
多様なデータを一か所にまとめて格納しなければならないのは、なぜでしょうか。多様なデータをあちこちに置いてはいけないのでしょうか。私のお客様のうち一社は、後者を選択したことにより大変な目に遭いました。こういった苦労が繰り返されないように、ケーススタディをここに記録しておきます。
正直言って、私がこのブログを書いているのは自分のためでもあります。3、4個の別個の永続性/データ処理製品(「ポリグロット」=多言語)を統合してフランケンシュタイン的なものを作り出そうとしているチームは、スローモーションで橋から川に転落していく年老いたソフトウェアアーキテクトで満員の電車のようでもあります。

フランケンシュタイン的なものの構築はつらい – 見ている方もつらい
独立した別々のシステムをどうしても作らなければならないことも時にはあるでしょう。しかしMarkLogicを使えば、そういった統合のほとんどを回避できます。というわけで今回はその選択方法について、またそれが重要な理由を書いていきます。
ポリグロットパーシステンス
マーティン・ファウラーが「ポリグロットパーシステンス」について初めてブログに書いたのは2011年で、それ以降この言葉が普及しました。今Googleでこの言葉を検索すると、8万5000件以上ヒットします。データベースに関わっている人であれば、「多種多様なデータを扱わなければならないこと」や「そのための多種多様なツールが必要」なことは認識しているでしょう。テキストデータ、バイナリデータ、構造化データ、セマンティックデータ。これらは「最近流行り始めた言葉」で、今後数年間でもっと耳にするようになるでしょう。
従来、「ポリグロットパーシステンス」を実現するには、各データタイプをそれぞれに合ったテクノロジーで格納する必要があるとされてきました。しかし、「ポリグロット」は「多言語を話せる」という意味であり「多くのコンポーネントを統合できる」ということではありません。これに関して、私の顧客企業は問題に直面しました。担当チームは、複数のデータタイプごとに別個のデータストア(格納手段)を使う従来のアプローチを取りました。このブログでは、その際、2種類のデータ(構造化データとバイナリデータ)を、1つに統合されたデータストアではなく2つのデータストアに格納したことで、何が起こったのかについて取り上げていきます。
一方MarkLogicは、ポリグロットパーシステンスを「マルチモデルデータベース」で実現します。このブログでは最後に、今回のチームがこの機能を使ってシステムをシンプルなものに作り直したことを紹介します。
例:Excelワークシート
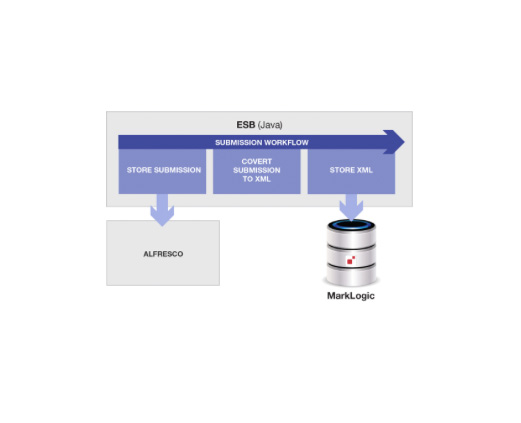
この顧客企業の例に戻りましょう。この企業が特定されないように、ここでは仮にこれを不動産ローンのシステムの話とし、ローンの申し込みに、資産や支出などを記載したExcelワークシートを使っているとします。受け取ったExcelワークシートから、さまざまな収入や支出がXMLに抽出されます。その後、これら2種類のデータを格納して、不動産ローン申し込みの処理に利用します。
「バイナリであるExcel」と「抽出されたXML」を格納したあと、ワークフローエンジンで担当者がこの申し込みを確認し、承認(あるいは却下)します。このようなベーシックな流れは、数多くのコンピュータシステムで見られるものです。例としては、ローンの申し込み、大規模プロジェクトの企画書提出、ベンダー選定申し込みなどがあるでしょう。
ここでは、このシステムでは「元の『非構造化』バイナリデータ(.xslx、.pdf、.jpg)」と「Excelから抽出された構造化XMLデータ」の両方を格納することについて、特に見ていきましょう。
この点についてお客様は次のように考えました。これがあとあと問題となります。
「MarkLogicは世界最高のXML/JSONストアだということは理解しています。でもバイナリは『コンテンツシステム』に入れるべきでしょう。CMSやDAMなんかにです。このExcelや生成されたPDFの案内はAlfrescoに入れましょう。それからXMLはMarkLogicに入れましょう。こうすれば、各データタイプにとってベストなシステムを使うことになるのですから」
この場合、アーキテクチャはこんな風になるでしょう。
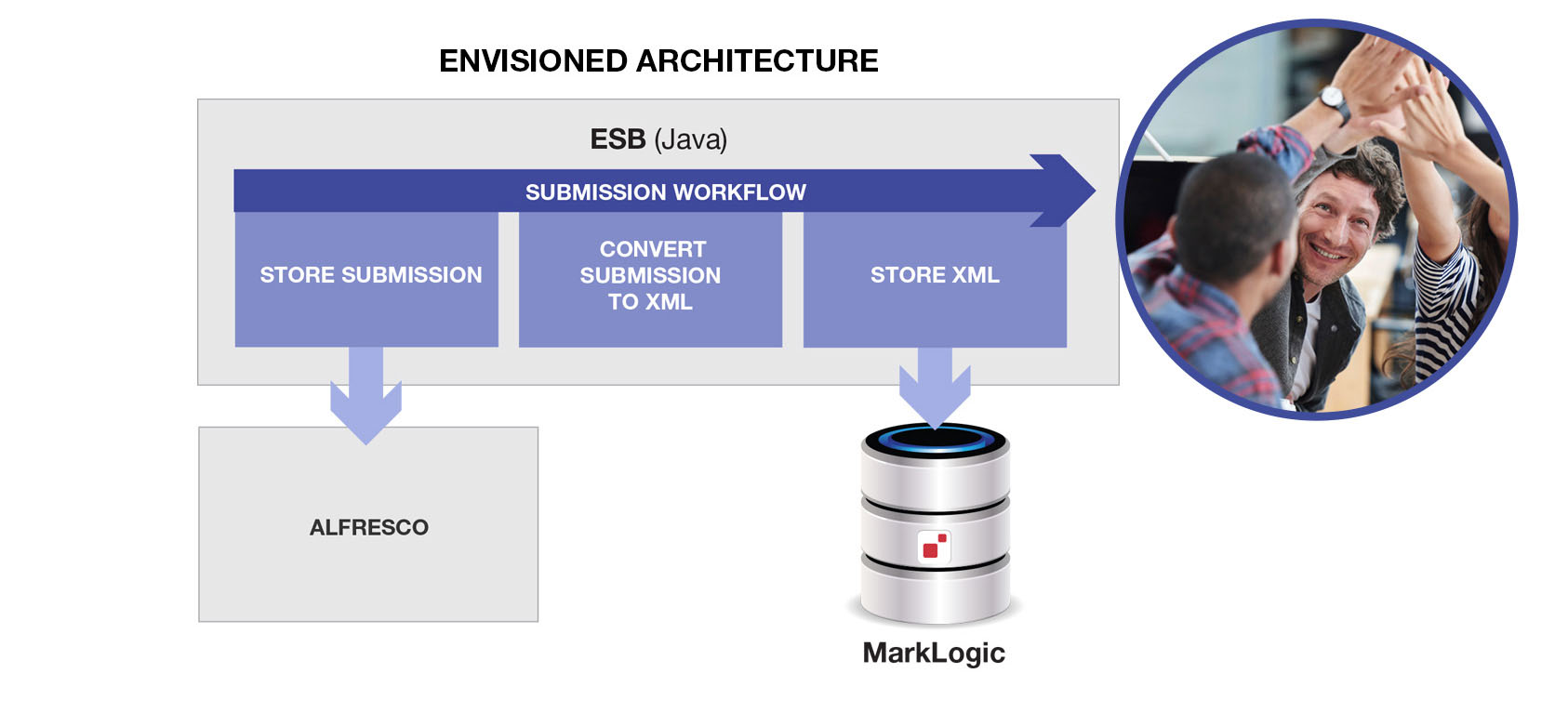
この場合、アーキテクチャは上の図のようになります。シンプルですよね。 天才的なチームメンバーたちとハイタッチでお祝いできそうです。
入れたデータを取り出す
データを使ってみようとしたら、すぐに1つめの問題が発生しました。ここでは、品質管理のためにデータを第三者機関に送って、複雑なビジネスルールと照らし合わせてもらう必要がありました(今回のプロジェクトのスコープの範囲外です)。レビュー担当者は、ある基準を満たしたXMLレコード(この例では仮に「スーパージャンボ」不動産ローンに該当するもの、としておきます)が必要でした。これをZIPファイルにして(1GB以下となるように分けて)送ってほしいとのことでした。
これは簡単ですよね。先週分の新規スーパージャンボローンを収集し、1GBになったらそこでストップすればいいわけです。そして該当するものがなくなるまで、これを繰り返します。しかし、ここで問題が2つありました。
- 先週のスーパージャンボがどれかを把握しているのは、MarkLogicだけでした。Alfrescoのメタデータは限られていました。スーパージャンボの基準(ローンの規模、郵便番号ごとのジャンボの限度)はデータベース内にあり、Alfrescoにはありませんでした。
- またどこでストップすべきかもわかりませんでした。というのもバイナリを入手してみないと、ZIPファイルのサイズがどのくらいになるのかわからなかったからです。
忙しい時間帯には大量のデータが発生するため、Spring Batchで長時間のバッチ処理ジョブをコーディネートしました。突然3つめのコンポーネントが登場したことで、これはさらに複雑になりました。
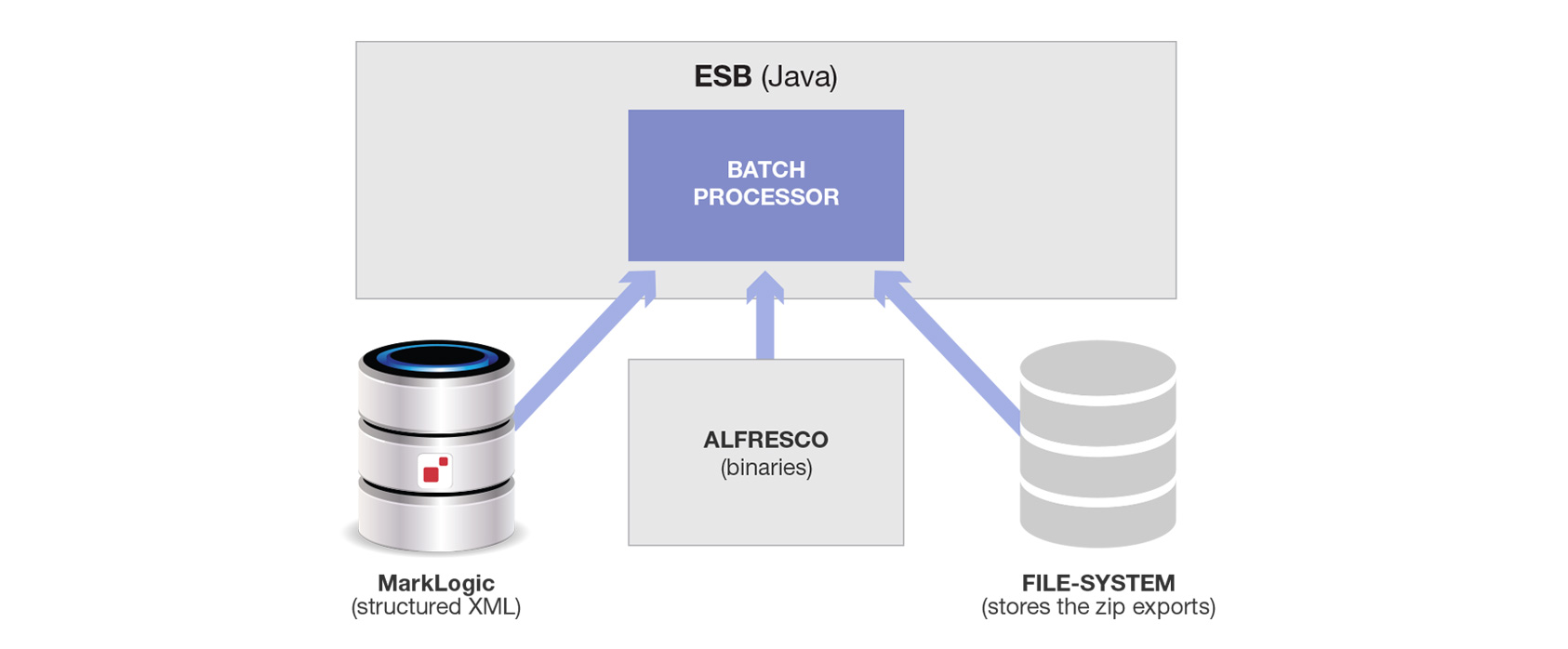
この図は、バッチプロセッサがMarkLogicからコンテンツを取ってファイルシステムに書き込み、またAlfrescoからもコンテンツを取ってファイルシステムに書き込んでいる様子を表しています。両方が1つのディレクトリ内にファイル量の制約まで入れられZIPされます(あるいは代替手段としては、ファイル名をハッシュ化し、このハッシュの冒頭2桁を使って適切なサイズのサブディレクトリを100個作るというやり方がありますが、どちらの場合でも複雑になります)。
ここで、送れるデータ量に制限があったことを思い出してください。このため、「ディスク上の各ファイルのサイズを判断する」、「データをチャンク化して条件に合致するXMLと一緒にZIPファイルに入れる」、「まとめられたZIPファイルの大きさを1GB以下にする」ためのポスト処理も必要です。
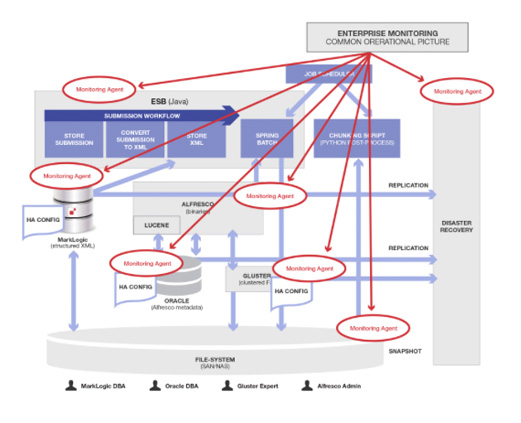
しかしこれだけではありません。Pythonによる外部のチャンク化スクリプトの実行前に、最初のSpring Batch処理が終わっていなければなりません。このためこれら2つをジョブスケジューラに接続する必要がありました(彼らはエンタープライズ用ジョブコントロール製品を使いましたが、cronジョブでも同じことができます)。全体のアーキテクチャにこれらのコンポーネントが追加された状態は以下のようになります(新規アイテムを赤で囲んであります)。

だいぶ複雑になってきました。当初このソリューションに盛り上がっていたお客様の気持ちもこの辺でだいぶ萎えてきました。
物理的アーキテクチャについて
Alfrescoは2つの異なるデータストアを使いますが、これらの間のトランザクション(一貫性)を管理しません。他のサブシステムとのXAトランザクションはそれ以上に管理しましせん。ここには簿記データ用のリレーショナルデータベースと実際のバイナリ用のファイルシステムがあります(BLOBをうまく扱えなかったため)。ファイルシステムを信頼できるようにするため、GlusterFSのようなクラスタ化された高可用性のシステムが必要でした。Alfresco内部には、個別のコンポーネントが多数バンドルされています。コア部分にはリレーショナルデータベースのアダプタが継ぎはぎされ、テキストインデックス用のLuceneが内部的にビルトされています。またファイルシステムに直接アクセスできるようになっています。Alfrescoに付随する物理的およびソフトウェアのコンポーネントで更新した図は、以下のようになります。
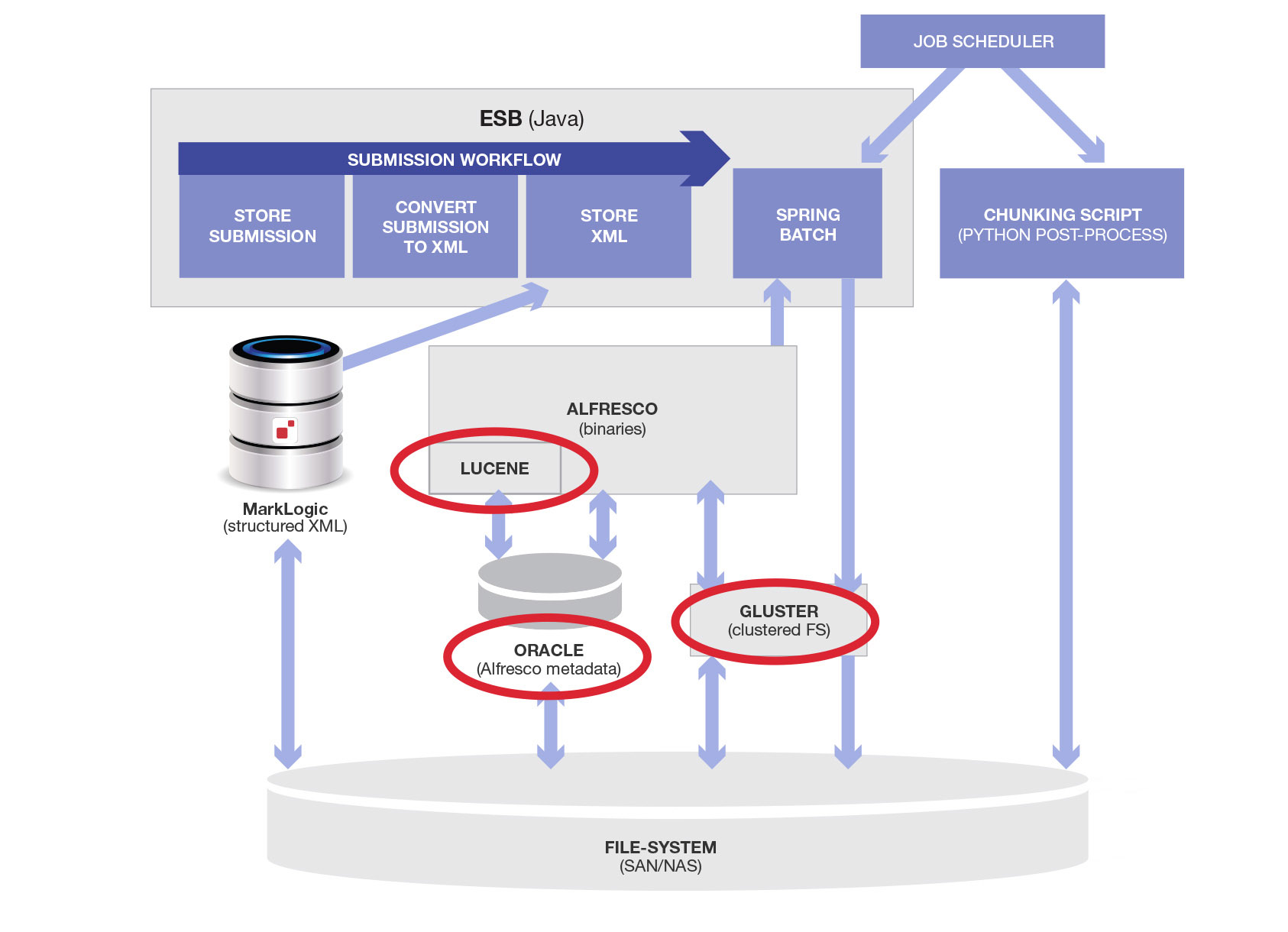
そもそも「そんなに複雑じゃないもの」を作るのが今回の目的でした。「バイナリと構造化データを入力して格納し、検証用の下流システムに渡す」だけだったはずです。
運用
エンタープライズソフトウェア担当者なら分かると思いますが、インフラ内のこういったコンポーネントごとに、運用担当者およびプロセスが必要です。これに加えて、今回は高可用性(HA)および災害対応(DR)の要件もありました。
災害対応
災害対応(DR)とは、「すべてを2つ」持ち、災対サイト内の複製インフラにすべてのデータを常に移動できるようにしておくことです。 MarkLogicはシステム全体におけるプライマリデータベースで、またレプリケート(複製)もされていました。ここでAlfresco用のコンポーネント(Oracle、Alfresco、GlusterFS)が追加されたため、DRサイトに常にこれらのデータのコピーを持つよう設定する必要がでてきました。
複数データストアのDRは可能?
さらに悪いことに、データ同期方法の議論にかなりの時間がかかってしまいました。サブシステムごとにレプリケートの方法が異なり、タイムラグが異なり、レプリケートされないデータの「RPO(目標復旧時点)」も異なっています。災害が発生した場合、DRサイト内のこれらのデータに数秒から数分の同期のずれが発生してしまいます。これに対応するための設計やガバナンスに関して、私たちは驚くほど多くの時間を費やしました。この時間は大きな機会損失です。他のことに使った方が良かった時間を、複数の永続化データストア間のデータレプリケーション管理の議論に使わなければならなかったのですから。
高可用性
高可用性(HA)に関しては、主要コンポーネント(Alfresco Oracle/Luceneデータ、Alfrescoバイナリデータ、MarkLogicデータ)ごとに個別の戦略が必要でした。
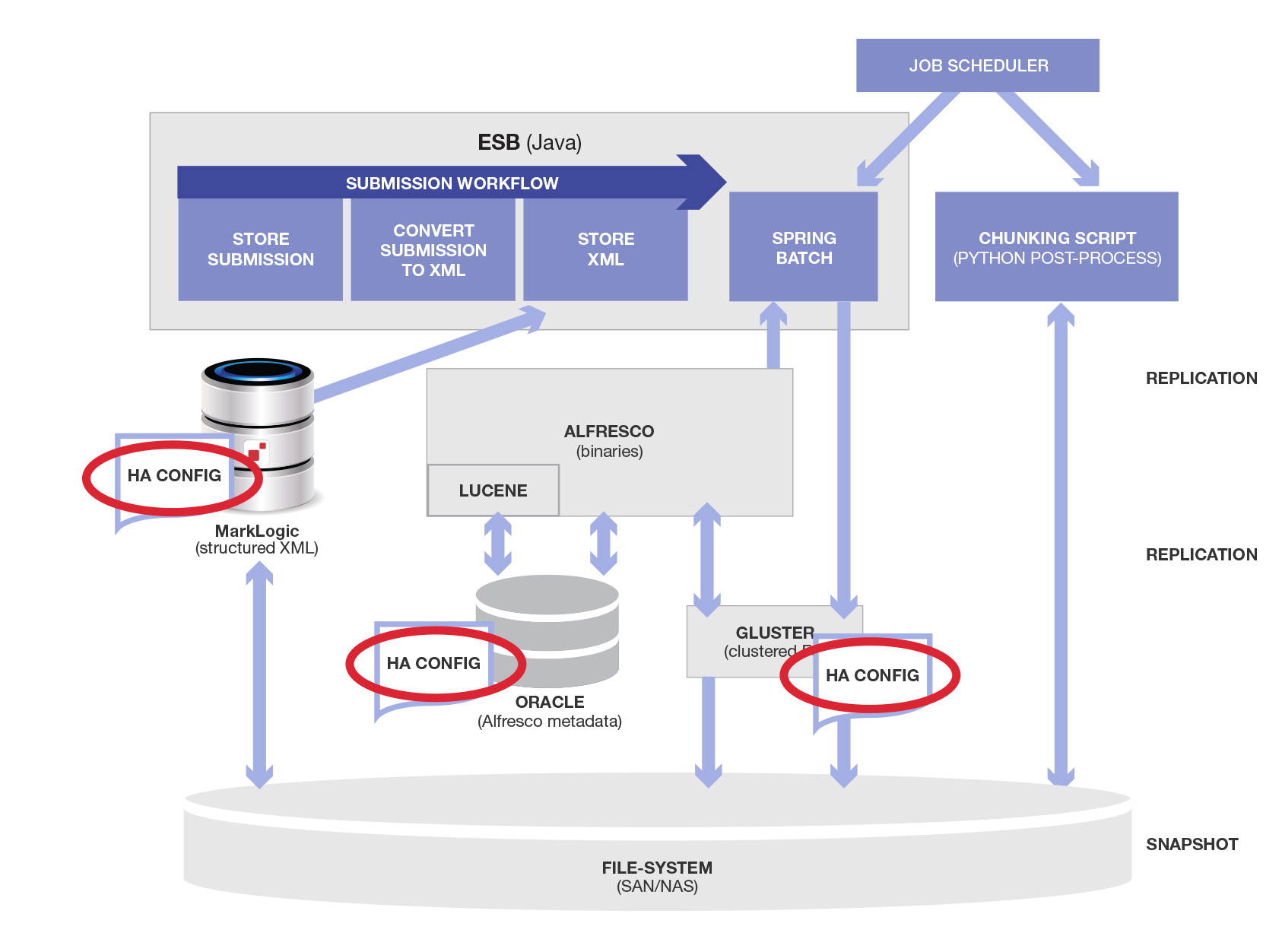
この図内の「HA Config」は想定以上に大変でした。全く同じインフラを準備してプロビジョニングし、使用中の(実際には不必要な)永続化技術ごとに設定する必要があったからです。それぞれ、会議、ベンダーとの打ち合わせ、設計、承認が必要でした。それにテストもありました(それぞれのHAフェイルオーバーをテストする必要がありました)。
プロセス
これらの1つ1つにおいて、トレーニングを受けたスタッフ、プロビジョニング済みハードウェア、ランブック(通常時/非常時の作業指示書)、テスト計画、アップグレード計画、ベンダー/専門コンサルタント、サポート契約が必要です。
災害対応サイトおよび管理・設定が必要なデータフローを表した図は、以下のようになります。新しいデータフローが赤い矢印で、また新しい担当者/役割が赤い丸で示されています。
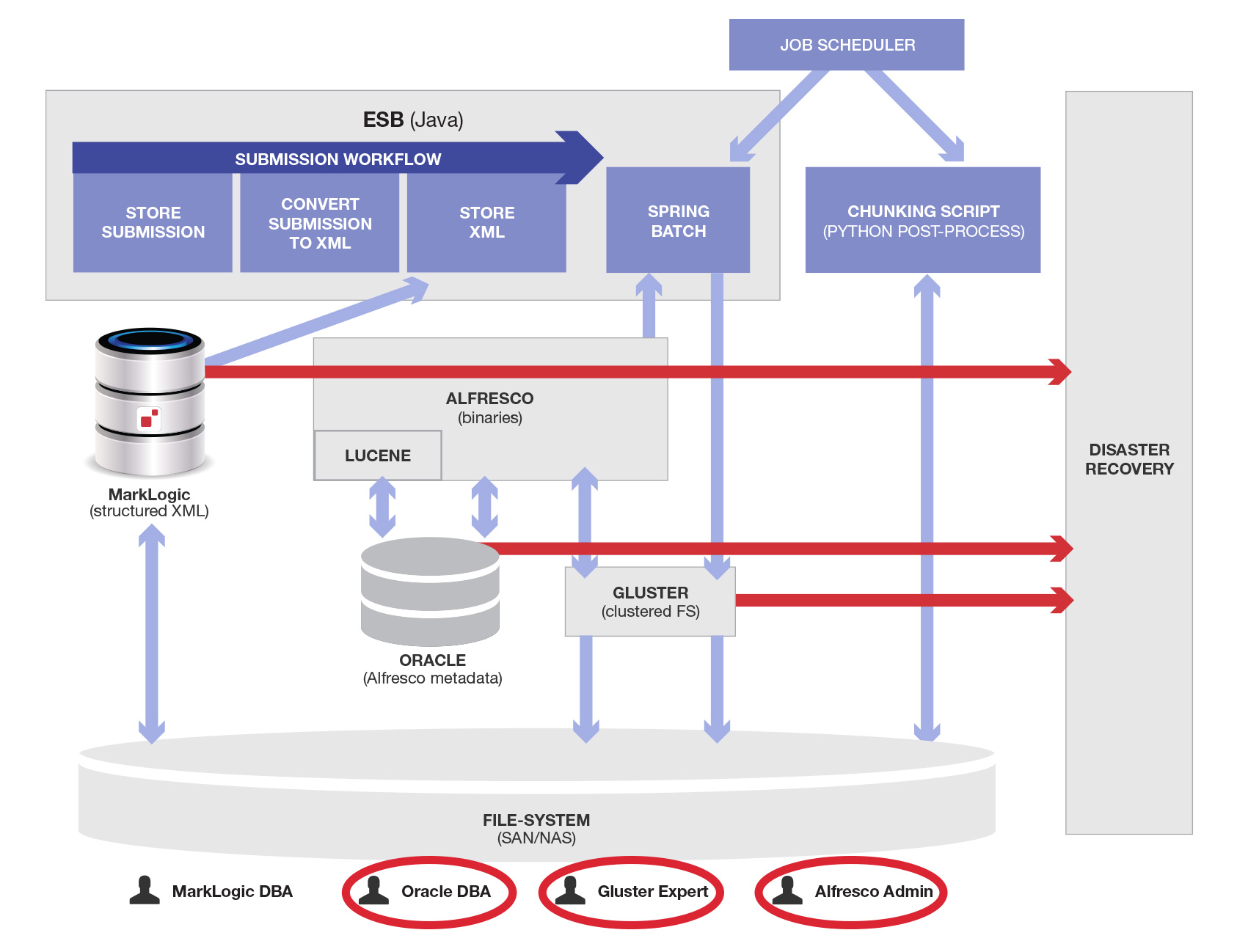
かなり大変ですね。必要な人/プロセス/インフラ/アーキテクチャコンポーネントは、通常こういった図には載せません。というのも複雑すぎてよくわからなくなってしまうからです。
これはさらに悪化していきます。
モニタリング
私は、他のプロジェクト「HealthCare.gov」(通称オバマケア)の安定化と改善にも何か月か関わりました。あまり良くない状態のまま本番稼働が始まり、パフォーマンスが悪く障害が多数発生した際に、ホワイトハウスは対策チームを派遣して問題を解決しようとしました。このチームはまず、全てのレベルの全てのコンポーネント用にモニタリングを購入しインストールしました。システムの状態を把握できなければ、重要なエンタープライズシステムを効果的に稼働できません。経験豊かな運用エンジニアである彼らは、モニタリングを最優先させたのです。
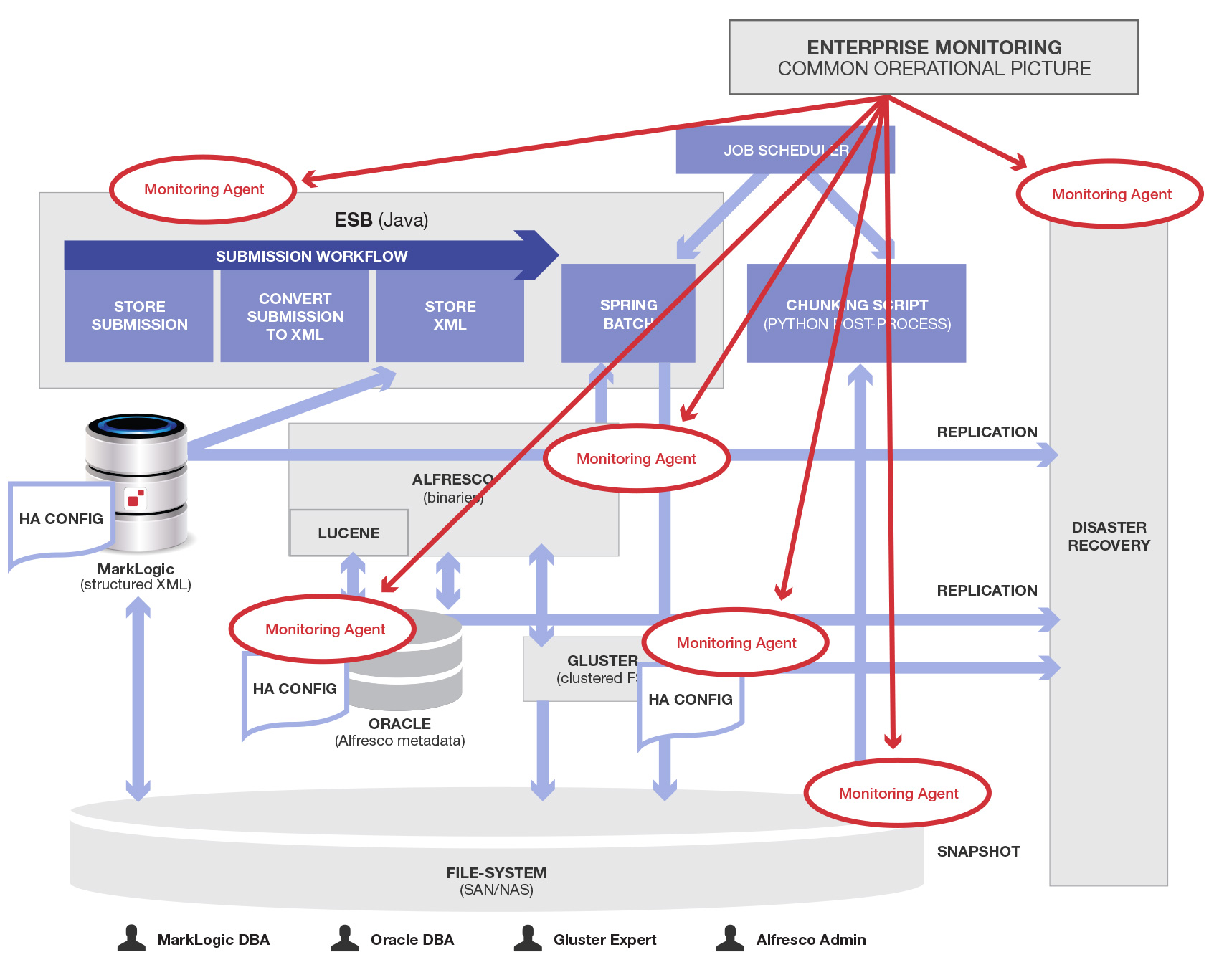
今回の不動産ローン処理アプリケーションでも、モニタリングが必要です。残念ながら、データが複数のシステムに分割されているために、モニタリング対象のサブシステムは多くなります。図で示されたような製品には、統合モニタリングツールへ内部モニタリングや統計情報/ログを提供するAPIが備わっていることが多いです。運用状態を包括的に把握するには、それぞれのモニタリングが必要です。
これまで同様に、追加されたモニタリングエージェントを赤い丸で囲んでいます。ちゃんと動かすためには、これらを開発/保守/統合する必要がありますが、そもそもこれらはなくて済んだはずのものです。ここでは、エンタープライズモニタリング製品とMarkLogicは丸で囲んでいません。というのも、MarkLogicに全データを格納した場合(本来のあるべき姿)でも、これらは必要だからです。
デプロイ/DevOps/自動化
各コンポーネントごとに、デプロイ/バージョン管理/テストが必要です。コーディングやカスタマイズがされている場合、それらのコードもビルドに統合する必要があります。経験豊かな皆さんならご存知でしょうが、maven/ant/gulpのようなシステムを使ってすべてのコンポーネントを統合し、一般的なテスト可能かつ適切に設定されているものを作り出す作業はかなり複雑です。これらが複雑なのは、含まれるコンポーネントが多いからでもあります。
ここで、継続的な統合/デプロイに対応できる機能を備えたものを開発・保守しなければならないDevOps担当者の写真を紹介しておきましょう。

私たちの失敗を繰り返さないために
というわけで、ここまで「シンプルな要件だったはずなのに運用が悪夢のようになってしまう」事例について長々とかつ詳細に話してきました。この話を読んだことで、皆さんが何か月(あるいは何年)も苦労しないで済むようになれば幸いです。
上の図のすべて(「すべて」です)が、シンプルな申し込み/レビュー/エクスポートのタスクを、しっかりとしたHA/DR環境を備えたシステムで実現するうえで必要なのです。これらはすべて不動産ローン申し込み処理に関して、以下のようなシンプルかつナイーブそして危険な考えを抱いたことから始まっているのです。
「このExcelやPDFはAlfrescoに入れましょう。それからXMLはMarkLogicに入れましょう。こうすれば、各データタイプにとってベストなシステムを使うことになるのですから」
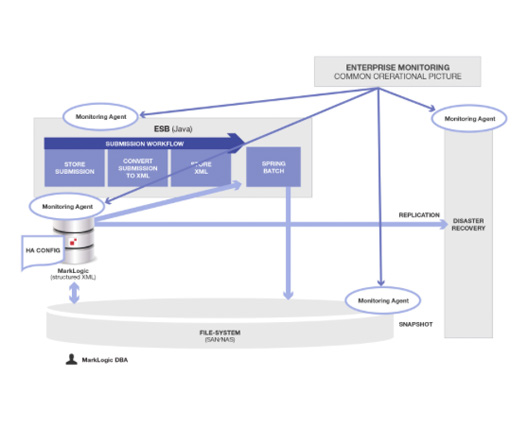
それではAlfrescoをやめて、すべてのデータをMarkLogicに入れた場合(本来そうすべきであったやり方の場合)、どうなるか見てみましょう。
このようにシンプルにすることで、すべてが解決するわけではありません。エンタープライズシステムの運用は本来的に複雑であり、その複雑さのいくつかは根源的なものです。とはいえ今回のプロジェクトにおいては、MarkLogicでさまざまなデータタイプ(この例ではバイナリとXML)を統合・管理する、このようなものを最初から開発・保守すべきでした。
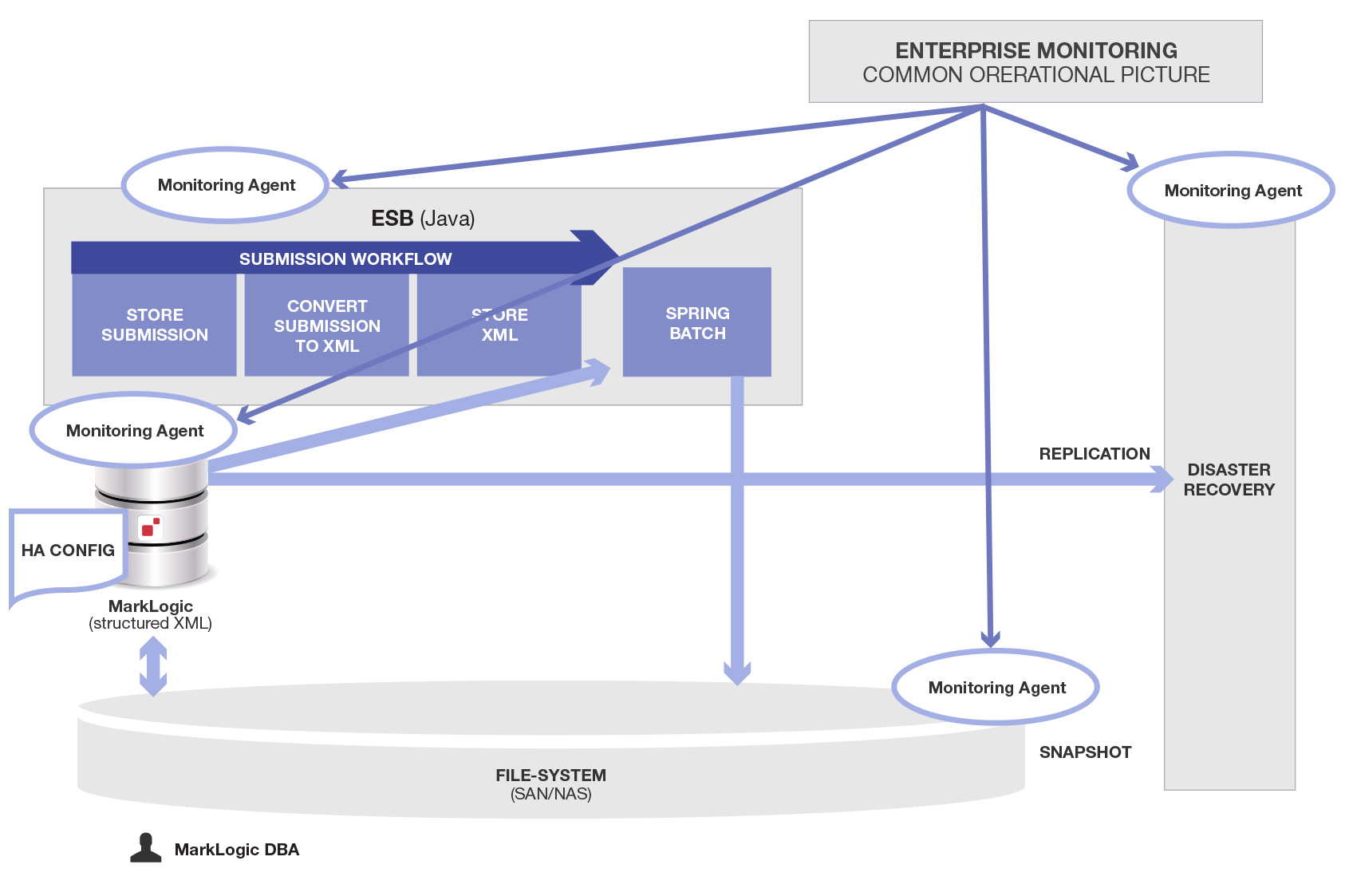
ご覧のようにコンポーネントの数が減ったことで、全体的にシンプルになり作業量も大幅に削減されます。これは別に驚くことでもなく、「ソフトウェア統合における原則」です。
「ソフトウェア統合プロジェクトの複雑さは、統合対象のコンポーネントの数によって大きく変わる」
この図が大幅にシンプルになったのは、余計なデータストア(この例ではAlfresco)をやめることで、付随する統合/コーディネーション/デプロイ/モニタリング/設定/保守コンポーネントがすべて不要になったからです。
正しい答え
MarkLogicは、数多くのデータタイプ(XML、バイナリ、RDF、テキスト、JSON)を扱えるように作られています。MarkLogicをマルチモデル用統合データストアとして使用し、一か所ですべてのデータを管理することで、このシステムはだいぶシンプルになります(上記参照)。
一部のデータをあるデータストア(MarkLogic)に、他のデータを別のデータストア(Alfresco)に入れた場合、システムはかなり複雑になります。当初はその後このように複雑になることを予見できませんでしたが、今から考えるとこんなふうになるのは当然のことです。
まとめ
以下のようになります。
元々やりたかったこと
最初に構築したもの
MarkLogicで作ったもの
MarkLogic社のソフトウェア開発哲学は極めて珍しいものです。C++のコア1つだけで、一か所でデータ管理問題を解決します。その際テキスト、RDF、XML、バイナリといったさまざまなデータタイプを扱います。競合他社の多くは、オープンソースや購入した別個のコンポーネントを裏で合体させた「ソリューション」を提供しています。この場合、複雑さは減るのではなく隠されているだけで、逆に増えています。
言い換えれば、MarkLogicデータベースは「ポリグロットパーシステンス」をマルチモデルストレージの技術によって実現しているのです。MarkLogicを使えば、さまざまな問題に悩まされることなく「ポリグロットパーシステンス」を達成できます。
しかし上記の「哲学」は抽象的であるため、実装を実際に経験してみないとその重要性は理解しにくいかもしれません。今回の例は実話に基づいており、実際には不動産ローン用ではありませんでしたが、統合およびその影響の度合いはすべて本当です。しかし私が経験した苛立ちを皆さんは回避できるでしょう。それ以上に、そもそも起こる必要がなかった無数の統合問題に煩わされることなく、ユーザーや顧客に価値を提供できることでしょう。

