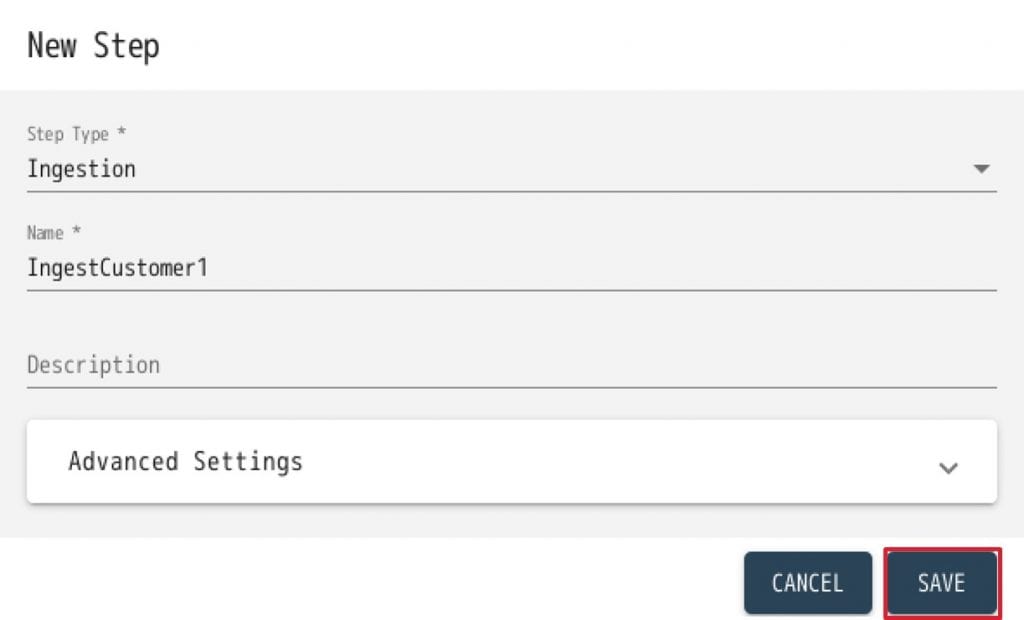
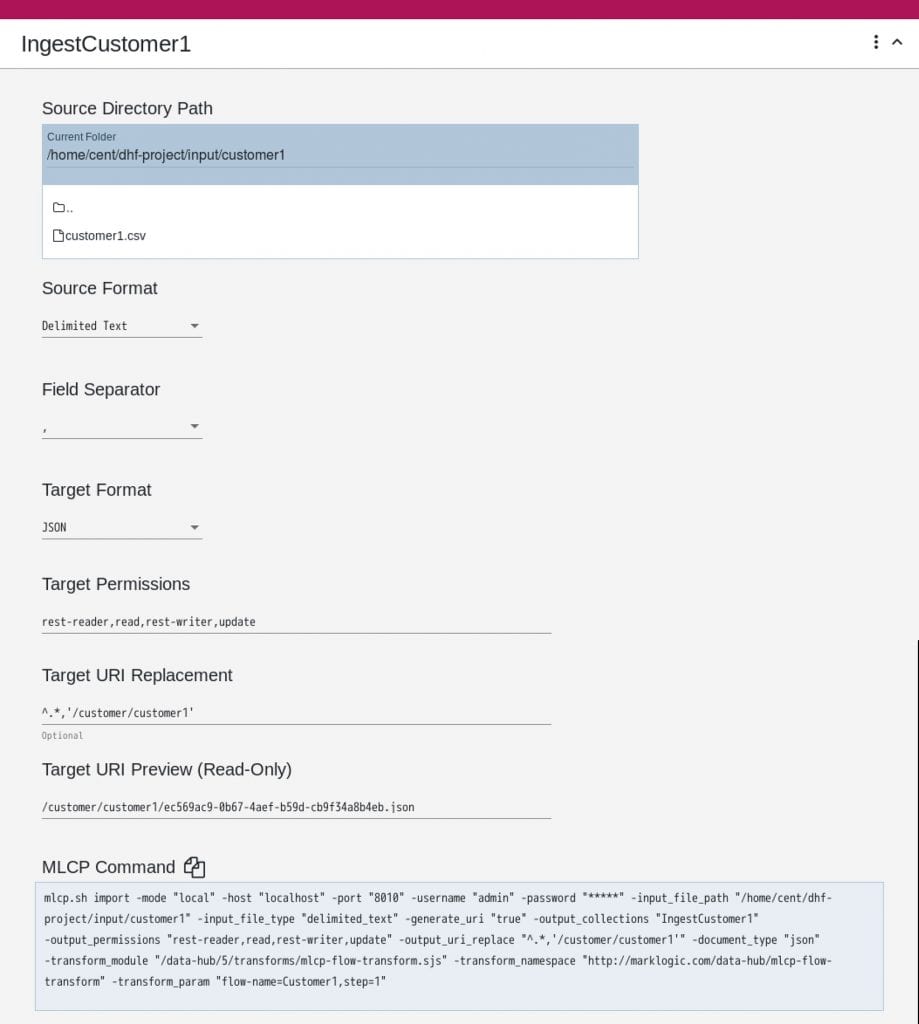
7. IngestCustomer1というStepが作成されますので、下記の通り設定します。
※ Stepの設定項目はオートセーブされます
- Source Directory Path: /home/cent/dhf-project/input/customer1
※実際のパスに合わせて修正してください - Source Format: Delimited Text
- Field Separator: ,(コンマ)
- Target Format: JSON
- Target Permissions: (変更しない)
- Target URI Replacement: ^.*,’/customer/customer1′
- URIはデータベース内のドキュメントを一意に特定するためのキーです
- デフォルトでは、ディレクトリのパスがそのままURIになってしまい視認性が悪くなるため、今回はこのようにURIを置換します
- 設定が終わったらこのFlowを実行します。
画面上部の”RUN”をクリックします。
- Run Flowインターフェースで、今作成したStep “IngestCustomer1”にチェックが入っていることを確認して、”RUN”をクリックします。
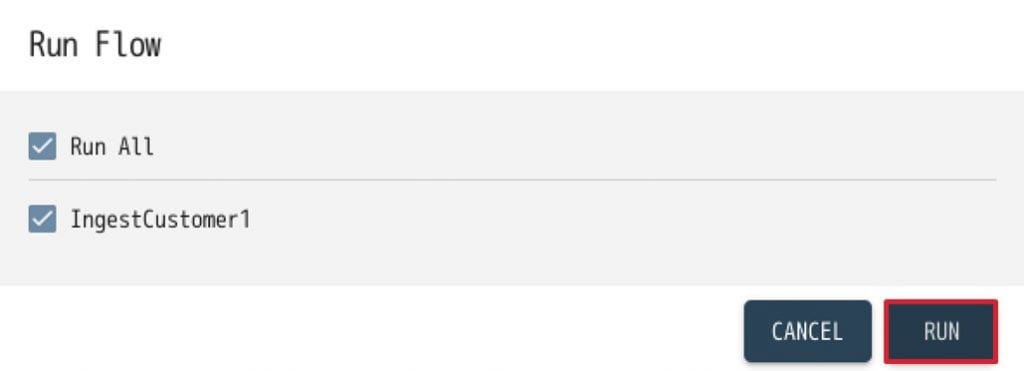
- 以上で、csvデータがMarkLogicにロードされますので、次にロードされたデータを確認します。
Stepの処理が終了したら、QuickStartメニューから”Browse Data”を選択します。
- “STAGING”データベースが選択されていることを確認します。
IngestCustomer1というコレクションのドキュメントが10件存在しています。DHFでは実行したステップの名前がドキュメントのコレクションとして付与されます。
また、元々のcsvの1つのレコードが、1つのJSONドキュメントして変換されます。
つまり、先程実行したStep “IngestCustomer1”により、10件のドキュメントが生成されたことになります。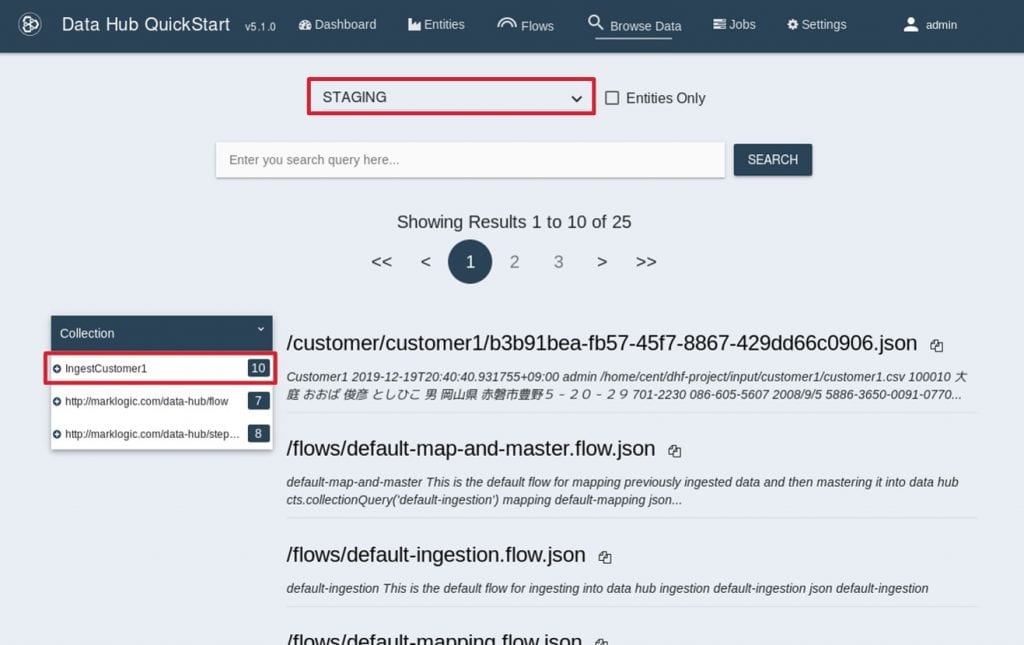
- 次に、実際に取り込まれたデータを確認するため、任意のJSONドキュメントをクリックします。
すると下記のような画面が表示されます。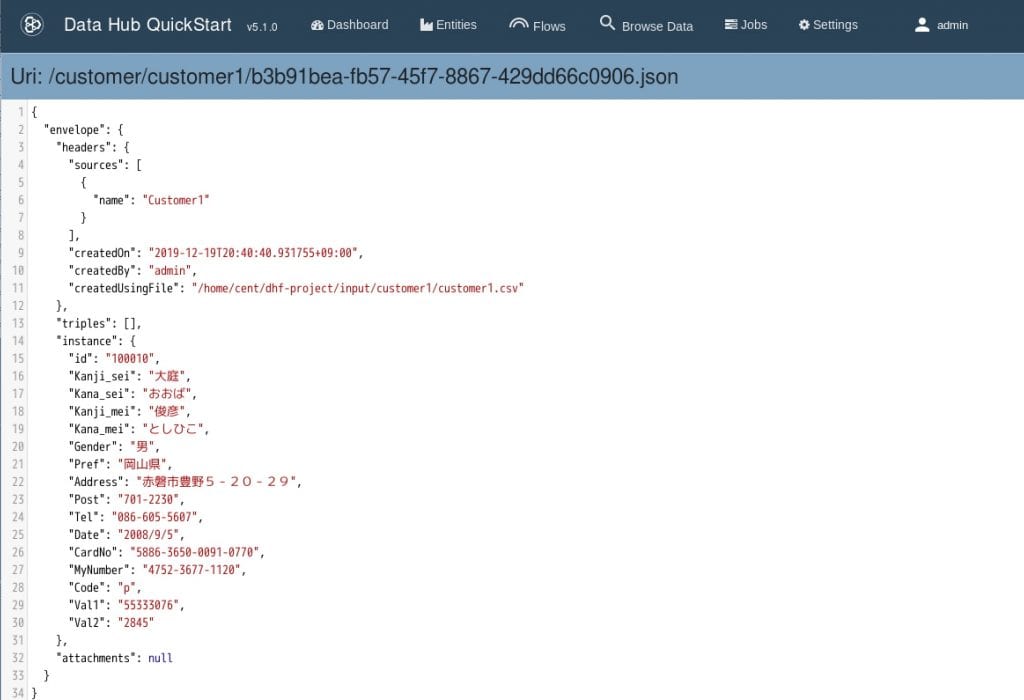
元々のカラムとその値がJSONのプロパティと対応していることがわかります。
また、データソースの名前やいつ取り込まれたかなどのデータの経歴などもヘッダの部分に保持されます。
なお、Data Hubでは、取り込まれたデータはエンベロープデザインパターンで扱われます。
エンベロープデザインパターンについて詳しく知りたい方は下記ブログを参照ください。
https://www.marklogic.com/blog/envelope-design-pattern-jp/
- 以上で、Customer1のデータをMarkLogicに取り込む事ができました。
同様にして、Customer2のデータを取り込むFlowとStepを作成していきます。 - QuickStartメニューから”Flows”を選択します。

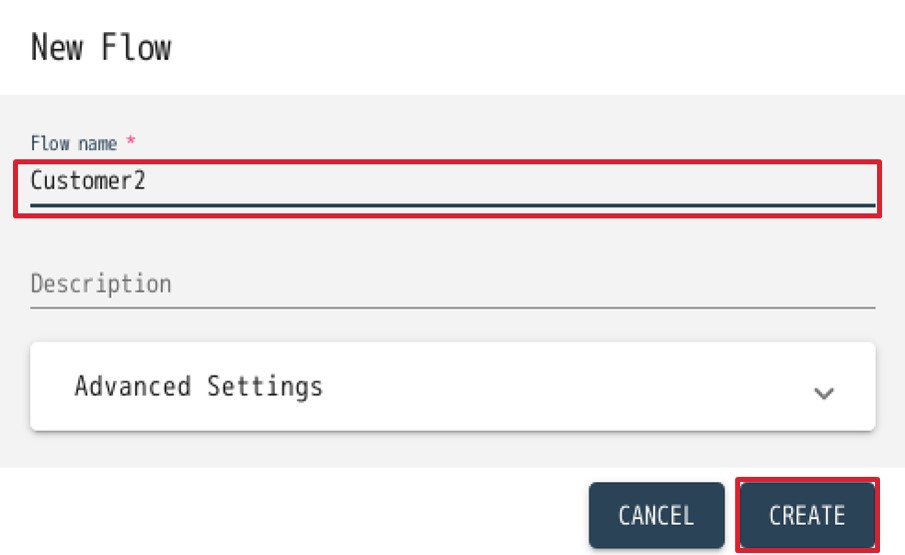
- 先程と同様に”NEW FLOW”をクリックし、下記の通り設定を行いFlowを作成します。
Flow name: Customer2
Description(任意): A flow to ingest and map Customer1
- “Customer2” FlowにIngest Stepを作成します。
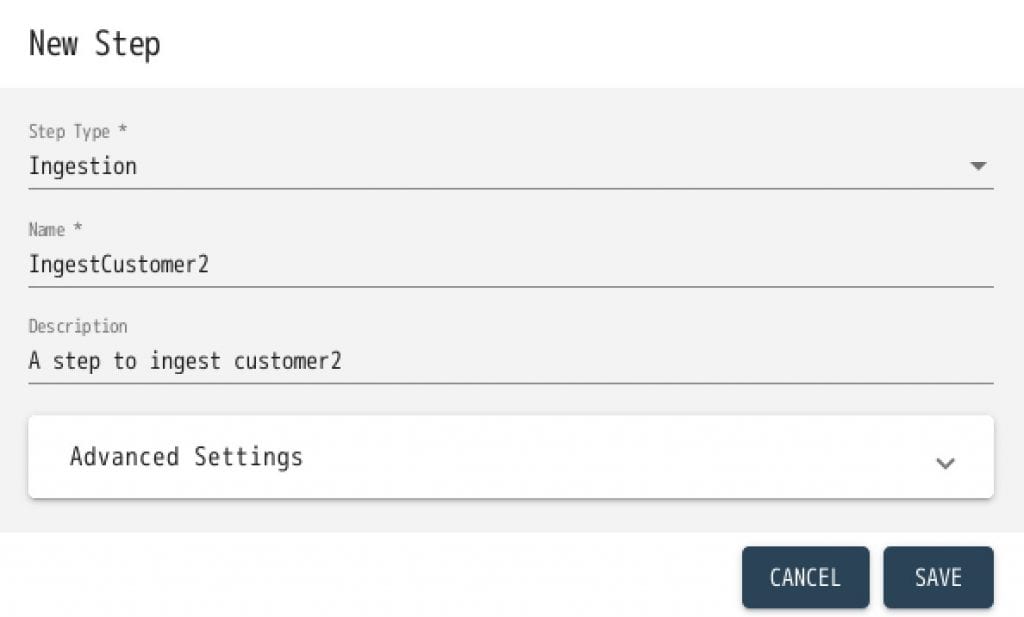
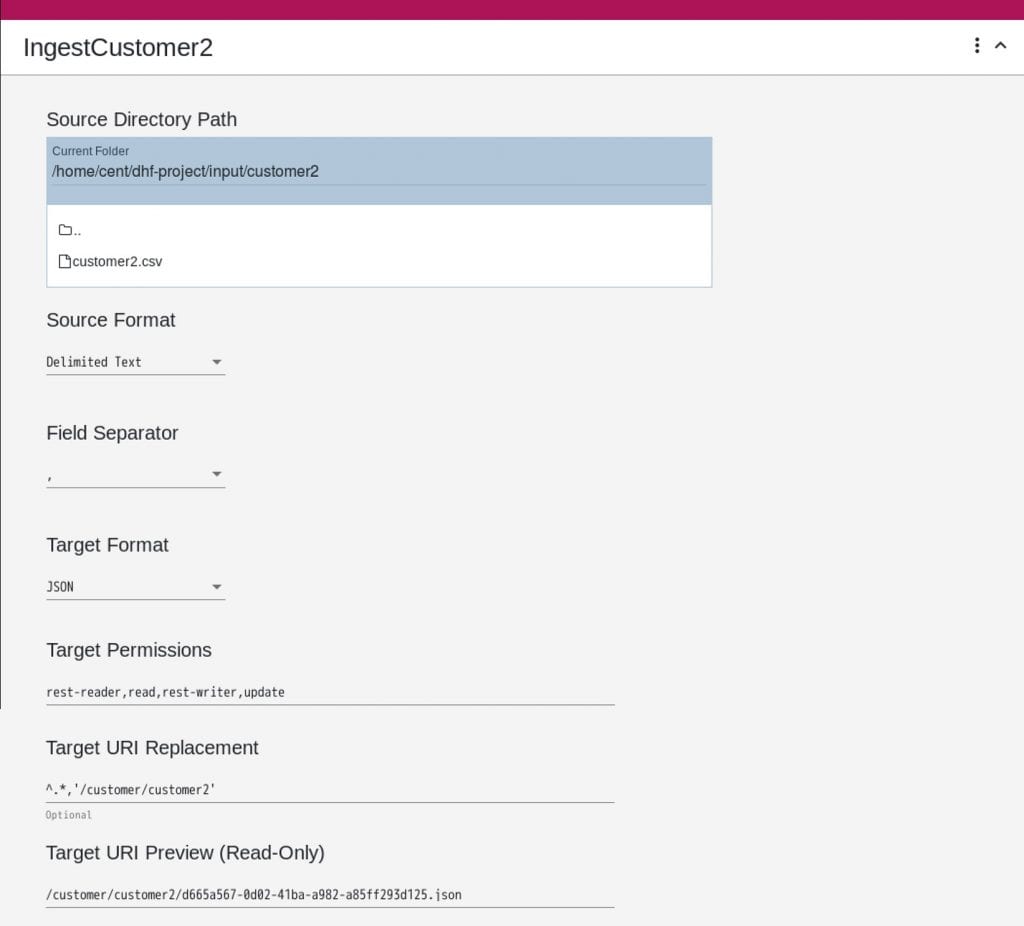
- Source Directory Path: /home/cent/dhf-project/input/customer2
※実際のパスに合わせて修正してください - Source Format: Delimited Text
- Field Separator: ,(コンマ)
- Target Format: JSON
- Target Permissions: (変更しない)
- Target URI Replacement: ^.*,’/customer/customer2′
- Source Directory Path: /home/cent/dhf-project/input/customer2
- 画面上部の”RUN”をクリックします。
Run Flowインターフェースで”IngestCustomer2” Step にチェックが入っていることを確認して、”RUN”をクリックします。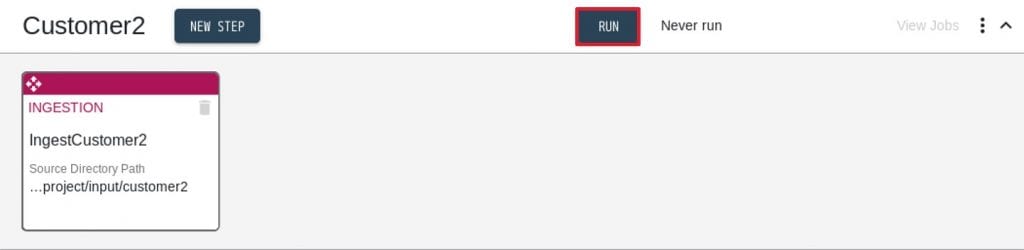

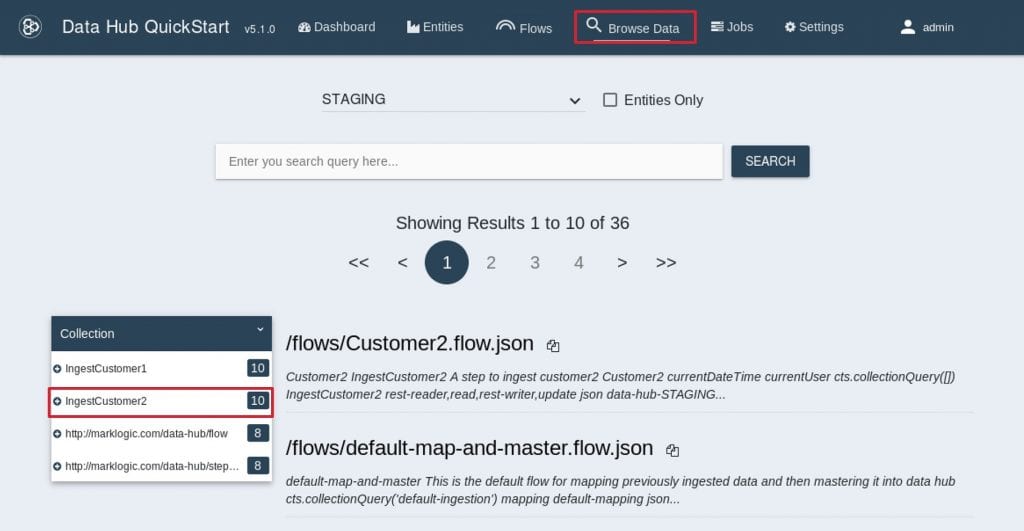
- QuickStartメニューから”Browse Data”を選択すると、コレクションが”IngestCustomer2”のドキュメントが10件取り込まれていることがわかります。
以上でcsvデータをそのままの形式でステージングDBに取り込むことができました。
ただし、取り込まれたデータは下記の通りデータの構造が異なっています(項目名やデータ形式が異なるなど)。
このままでは、同一条件での検索ができません。
 実際にこれらのデータを検索してみましょう。
実際にこれらのデータを検索してみましょう。
例として、中野さんを探すことを考えます。
- クエリコンソール (https://localhost:8000) にアクセスする。
- 下記の通り設定し、Runをクリックします。
- Database: data-hub-STAGING
- Query Type: JavaScript
- コード: search(“中野”)

- 下記のような三件のデータが表示されます。
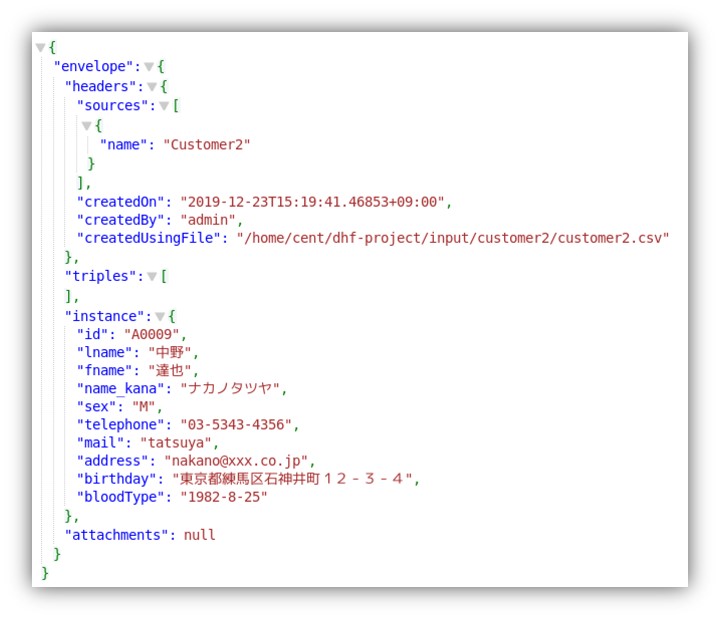

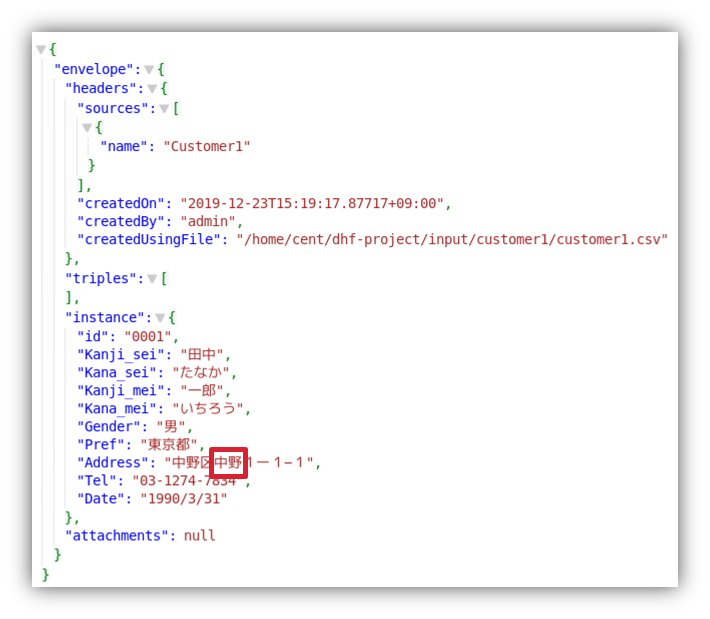 MarkLogicでは取り込んだドキュメントに対して自動的にインデックスが作成され、このような任意のキーワードを用いた検索が可能になります。
MarkLogicでは取り込んだドキュメントに対して自動的にインデックスが作成され、このような任意のキーワードを用いた検索が可能になります。
ただ、今回中野さんを検索したのにも関わらず、田中さんも検索結果に表示されてしまっています。
これは、住所に”中野”が含まれていたためです。 - 次にプロパティを特定して検索を行います。
タブの+をクリックして新しいタブを作成したら、下記の通り設定し、Runをクリックします。- Database: data-hub-STAGING
- Query Type: JavaScript
- コード: cts.search(cts.jsonPropertyScopeQuery( “Kanji_sei”, “中野”))

- すると下記のように、Customer1のデータのみが検索結果として表示されます。
これはCustomer2では、異なる項目名(lname)で名字を管理しているためです。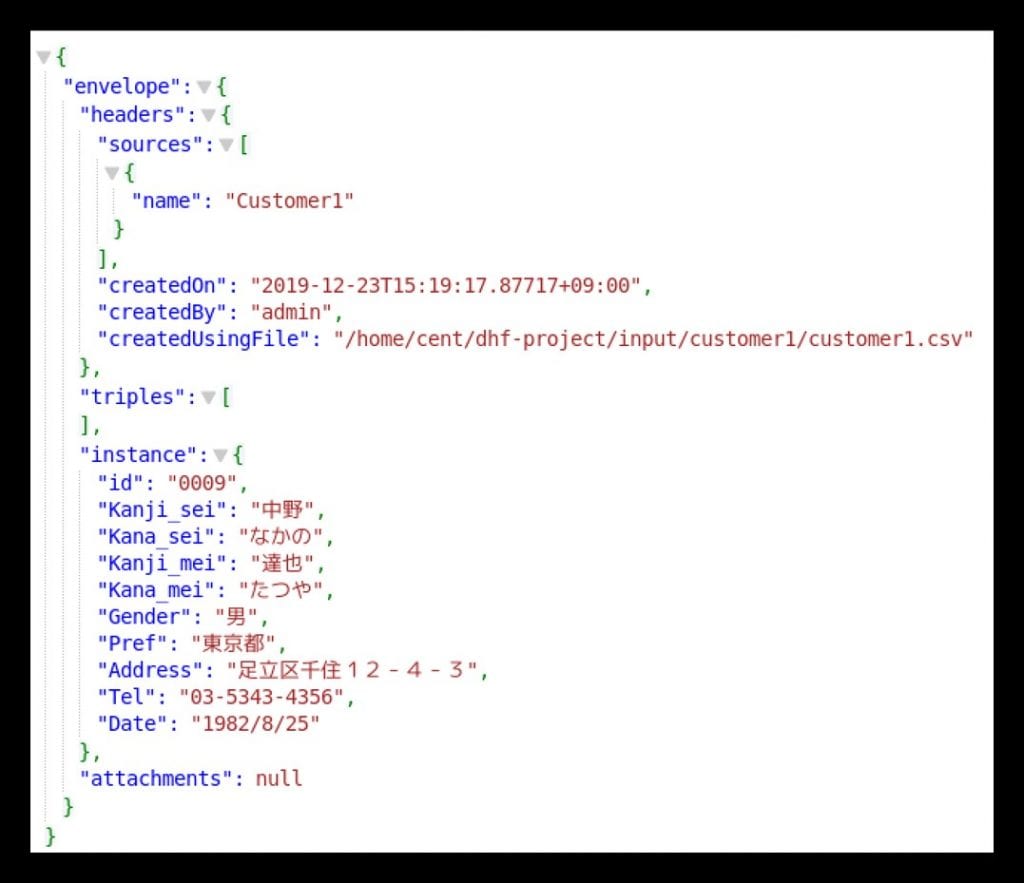
今回の例では名字での検索を行いましたが、これ以外にも例えば誕生日で検索したい場合なども2つのデータソースの項目名を揃える必要があります。
次回の記事では、このように2つのデータソースで異なる項目名やデータ・フォーマットをどのようにして共通のデータモデルにキュレートするかご紹介します。
