Cognos Business Analytics connectivity to Hadoop Hive just got bigger
In my role as DataDirect Systems Engineer + IBM Certified Cognos Developer, I have been integrating data for IBM Cognos shops ranging from relational data sources on premise to SaaS data sources in the cloud; and next up: "Big Data". IBM's Apache Hadoop solution, InfoSphere BigInsights, integrates nicely with IBM Cognos 10.2 using DQM. However, my most recent engagements include shops requiring ODBC connectivity or those who have adopted other Hadoop distributions such as Cloudera, Hortonworks, Map/R, Apache, Amazon EMR, Pivotal, etc.
IBM Cognos Ecosystem meets the Hadoop Ecosystem
With DataDirect XE Hadoop Big Data Connectors, IBM Cognos shops have a full range of connectivity options for Hadoop Hive across Windows, AIX, Linux, Solaris, and HP-UX:
| Recommended Connector from DataDirect | |
|---|---|
| IBM Cognos TM1 9.5.x, 10.x | 64-bit Connect64 XE for ODBC Hadoop Hive: AIX,Linux,Solaris,HP-UX and Windows |
| IBM Cognos Transformer 8.x, 10.x | 32-bit Connect for ODBC Hadoop Hive: AIX,Linux,Solaris,HP-UX and Windows |
| IBM Cognos Data Manager 8.x, 10.x | 32-bit Connect for ODBC Hadoop Hive: AIX,Linux,Solaris,HP-UX and Windows |
| IBM Cognos BI Compatible Query Mode (CQM) 8.x, 10.x | 32-bit Connect for ODBC Hadoop Hive: AIX,Linux,Solaris,HP-UX and Windows |
| IBM Cognos BI Dynamic Query Mode (DQM) 10.2 | Connect for JDBC Hadoop Hive driver (preview): Java |
Tutorial for integrating Cloudera 4.1 Hive2 with Cognos BI 10.1
1- Download a trial of the DataDirect Connect XE for ODBC Cloudera driver.
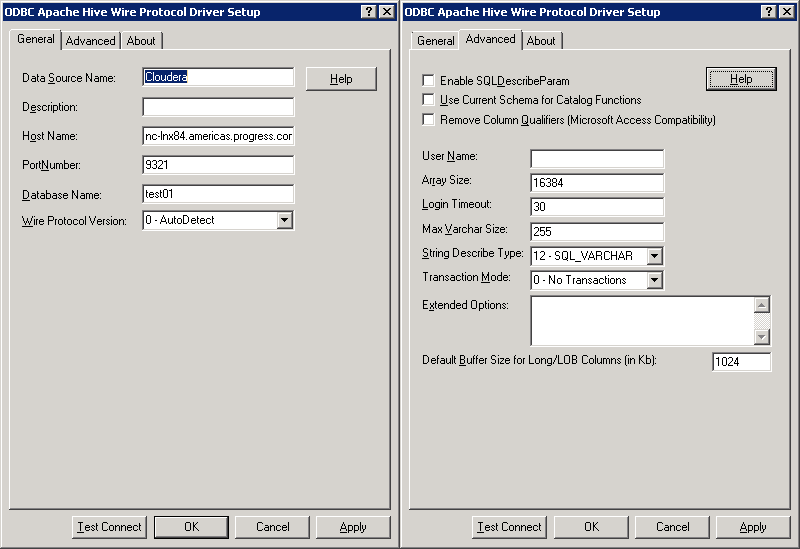
2- Configure ODBC data source to Cloudera 4.1. On Advanced tab, set Max Varchar Size to be 255 since my character data does not include long strings.
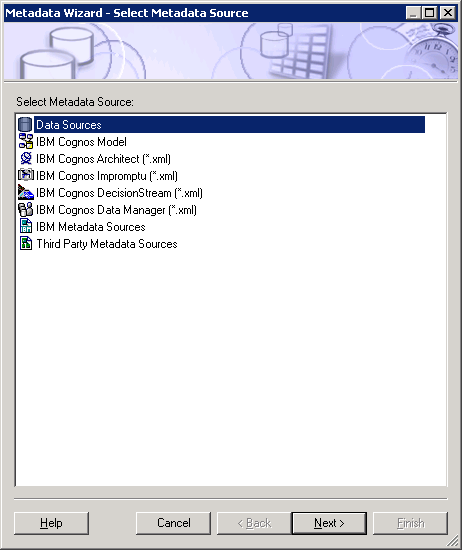
3. Launch Framework Manager and select Data Sources for the metadata model
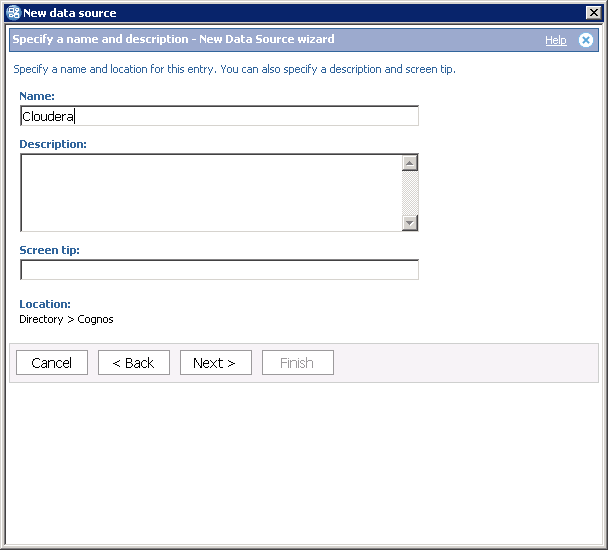
4. Create new data source matching the name in step #1.
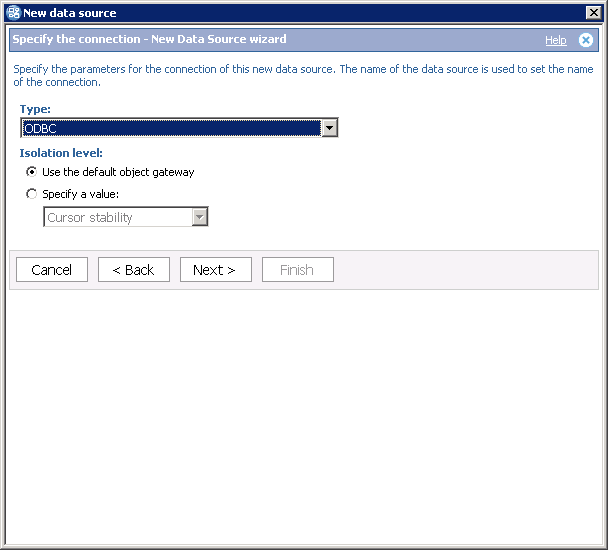
5. Select data source type "ODBC"
6. Navigate to the data source and select objects directly from Cloudera to import
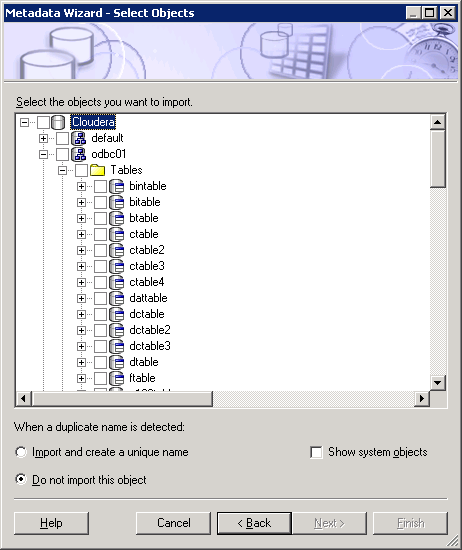
7. Publish the package and launch Report Studio to run a simple list report
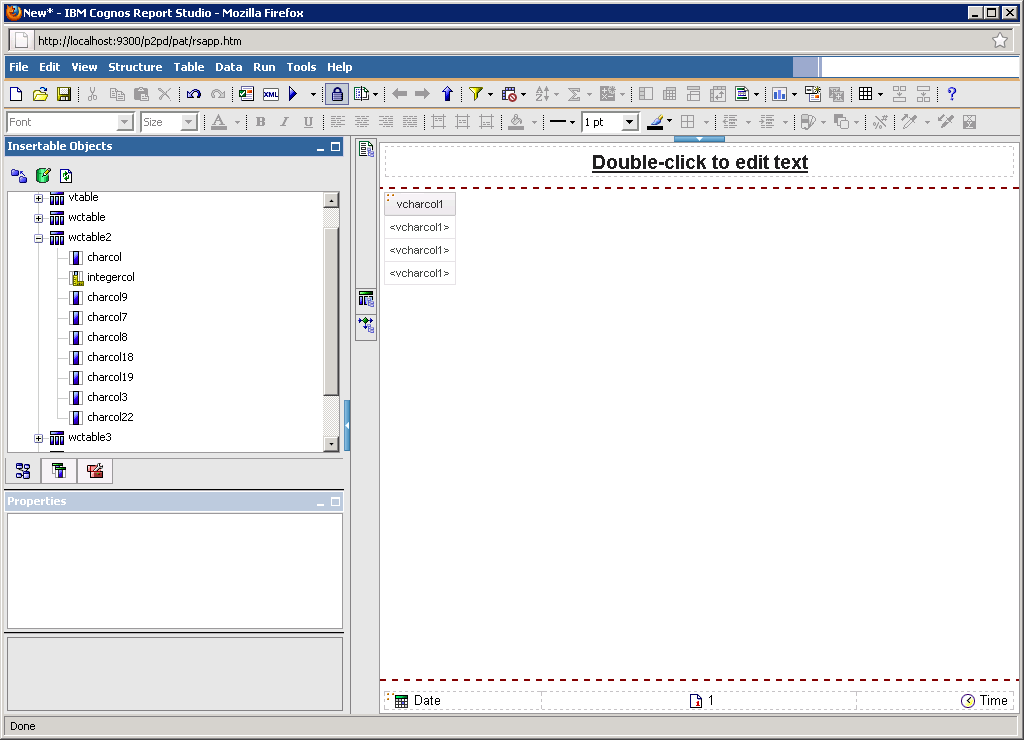
8. Run the report to fetch data directly from Cloudera Distribution. Dummy data returned below is from one of our QA tables, but you can pretend it is something of big data significance like input from web forms.
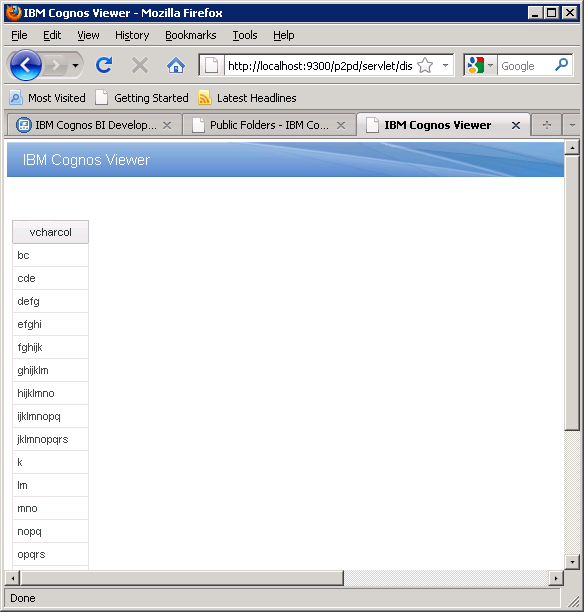
Cognos shops have been really excited about having reliable connectivity into their big data infrastructure.
How about DQM?
Check back on the blog for the next IBM Cognos tutorial for our JDBC connectors to Hadoop Hive.
What else does the world wide leader in data connectivity know about Big Data?
Call us at N. America: (800)876-3101 | World: +44 (0) 1-344-386-367 to learn more about the latest big data access technologies and our project experience.

Sumit Sarkar
Technology researcher, thought leader and speaker working to enable enterprises to rapidly adopt new technologies that are adaptive, connected and cognitive. Sumit has been working in the data access infrastructure field for over 10 years servicing web/mobile developers, data engineers and data scientists. His primary areas of focus include cross platform app development, serverless architectures, and hybrid enterprise data management that supports open standards such as ODBC, JDBC, ADO.NET, GraphQL, OData/REST. He has presented dozens of technology sessions at conferences such as Dreamforce, Oracle OpenWorld, Strata Hadoop World, API World, Microstrategy World, MongoDB World, etc.
Comments
Topics
- Application Development
- Mobility
- Digital Experience
- Company and Community
- Data Platform
- Secure File Transfer
- Infrastructure Management
Sitefinity Training and Certification Now Available.
Let our experts teach you how to use Sitefinity's best-in-class features to deliver compelling digital experiences.
Learn MoreMore From Progress



Latest Stories
in Your Inbox
Subscribe to get all the news, info and tutorials you need to build better business apps and sites