
先日のMarkLogic World Tokyoにおいて、デモを行ったときに使用したUIアプリケーション作成のツールがGroveです。
今回はそのGroveに関するBlogのページの一部と、実際に皆さんが作成されたデータベースを検索するところまでを紹介します。
<参考> ※英語
https://www.marklogic.com/blog/building-ui-applications-using-grove/
https://marklogic-community.github.io/grove/
MarkLogicで何かを構築したい場合、データに対する操作とともに、そのデータをどのように見たいかということも事前に必要な情報です。
もちろんどのように見たいかは継続的に変化していくものですが、まずはデータを見るということも重要です。
Groveプロジェクトとは
MarkLogicのGroveプロジェクトは、MarkLogic上にUIアプリケーションを構築するために必要なツール、テンプレート等の関連リソースをすべて含んだツールキットです。
構成としてはミドルティアとして、Node.jsまたはJava Spring Boot、UIティアはReactまたはVue.jsを選択できるようになっています。
ReactやVue,jsのコンポーネントを使用できることから拡張性も保持しています。
MarkLogicがPoCやデモでアプリケーションを作成する際には、ほとんどの場合このGroveを使用してUIアプリケーションを作っています。
以下ではGroveを使用してデータベースを検索するまでをGetting Startedの情報をもとに紹介します。
これ以降のカスタマイズについては、次回以降に紹介していきたいと思います。
Grove設定の流れ
Groveのデフォルト画面は以下のようなものです。(図1)
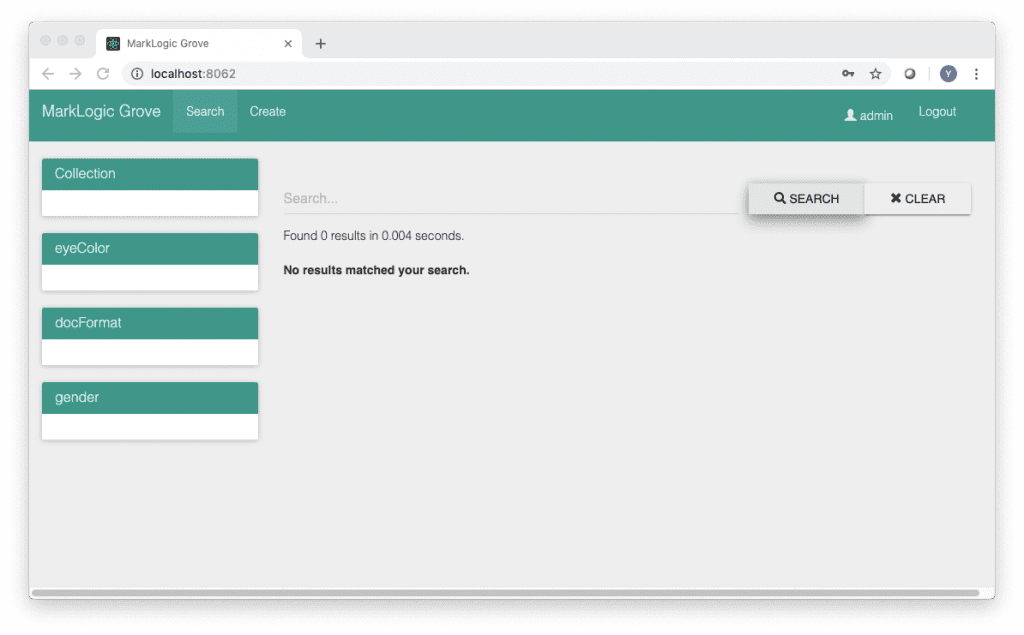
検索のためのテキストボックスと検索ボタン、左側にファセットが表示され、該当するデータがカード形式またはリスト形式で表示されます。
このような典型的な検索アプリケーションを作成し、これにReactまたはVueを使用したカスタマイズを行いながらデータを可視化していくことが可能です。
参考資料のGetting Startedに沿って説明していきます。
まず必要なのは以下のものです。
- MarkLogic:9.0以降
- Node.js: 8.10.0 以降
- npm: 5.7.0
- Git:
- Java: 1.8 以降
次にgroveをインストールします。
| $ npm install -g @marklogic-community/grove-cli |
次にgrove new でGroveのプロジェクトを作成します。
$ grove new project1 |
ここで使用したプロジェクト名でデータベースやRESTのサーバが作成され、Groveアプリケーションはこれらのデータベースやアプリケーションサーバを使用します。(変更方法は後述)
プロジェクトのディレクトリもこの名前で作成されます。
プロジェクトフォルダーに移り、Groveアプリケーションを構築します。
$ cd project1$ grove config? What host is your instance of MarkLogic running on? localhost ? What port do you want to use for your MarkLogic REST server? 8030 ? What port do you want your Grove Node server to listen on? 8031 |
grove configでは、Groveアプリケーションが使用するMarkLogicの場所(localhost)とRESTポート(8030)とミドルティアであるGrove Nodeサーバのポートを指定します。
ここで設定した内容でMarkLogic上に必要な設定を展開します。(事前にgradle.propertiesの中のmlUsernameとmlPasswordを変更する必要があります。)
$ cd marklogic $ ./gradlew mlDeploy $ cd .. |
これでGroveが使用するアプリケーションやRESTサーバが指定した場所のMarkLogic上に作成されます。
次にGroveを起動しますが、その前にアプリケーションのポートを指定します。(これをしないとポート3000番で起動します)
ui ディレクトリに、.env.developmentというファイルを作成し、次の1行を追加します。PORT=8032
この後、 アプリケーションサーバを起動します。
| $ npm install
$ npm start |
ブラウザでlocalhost:8032を指定すると最初のスクリーンが表示されます。(図2)
ここまでの設定がデフォルトですが、この場合、Groveアプリケーションがアクセスしているデータは、project1というプロジェクト名で指定したデータベースの中にあり、dataというコレクションに属しているものだけです。
接続するデータベースを変更し、コレクションの制約を外し、左側に表示されているファセット群をリセットします。
まずは、データベースを変更する方法ですが、複数の方法がありますが、最も簡単な方法は、アプリケーションサーバproject1の接続データベースをproject1-contentからアクセスしたいデータベースに変更する方法です。
プロジェクトディレクトリにあるmarklogic/ml-config/servers/app-server.jsonを編集し、content-databaseを変更します。
例としてdata-hub-FINALデータベースに変更したい場合には、次のように記述します。
“content-database” : “data-hub-FINAL”,
次に制約を外すために、プロジェクトディレクトリにあるmarklogic/ml-modules/options/all.xmlを編集します。
検索に関する設定はこのファイルの中で多くのことが行えるようになっています。
dataコレクションのみを対象としている制約を外すために
<additional-query>…</additional-query>
を消去もしくはコメントアウトします。(XMLのコメントは<!—と–>で囲みます。)
次にeyeColorなどの不要なファセットと制約を外します。
以下の要素を消去もしくはコメントアウトします。
<state name=”eyeColorAsc”>…</state>
<state name=”eyeColorDsc”>…</state>
<constraint name=”eyeColor”>…</constraint>
<constraint name=”docFormat”>…</constraint>
<constraint name=”gender”>…</constraint>
これらの変更を行った後に、再度marklogicディレクトリに戻り、gradleでmlDeployタスクを実行してMarkLogicへ反映させます。
$ cd marklogic $ ./gradlew mlDeploy |
ここでは、GroveアプリケーションのGetting Startedを紹介しました。
この後のカスタマイズには、検索結果の表示であったり、詳細ページの表示、その他ReactやVUEを使った様々なカスタマイズが可能です。
また、MarkLogic上のRESTサービスをセキュリティを担保して呼び出すことも容易です。
また機会がありましたら、グラフ等の可視化のためのカスタマイズも紹介できたらと思います。

