
We are excited to announce that our new feature, MarkLogic Embedded Machine Learning, is generally available with the release of MarkLogic 10.
The MarkLogic database is the core of our Data Hub Platform. As a platform for simplifying complex data integration, it’s already incredibly smart. It uses advanced capabilities for data harmonization, mastering and security that no other database has. Now, with Embedded Machine Learning running at the core of the database, our platform is even smarter.
First, our engineering team is leveraging Embedded Machine Learning to improve how the database operates. This means using it to run queries more efficiently and scale autonomously based on workload patterns and much more.
Second, Embedded Machine Learning reduces complexity and increases automation of various steps in the data curation process. Smart Mastering, for example, will get even smarter because we can now augment the existing rules-based approach.
And third, Embedded Machine Learning opens up a world of possibilities for data scientists who want to do machine learning with data stored in MarkLogic. Yes, you can still export data to other machine learning and AI tools. But, it’s now simpler to just do the work of training and executing models right inside MarkLogic.
In this post, I provide some background and context to explain how we got here, how we’re solving some of the big challenges with machine learning and a quick example of how to use our new capability in practice.
Machine Learning as Pattern Recognition
Machine learning is essentially pattern recognition—that’s it.
It is special because the patterns hide in data so voluminous and complex that they are very difficult to detect without advanced tools. To recognize patterns, you need to understand the relationships between attributes (called features in machine learning circles). A machine learning model is a mathematical representation of those relationships.
Imagine an entity you have in your business: a person, a financial trade, a chemical formula. It consists of many attributes (i.e., features) that describe it and its unique properties. For example, a person has demographic information, financial information, personal health history and many more.
The combination of attributes make up a feature space that describes that entity. Other entities may have the same features, but with different values. We call the feature space high dimensional because there are many different attributes—way more than the two or three we can easily visualize.
One of the things a machine learning model can do is “see” the patterns. Once you know the patterns, you can start doing all kinds of cool things like prediction and classification:
- Prediction – Predict some future state based on how those features might change. For example, a person becomes a high risk for a health condition because of these non-obvious changes in their lifestyle or condition.
- Classification – You can classify new data based on the patterns learned from history. For example, this new customer has attributes that put them in this existing category.
Machine learning also has another benefit: accuracy.
A well-trained model almost always outperforms a rules-based system. When the feature space is big and the relationships are complex, just writing the rules becomes an impossible task. Imagine writing the rules to identify a handwritten number in a picture. It’s complicated for a human to comprehend, but today, this is an easy, straightforward task for modern machine learning tools. It is almost the equivalent of the “hello world” example that every programming language has.
Since models change their behavior with experience, they can improve their behavior, putting the “learning” in machine learning. Training, the process by which these models change, is a little too deep for this post. It’s best just to know that it’s true, and know that no rules-based system could accomplish such a feat.
The Machine Learning Hype
The desire to see in high-dimensional space, predict, classify and learn are not new.
Neural network models that are hugely popular today and drive innovation like self-driving cars are based on models first postulated in the 90s and early 2000s. Also, some techniques are even from the 19th century. For example, gradient descent is one of the most popular techniques for optimizing models. The scientific paper that introduced it was written in 1847 by Augustin-Louis Cauchy.
So, why is machine learning a big deal now?
First, it’s about the data. To create an accurate model, a huge amount of data is needed to unearth those hidden patterns. The volume of data has exploded recently, meaning more food for these engines.
And, the data must be integrated. It is not always evident what features accurately express a problem or contain a vital relationship. As we know, features even about a single entity may be scattered across multiple systems in your organization.
In other words: That same 360-degree view your call-center rep needs to service a customer is also required for your neural net to predict their behavior.
Second, there are a number of high-performance, accurate machine learning frameworks and toolkits out there that encapsulate the math and make it possible to build processes in an enterprise environment. Through the force of the community, these are constantly improving, making them more accurate and faster.
Finally, getting any of this done requires significant horsepower. What these techniques do is convert all of those features to numbers, and execute massive matrix math functions against them. CPUs are not good at this. But, we now have GPUs that excel in parallel computation.
Challenges with Machine Learning
We’ve covered what machine learning does and why its gaining popularity. But, what are the challenges in adoption?
The truth is, investment in AI and machine learning often deliver very low ROI. AI investments for most companies look more like science projects rather than core infrastructure. One of the reasons is that the business doesn’t understand or trust the ‘black box’ outputs of machine learning models, which makes it hard to make decisions using them even if they are accurate.
Larger and more complex models make it hard to explain, in human terms, why a certain decision was reached (and even harder when it was reached in real time).”
And, the tools ecosystem is incredibly complex. It’s the wild west of AI and machine learning, and as the available technologies move from the lab to the enterprise, it’s critical to understand things like security and governance implications. It’s also tough to find people with the right skillsets to build and maintain the systems.
And of course, there is a huge challenge that data scientists have when assembling the large training sets of data required. According to an article in The New York Times, data scientists spend 80% of their time just wrangling data.
What data should be used? Is it accurate and trustworthy? Where did it come from? Does it contain PII? Is it the same data we used last time? Has it been cleaned up in any way? What data should we use to reproduce the result?
Good data is critical because machine learning can be even more sensitive to data quality. Think about it: You’re using the same data to both train and then execute the model. Any problems with data quality get amplified.
Your data scientists are some of your most valuable assets, and data wrangling is not what you want some of your smartest people spending time on, especially when there is a product available that is perfect for the task.
Our Approach with Embedded Machine Learning
We think the best place to do machine learning is in a data hub where data can be secured, governed and curated. With this approach, we can solve many of the challenges with governance and trust, while also unlocking the benefits that machine learning promises.
We’re proud to announce that in MarkLogic 10, Embedded Machine Learning is built right into the core of the MarkLogic database. Machine learning routines can run close to the data, in parallel across a MarkLogic cluster, under the umbrella of a secure environment.
As mentioned in the introduction, we expect that this new capability will benefit you in three important ways: How the database operates, how you curate data and how data scientists train and execute models.
1. Improving how the database operates
Our engineering team is leveraging Embedded Machine Learning to improve how the database operates. While we’re just at the beginning stages of these advancements, we’ve laid the groundwork and have exciting things planned on the roadmap.
With predictive query optimization, for example, by monitoring workload patterns and access plans, we can improve the performance of future executions by automatically re-tuning the system.
Another example is autonomous elasticity. MarkLogic can use models of infrastructure workload patterns to automatically adjust the rules that govern data and index rebalancing.
2. Improving how you curate data
When using the MarkLogic Data Hub, you ingest data and then curate it to make it more useful. Curation involves quality checks, harmonization, mastering and enrichment. Machine learning has applications for each of these steps, helping to reduce complexity and increase automation.
Smart Mastering
Smart Mastering intelligently matches and merges data. It already used AI and fuzzy matching, and now with Embedded Machine Learning, Smart Mastering will get even smarter. We will be using machine learning to augment the existing rules-based mastering process to improve accuracy and manage exceptions.
Data Modeling
Machine learning can be used during the modeling phase to identify whether particular data may have PII and improves the matching algorithms to make them more accurate (and require less human intervention). Machine learning can also assist with the classification of attributes and suggest mapping and modeling rules.
For any of these use cases, the machine learning models used can be provided by you, or you can use models readily available from MarkLogic.
And, perhaps most importantly, machine learning models are continuously retrained to improve their accuracy on subsequent runs. In other words, as more data is integrated, your system gets smarter.
With machine learning, it’s a virtuous cycle.
3. Improving data science workflows
For data scientists, it’s now simpler to just do the work of training and executing models right inside MarkLogic.
Gartner suggests a reference architecture in its Technical Professional Advice paper titled Preparing and Architecting for Machine Learning, which details the various components you need to support machine learning. Looking at their recommendations, you can see that MarkLogic handles almost every part of the architecture and process. This includes the data processing/curation step and the model engineering to build, train, execute and deploy the model. The only other thing that happens outside MarkLogic, of course, is identifying the use case.
How It works
So, how does Embedded Machine Learning actually work? Below we discuss some of the key technologies that are part of our solution, which include CUDA and ONNX. This will be most helpful for data scientists, as this will be transparent to most users who just get the benefits of Embedded Machine Learning without having to delve into the details.
CUDA
We embedded Nvidia’s CUDA libraries into the MarkLogic database, allowing you to leverage the powerful computing capabilities of graphics processors for machine learning operations.
CUDA is an acronym for Compute Unified Device Architecture and describes a parallel computing platform and programming model developed by NVIDIA for general computing. With the appropriate CUDA-enabled GPU hardware—essentially all modern Nvidia series, including GeForce, Quadro and the Tesla—these libraries provide direct access to the GPU’s virtual instruction set and parallel computational elements.
By leveraging this common platform, GPU-accelerated applications can be developed and deployed on laptops and desktops in an on-premises data center and in the cloud.
ONNX
Lastly, we included the ONNX runtime, making it possible to deploy models developed with other frameworks in MarkLogic.
ONNX is an open format with a large ecosystem that makes machine learning more accessible and valuable to all data scientists. Models can be trained in one framework and transferred to another for execution. This prevents tool or ecosystem lock-in and makes the sharing of models more universal.
ONNX models are currently supported in Microsoft Cognitive Toolkit, Cafe2, MXNet and PyTorch, and there are connectors for the most popular frameworks like TensorFlow. In addition to frameworks, ONNX also supports a wide variety of tools in the machine learning toolchain with a number of available converters, runtimes, compilers and visualizers available.
A Simple Demo
Let’s take a look at a simple example of creating a model in a popular toolkit, exporting it to the ONNX format and deploying to MarkLogic for use in our application.
In this simple example, I want to predict a person’s gender by looking at their shoe size, height and weight. This is pretty simplistic, but this same process will work with models of any complexity, so the details don’t matter.
I’m going to build my model and put in a simple training data set (the data set is shown below, and while it’s included in the below Python code, you can also download the Excel file here). It includes a list of shoe sizes, heights, weights and genders. Gender is what I want to predict, and it is part of the training set, making this a classic supervised learning scenario.
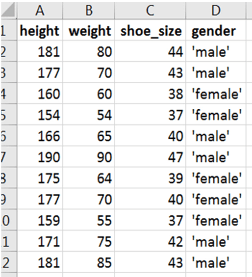
My Python code is equally simple. I define and train the model, test it with some additional data and then export the trained model to a binary ONNX file.
# Import libraries
import onnx
import keras2onnx
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Training Set
# Vectors - [height, weight, shoe_size]
X = [[181, 80, 44],
[177, 70, 43],
[160, 60, 38],
[154, 54, 37],
[166, 65, 40],
[190, 90, 47],
[175, 64, 39],
[177, 70, 40],
[159, 55, 37],
[171, 75, 42],
[181, 85, 43]]
# Labels - 1 per vector, 0 for male and 1 for female
Y = [0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 0]
# create model
model = Sequential()
model.add(Dense(60, input_dim=3, kernel_initializer='normal', activation='relu'))
model.add(Dense(1, kernel_initializer='normal', activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# train model
model.fit(X, Y, epochs=500)
# save the model in ONNX format
onnx_model = keras2onnx.convert_keras(model, model.name)
onnx.save_model(onnx_model, "gender_classifier.onnx")
With my trained model saved as a file, I can save it to the database as a binary file:
declareUpdate();
xdmp.documentLoad('/space/models/gender_classifier.onnx',
{
uri : '/gender_classifier.onnx',
permissions : xdmp.defaultPermissions(),
format : 'binary'
});
Once saved, I can execute it using my test data to confirm all is well:
const session = ort.session(cts.doc("/gender_classifier.onnx"))
const inputCount = ort.sessionInputCount(session)
const outputCount = ort.sessionOutputCount(session)
var inputNames = []
var i,j
for (i=0;i<inputCount;i++){
inputNames.push(ort.sessionInputName(session, i))
}
var outputNames = []
for (i=0;i<outputCount;i++){
outputNames.push(ort.sessionOutputName(session, i))
}
var inputMap = {};
var inputData =[
[180, 80, 44],
[177, 71, 43],
[161, 62, 38],
[155, 55, 37]
];
var predictions = []
var idx
for (idx=0; idx < inputData.length; idx++ ) {
var inputValues = ort.value(inputData[idx], [1,3], "float")
inputMap[inputNames[0]] = inputValues;
var ortval = ort.run(session, inputMap);
var prediction = ort.valueGetArray(ortval[outputNames[0]])[0];
if (prediction < 0.5)
predictions.push({ "data": inputData[idx], "prediction": "male"})
else
predictions.push({ "data": inputData[idx], "prediction": "female"});
}
predictions;
/* Expected output =>
[
{"data":[180, 80, 44], "prediction":"male"},
{"data":[177, 71, 43], "prediction":"male"},
{"data":[161, 62, 38], "prediction":"female"},
{"data":[155, 55, 37], "prediction":"female"}
]
*/As I mentioned, the model can be arbitrarily complex. But, even in this simple example, I can use machine learning to enrich entities that may be missing gender or even perform anomaly (fraud) detection by comparing actual data to model expectations. I can also retrain the model to improve future predictions.
In our MarkLogic World session, we show the example of deploying a text summarization model to MarkLogic and executing it as part of a fully ACID-compliant database transaction. You can watch the full recording below:
Final Thoughts
AI and machine learning are fascinating topics, but the pathway from hype to reality is often unclear. It’s easy to think it’s overly complex or only for companies that work on robots and self-driving cars.
I love the more tangible example of how Frito-Lay is using machine learning to measure the weight of potatoes. That little improvement saved them an estimated $10.5 million in equipment they no longer had to buy.
When I think about machine learning in this context, I think of Mulder and Scully from that 90s TV show “The X-Files” (sorry millennials). The tagline was “the truth is out there.” With machine learning, let’s instead think, “the truth is in there.”
Our goal is to make machine learning beneficial for every organization we work with, and to make it easy to implement. We encourage you to try out our new capability and use it to better manage your data and unlock hidden insights.
Resources
MarkLogic 10 Download
Download MarkLogic 10, including the text summarization example model, at https://developer.marklogic.com/products/marklogic-server/10.0
Machine Learning User Guide
To accompany this release, we have a full user guide available at http://docs.marklogic.com/guide/app-dev/MachineLearning#chapter
