
Wouldn’t it be nice if there was a place to easily find tips and tricks that help developers optimize their XQuery code in easy-to-follow steps? Look no further! Here is a checklist you can use as a go-to resource to help with XQuery.
#1 – Is your query running in “Accidental” update mode?
MarkLogic runs transactions in one of two modes: query and update. The main difference is that query transactions are read-only and cannot perform update operations, while update transactions can perform update operations.
This is my #1 on the list because I myself accidentally run code in update mode often, which can result in significant performance losses—but as we will see, it’s very easy to check.
How does this impact performance?
Before we get into this, please be aware that update statements are necessary to update data in the database. You absolutely want and need to use them.
However, there are times when you are running code that doesn’t update anything. Such query-only code should run in query mode. Here, we are addressing the case where you accidentally run your query in update mode.
When you run in update mode MarkLogic will use reader and writer locks as needed. It can be easy to accidentally run a transaction in update mode. Doing so could have dire consequences to performance. Take for example this query:
for $doc in fn:doc() where $doc/root/selected = true() return $doc
fn:doc(), when given no parameters, returns everything in the database. If this code gets run in update mode, then MarkLogic will assume that you plan to update documents, so it locks every single document returned by fn:doc(). And because write locks are exclusive, all multithreaded requests are forced to fight for locks. Lock contention is normal and expected, but it can degrade performance. Although a naive example, it illustrates the point. If you accidentally run code in update mode when you don’t really want to, then you can cause performance problems.
How do I know if I’m running in update mode?
Lucky for us, there is a nifty trick we can employ to throw an error if we are running in update mode when we want to be in query mode.
let $assert-query-mode as xs:unsignedLong := xdmp:request-timestamp() for $doc in fn:doc() where $doc/root/selected = true() return $doc
They key here is the “let” statement:
let $assert-query-mode as xs:unsignedLong := xdmp:request-timestamp()
xdmp:request-timest returns an xs:unsignedLong when running in query mode. But it returns empty-sequence() when running in update mode. This let statement, if run from an update transaction, will fail to cast empty-sequence() to xs:unsignedLong, and thus throws an exception.
If you run your query and the exception is thrown, then you know that you are running in update mode. Now you have to track down the reason and try to fix it so your code can run in query mode.
How do I end up in accidental update mode?
Here are a few scenarios that could lead you to end up accidentally in update mode:
- xdmp:eval, xdmp:invoke, xdmp:invoke-function, xdmp:spawn, xdmp:spawn-function. These functions allow you to execute code and specify configuration options for transaction mode. If one of these functions is running your code then look there to see if you have it set to update mode by accident.
- REST API service extensions. The MarkLogic REST API allows you to define your own service extensions. You create an xquery library module with one or more entry point functions (get, post, put, delete, etc). Some of these functions run as query mode by default and some run as update mode. See the REST API docs for more specifics. Then check to see if you are running your code from one of the methods that runs in update mode by default.
- Static Analysis: When your transaction is set to auto you allow MarkLogic to decide whether to run in update or query mode. To make this determination, MarkLogic will run static analysis on your code looking for calls to any of the functions that perform updates. If any of these functions are found in the code path then MarkLogic will run in update mode.
An example of some code that will cause update mode:
let $assert-query-mode as xs:unsignedLong := xdmp:request-timestamp()
return
if (fn:false()) then
xdmp:document-insert("/test.xml", <test>This never gets called</test>)
else
"query mode stuff"As you can see, the document-insert is never called, but MarkLogic still sees it right there in the code path and thus runs in update mode.
There is an entire chapter devoted to transactions in the MarkLogic User’s guide; I recommend that everyone read it at least once a year.
#2 – Am I running cts:search unfiltered?
Step #2 on my list is very easy to overlook, but luckily, is a quick and simple fix.
Perhaps one of MarkLogic’s most famous APIs is cts:search. Every MarkLogic developer has used it at some point. If you are that developer and you find your search seems to be running slower than you’d like, perhaps you are accidentally running a filtered search.
What’s a filtered search?
Scott Parnell said it well in his blog post A goal without a plan is just a wish from November 2016:
By default,
cts:searchresolves queries in two phases. The first phase performs index resolution on the D-nodes. This initial result may contain false positives depending on the index configuration and the query. The second phase performs filtering of the results on the E-nodes, which examines the matched documents and removes false positives. If a query can be resolved completely from the indexes, then filtering is not required.
Assuming you have your indexes configured properly and you want to run unfiltered, let’s move forward with checking your cts:search.
Looking at the docs for cts:search you will see this function signature:
cts:search( $expression as node()*, $query as cts:query?, [$options as (cts:order|xs:string)*], [$quality-weight as xs:double?], [$forest-ids as xs:unsignedLong*] ) as node()*
In order for cts:search to run unfiltered, you must specify “unfiltered” as an option in the third parameter.
cts:search(fn:doc(), $query, ("unfiltered"))What gets most of us is that the default for cts:search is “filtered”. By not supplying the “unfiltered” parameter we are relying on the default, filtered behavior.
#3 – Profile your code
When code is not performing to your expectations, you should ALWAYS profile it. Don’t even bother optimizing it until you do. You will most likely waste your time fixing the wrong thing.
Lucky for us, MarkLogic makes it somewhat easy to do this.
Easiest Way: Use Query Console (QConsole)
From the MarkLogic Docs:
Query Console is an interactive web-based query development tool for writing and executing ad-hoc queries in XQuery, Server-Side JavaScript, SQL and SPARQL. Query Console enables you to quickly test code snippets, debug problems, profile queries, and run administrative XQuery scripts.
QConsole lives at http://yourserver:8000/qconsole/.
It includes a handy profile button to tell you where your query is spending the most time, which is great news if you can easily run your query.
Simply type in the code you wish to run, press the profile tab, then press the run button.
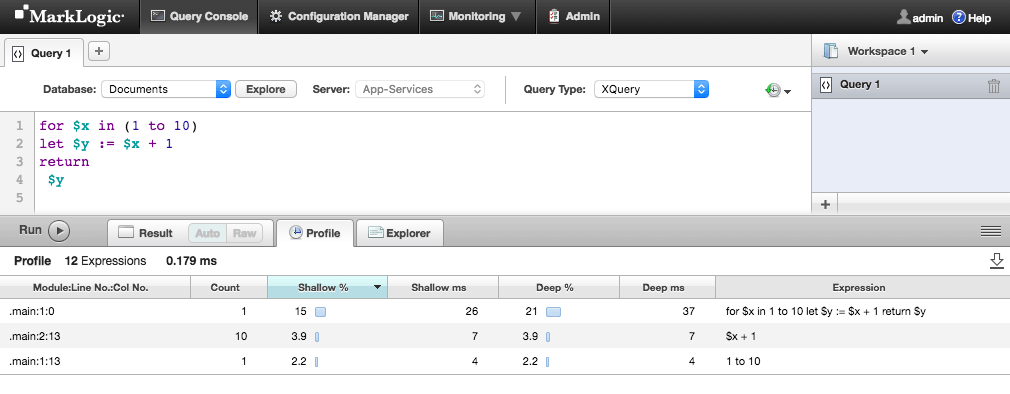
The results in the table are sorted from longest running to shortest (Shallow %). Look for unusually long running statements and see how you can optimize them.
Harder Way: Using prof:enable() and prof:report()
Let’s say that you can’t just run your code in QConsole for whatever reason. Fear not, there are functions to help you.
Simply wrap your code like so:
prof:enable(xdmp:request()), for $x in (1 to 10) let $y := $x + 1 return $y, prof:disable(xdmp:request()), prof:report(xdmp:request())
The output of prof:report() is an xml representation of the profile report. If your code is buried deep within other code, you can either log the report with xdmp:log or insert it into a document with xdmp:document-insert() to look at later.
If you like to get fancy, you can create a reusable module with a function to log it for you.
(: name this file something like /path/to/profiler.xqy :)
xquery version "1.0-ml";
module namespace profiler = "http://marklogic.com/profiler";
declare function profiler:profile($func)
{
let $req := xdmp:request()
(: start profiling :)
let $_ := prof:enable($req)
(: call the code to profile :)
let $result := $func()
(: stop profiling :)
let $_ := prof:disable($req)
(: create the profile report :)
let $report := prof:report($req)
(: save report somewhere :)
let $_ := xdmp:document-insert("/profile-output/" || fn:string($req) || ".xml", $report)
(: log it too :)
let $_ := xdmp:log(xdmp:describe($report, (), ()))
return
(: return the output, if any, from your profiled code :)
$result
};That is fancy! How do I use it?
import module namespace profiler = "http://marklogic.com/profiler"
at "/path/to/profiler.xqy";
profiler:profile(function() {
(: put your code in here :)
for $x in (1 to 10)
let $y := $x + 1
return
$y
})Now when you run your code, the profiler report will be logged to the ErrorLog and inserted at /profile-output/${requestid}.xml. It’s not as easy to read as the QConsole output, but it contains all the same information.
#4 – Use indexes when appropriate
MarkLogic run queries in two phases. The first and fastest phase uses indexes to narrow the number of results. These initial results may contain false-positives depending on the index configuration and the query. The second phase performs filtering of the results. This second phase involves retrieving the documents from disk and verifying that they match the query. Documents that do not match (false-positives) are removed from the result set. Using the disk I/O when retrieving the documents is what usually causes queries to run slow.
In many cases you can rely solely on indexes to avoid the second phase. MarkLogic exposes many functions in the cts and xdmp namespaces for doing exactly this.
A Simple Example
A common example is getting the number of documents that match a query.
fn:count(/customer[@paid=fn:false()])
This can perform poorly because it has to retrieve every customer matching the paid=”false” attribute from disk. To speed it up, use indexes instead.
xdmp:estimate(/customer[@paid=fn:false()])
Note that we use xdmp:estimate. The key to this being fast is that it runs unfiltered. It doesn’t perform the second phase of query resolution. That’s why its name is estimate. It’s relying on your indexes to give you a count. To ensure the resulting value is correct, you need to properly configure your indexes.
#5 – Optimize cts:search using indexes
If after steps 1-4 you find that your performance bottlenecks are in your cts:search code, you will want to start looking at index optimization. I will refer you to Scott Parnell’s blog post A goal without a plan is just a wish from November 2016 which covers this in more detail.
Further Reading
This checklist demonstrates some of the ways that MarkLogic developers go about finding and fixing performance issues. For more information on the topics discussed in this article, read some of these:
- Performance: Understanding System Resources (white paper)
- Inside MarkLogic Server (white paper)
- A goal without a plan is just a wish (blog)
- Query Performance and Tuning Guide (guide)
- Understanding Transactions in MarkLogic Server (guide)
